




原文鏈接:https://www.cnblogs.com/fydeblog/p/7364317.html
前言
這篇notebook是關於機器學習中logistic迴歸,內容包括基於logistic迴歸和sigmoid分類,基於最優化方法的最佳係數確定,從疝氣病症預測病馬的死亡率。
操作系統:ubuntu14.04 運行環境:anaconda-python2.7-jupyter notebook 參考書籍:機器學習實戰和源碼 notebook writer ----方陽
注意事項:在這裏說一句,默認環境python2.7的notebook,用python3.6的會出問題,還有我的目錄可能跟你們的不一樣,你們自己跑的時候記得改目錄,我會把notebook和代碼以及數據集放到結尾的百度雲盤,方便你們下載!
1. 基於logistic迴歸和sigmoid函數的分類
首先說說sigmoid函數吧。
它的表達式是 g(z) = 1/(1+exp(-x)) ,爲直觀看出,我們畫畫這個函數的曲線。
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5,5,200)
y = 1./(1+np.exp(-x))
plt.figure()
plt.plot(x,y)
plt.xlabel('x')
plt.ylabel('sigmiod(x)')
plt.show()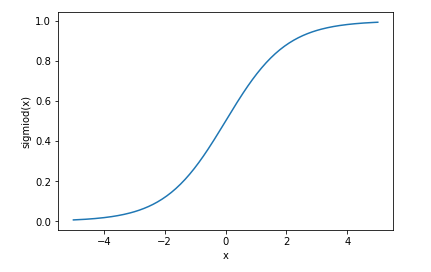 ![1]()
![1]()
上面就是sigmiod函數的圖形,那麼我們怎麼用sigmiod函數進行邏輯迴歸判決呢?
首先觀察函數圖形,sigmiod函數的y軸被限制在區間(0,1)上,這有利於我們判決,將線性的無窮範圍壓縮到這個小範圍,當x=0的時候,sigmiod(0) = 0.5, 於是我們就將0.5當作界限,特徵值乘以一個迴歸係數,然後結果相加,代入到這個sigmiod函數當中,將函數值大於0.5分爲1類,小於0.5的分爲0類,至此,logistic分類完成。
2. 基於最優化方法的最佳迴歸係數確定
這裏說一下,sigmiod函數是爲了幫助我們來判斷分類類別,然後與真實類別相比較,算出誤差,然後用梯度上升最小化誤差,得到最佳係數。
sigmiod函數的輸入記爲z,公式:z = w0x0+w1x1+w2x2+...+wnxn (這裏0,1,2,...,n都代表下標係數),簡單寫就是 z = wTx (T代表轉置)
2.1 梯度上升法
梯度上升法的思想:要找到某函數的最大值 ,最好的方法是沿着該函數的梯度方向探尋。
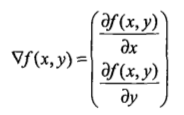 ![2]()
![2]()
這是函數f(x,y)的梯度表達式,當要沿x方向移動時,就是對x求偏導;當要沿y方向移動時,就是對y求偏導。其中,函數f(x,y)必須要在待計算的點上可微。
梯度上升算法的迭代公式:w := w+a dw(f(w)) (dw是關於係數w的梯度,a是學習率)
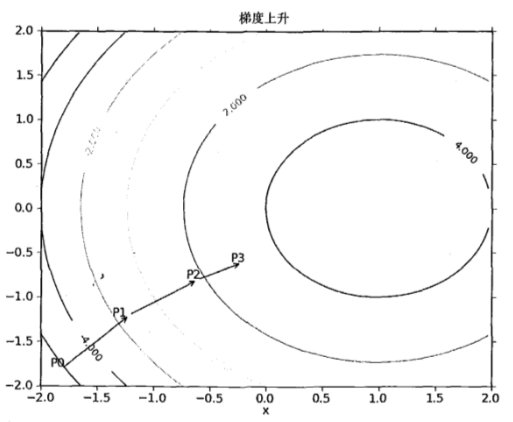
梯度上升法的具體上升過程,如圖所示
 ![3]()
![3]()
該公式將一直被迭代執行,直至達到某個停止條件爲止,比如迭代次數達到某個指定值或算法達到某個可以允許的誤差範圍。
梯度上升算法與梯度下降算法的區別:就是梯度上升的學習率前面的加號變爲減號就是梯度下降算法
2.2 訓練算法 :使用梯度上升找到最佳參數
梯度上升法的僞代碼如下:
每個迴歸係數初始化爲1
重複R次:
計算整個數據集的梯度
使用alpha X gradient更新迴歸係數
返回迴歸係數
下面進入梯度上升法的具體實現下面進入梯度上升法的具體實現
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #convert to NumPy matrix
labelMat = mat(classLabels).transpose() #convert to NumPy matrix
m,n = shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles): #heavy on matrix operations
h = sigmoid(dataMatrix*weights) #matrix mult
error = (labelMat - h) #vector subtraction
weights = weights + alpha * dataMatrix.transpose()* error #matrix mult
return weights第一個函數loadDataSet函數就是導入數據集,並進行封裝,將特徵值封裝成三列的多維列表dataMat,label放在labelMat裏面
第二個函數不用多說,就是sigmiod函數
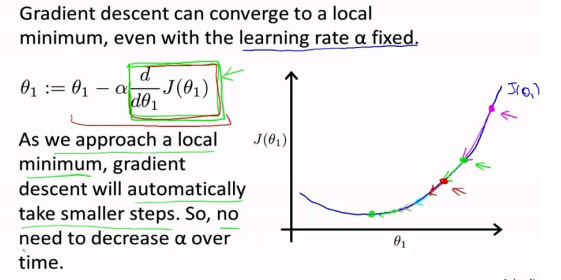
第三個函數就是梯度上升的具體算法,dataMatIn就是上面的多維列表dataMat,classlabels就是labelMat,函數首先將輸入的數據集和標籤全部轉化成的numpy矩陣,是爲了能夠進行矩陣運算和向量運算,maxCycles代表迭代的最大次數,至於參數的迭代還可以看看以下圖片,我選的是吳恩達的ppt上,這寫的是梯度下降的迭代過程(梯度上升就是反過來,原理一樣),可見損失函數的梯度會有逐漸趨於0,這樣迭代公式的梯度那項也會趨於0,參數不會有太大的浮動,趨於穩定,誤差最小。
 ![4]()
![4]()
測試一下吧
cd 桌面/machinelearninginaction/Ch05
/home/fangyang/桌面/machinelearninginaction/Ch05import logRegresdataMat , labelMat = logRegres.loadDataSet()logRegres.gradAscent(dataMat,labelMat)
 ![5]()
![5]()
2.3 分析數據:畫出決策邊界
我們得到了最佳係數,便於理解,我們要畫出分隔線,便於我們觀察
代碼如下:
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()這個函數先是調用loadDataSet函數將數據集和標籤賦給dataMat,labelMat,然後對不同類別進行不同的分組,類別1的數據放在xcord1和ycord1,類別2的數據放在xcord2和ycord2,然後分別顯示,最後畫出輸入的權重對應的分隔線,y的求解你可能有疑問,這裏說一下,具體表達式是wTx=0,wT是輸入權重,x=[x0,x1,x2],其中x0爲了方便表示所建立的,值爲1,x1就是上述函數的x,x2就是y,這下你就知道爲什麼是那個表達式了吧。
from numpy import *weights = logRegres.gradAscent(dataMat,labelMat)logRegres.plotBestFit(weights.getA()) # the function of getA is used to transform matrix into array
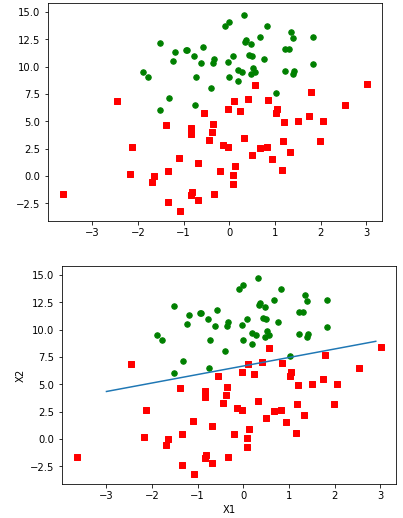 ![6]()
![6]()
可以看出圖中只錯分了兩到四個點,效果不錯。
2.4 訓練算法:隨機梯度上升
梯度上升算法在每次更新迴歸係數時都需要遍歷整個數據集,當特徵的數目非常多的時候,計算量會非常巨大。
一種改進方法是一次僅用一個樣本點來更新迴歸係數, 該方法稱爲隨機梯度上升算法。
由於可以在新樣本到來時對分類器進行增量式更新,因而隨機梯度上升算法是一個在線學習算法。與在線學習相對應 ,一次處理所有數據被稱作是 “批處理” 。
隨機梯度上升算法的僞代碼如下
所有迴歸係數初始化爲 1
對數據集中每個樣本
計算該樣本的梯度
使用 alpha x gradient更新迴歸係數值
返回迴歸係數值代碼如下:
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights可以看到 ,隨機梯度上升算法與梯度上升算法在代碼上很相似,但也有一些區別:
第一 ,後者的變量h和誤差error都是向量 ,而前者則全是數值;
第二 ,前者沒有矩陣的轉換過程,所有變量的數據類型都是NumPy數組。
這是因爲梯度上升算法是遍歷所有數據,形成的是所有數據的向量,而隨機梯度上升算法每次只用一個樣本,所以是單一數值。其他類似
來測試一下效果吧
weights = logRegres.stocGradAscent0(array(dataMat),labelMat)logRegres.plotBestFit(weights)
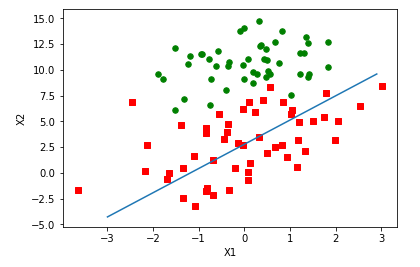 ![7]()
![7]()
可見擬合的直線不完美,錯分了三分之一的樣本,直接比較結果是不公平的,梯度上升算法是在整個數據集中迭代了500次,而隨機梯度算法只在整個數據集中迭代了1次,計算量相差很多倍。所以這裏還需對隨機梯度上升算法進行優化,代碼如下
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights這裏主要改了兩點:
第一點增加了alpha動態減少的機制,這樣做的原因是爲了保證在多次迭代之後新數據仍然具有一定的影響。
第二點是通過隨機選取樣本來更新迴歸係數,這種方法減少週期性的波動。每次隨機從列表中選出一個值,然後從列表中刪掉該值,重新迭代
需要注意的是:
如果要處理的問題是動態變化的,那麼可以適當加大上述常數項,來確保新的值獲得更大的迴歸係數。
再次運行出來看看
weights = logRegres.stocGradAscent1(array(dataMat),labelMat)logRegres.plotBestFit(weights)
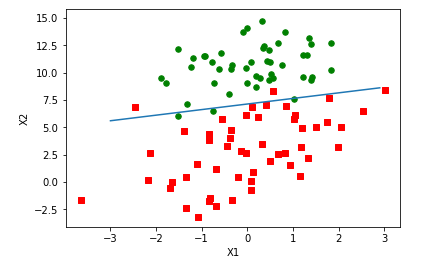 ![8]()
![8]()
可見分類效果與梯度上升算法差不多,比較一下計算量,梯度上升算法迭代了500次的整個數據集,而隨機梯度上升算法迭代了150次就達到類似的效果。
3. 示例:從疝氣病症預測病馬的死亡率
這個例子是通過馬疝病的一些指標,使用logistic迴歸和隨機梯度上升算法來預測病馬的生死。
3.1 準備數據:處理數據中的缺失值
馬疝病的數據集中有30%的值是缺失的,我們怎樣來解決這個問題呢?
首先我們要知道,有時候數據是非常昂貴的,扔掉缺失數據和重新獲取新的數據都是不可取的,所以我們採用一些方法來解決這個問題,方法如下:
下面給出了一些可選的做法:
- 使用可用特徵的均值來填補缺失值;
- 使用特殊值來補缺失值,如 -1;
- 忽略有缺失值的樣本;
- 使用相似樣本的均值添補缺失值;
- 使用另外的機器學習算法預測缺失值。
預處理階段的兩件事:
第一件事,所有的缺失值必須用一個實數值來替換,因爲我們使用的numpy數據類型不允許包含缺失值。
第二件事,如果在測試數據集中發現了一條數據的類別標籤已經缺失,那麼我們的簡單做法是將該條數據丟棄。這是因爲類別標籤與特徵不同,很難確定採用某個合適的值來替換。
這個例子選實數0來替換所有缺失值,不影響特徵係數,如果等於0,對應的參數也被置0,不會更新,還有就是sigmiod(0)=0.5,即對結果的預測不具有任何傾向性,所有用0代替缺失值
3.2 測試算法 :用Logistic迴歸進行分類
使用Logistic迴歸方法進行分類並不需要做很多工作,所需做的只是把測試集上每個特徵向量乘以最優化方法得來的迴歸係數,再將該乘積結果求和,最後輸人到sigmiod函數中即可。如果對應的sigmiod值大於0.5就預測類別標籤爲1 , 否則爲0 。
例子的代碼如下
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
def colicTest():
frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print "the error rate of this test is: %f" % errorRate
return errorRate
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print "after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))第一個函數classifyVector,它以迴歸係數和特徵向量作爲輸入來計算對應的sigmiod值,如果值大於0.5返回1,否則返回0
第二個函數colicTest,先是打開訓練集和測試集,然後使用改善後的隨機梯度上升算法對訓練集進行訓練,得到訓練參數,然後使用這個訓練參數帶入到測試集當中,比較這個測試集使用該參數得到的類別和實際類別,算出錯誤的個數,最終程序是返回錯誤率
第三個函數就是多次使用第二個函數,最後打印出平均錯誤率
logRegres.multiTest()
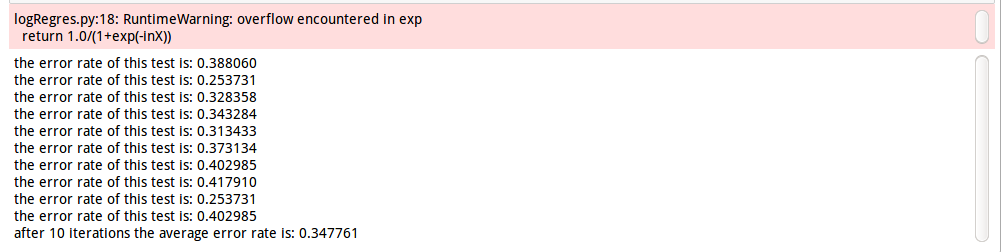 ![9]()
![9]()
平均錯誤率34.7761%,這個錯誤率還好,畢竟我們有30%的數據缺失嘛,作者書上調整迭代次數和步長,可以改善錯誤率,你們可以試一試。
小結
-
logistic迴歸的目的是尋找一個非線性函數sigmiod的最佳擬合參數,求解過程可以由最優化算法來完成。在最優化算法中,最常用的就是梯度上升算法, 而梯度上升算法又可以簡化爲隨機梯度上升算法。
- 隨機梯度上升算法與梯度上升算法的效果相當, 但佔用更少的計算資源。此 外 ,隨機梯度上升是一個在線算法, 它可以在新數據到來時就完成參數更新, 而不需要重新讀取整個數據集來進行批處理運算。