




此文首發於知乎
Talk is cheap, show me the code.
手裏有碼,心中不慌。源碼敬上 ihongs/HongsCORE
按照一篇技術文章的慣例,先得定義名詞、作出解釋:
信息管理系統:信息管理系統_百度百科,往大了說,除了圖書管理、倉儲管理,電商、資訊網站和大部分的 APP 後臺都屬於信息管理系統。但此文並不討論複雜的系統,只淺涉一點點基礎的,也不牽扯到 OLTP/OLAP 之類概念,只討論一個玩笑般的話題:增刪改查。
自動化構建:我認爲全自動的構建方式就是人向機器提出需求,機器直接給出完整方案,過程中機器可能會詢問並等你作出抉擇,但無需程序員干預細節;相對的,半自動化仍然需要人來確定枝枝蔓蔓的細節,但具體的數據流轉邏輯無需編寫代碼。
不過,這不是論文,這不是論文,這不是論文!
從上述定義來說,本文談到的系統只能算"近半自動化",當超脫那些簡單但繁瑣的基礎邏輯後,仍然需要程序員去幹預甚至覆蓋重建。我試圖讓這個系統不是一個秤砣啃不動砸不爛,好讓其可干預、可拆散、可重建。這不會生成邏輯代碼,只會產生結構類代碼,如果需要,可以過濾輸入輸出和覆蓋重寫邏輯,但不存在“修改”邏輯代碼這麼個操作,因爲沒有邏輯程序代碼產生——沒有這個必要。
數據與邏輯並不是天然分隔的,一個程序代碼之所以成爲邏輯指令,只有當被執行的時候才表現出來那些動態的判斷和分支,但當它存儲在硬盤裏,不管裏面寫了多少動詞,是文本還是二進制,他跟一篇文章或一個圖片沒有本質上的區別。所以,編程面對的就是把上游數據進行合理的解釋,從一個數據結構轉換成另一個數據結構,這個轉換過程一般情況下由人來完成——碼農就是這個轉換的解釋器。
說到轉換,我就想到我們師徒四人換取通關文牒……抱歉抱歉,走錯片場了。
舉個例子,現在有個文牒、哦不、文檔查詢網站,首頁提供了一個搜索框,上面有關鍵詞、分類和標籤三項,當您輸入關鍵詞、選擇分類和標籤後點擊搜索,頁面會向服務器重新請求並跳轉,URL 從 http://xxx.com/document 變成 http://xxx.com/document?word=催化&type=化工&tags[]=高新科技&tags[]=前沿技術,到服務器後,尾巴上的參數轉換成 {word: "催化", type: "化工", tags: ["高新科技", "前沿技術"]},再被轉換成 SQL 查詢語句 SELECT * FROM document WHERE word LIKE '%催化%' AND type = '化工' AND tags IN ('高新科技','前沿技術')。從 URL 的問號後的查詢串轉換爲程序裏的結構化數據,這個過程一般由服務容器或應用框架自動完成,這個過程是一對一的映射,基本不存在歧義,所以往往不用程序員手工編程處理;但是從請求數據轉換成查詢語句,就不太好”通用“了。type=化工 和 word=催化 有什麼區別嗎?都是一個等於號挑着兩個串,誰知道前者對應的是 = 而後者就要變成 LIKE 呢?答案是程序員知道,因爲產品經理讓他這麼幹的。他會寫代碼:if (request.word) sql += " AND word LIKE {request.word}",這只是用僞代碼舉例,不用糾結看不看得懂,現實中出於分層、通用、規範甚至是裝逼,可能在數據與查詢之間再用一個額外的框架,框架又採用一種中間數據結構,然後由框架再轉成實際的查詢。
可以想象,程序員腦子裏裝了一份底板,如果產品經理說什麼需求那麼他就會寫什麼代碼?把前面這個”如果“拿掉,就可以用一個映射來描述 需求=>代碼。當一個老碼農閱碼無數後找出來幾種常用轉換歸類,那麼,可以用結構化的方式描述底板:
{
"一般字段": "`{字段名}` = '{取值}'",
"關鍵詞類": "`{字段名}` LIKE '%{取值}%'",
"多個值類": "`{字段名}` IN (JOIN(',',{取值}))"
}
如果進一步發掘共同點,還能總結出數字類型、日期類型,然後前端表單結構那邊讓一步,雙方約定好規則,比如加 _lt 後綴的表示小於、加 _gt 後綴的表示大於,或是在值的格式上做文章,定義爲類似數學區間的形式 (min,max) [min,max]。
這還不夠,結構描述我們還可以搬進去更多東西,比如 docuemnt 表跟 author 表之間什麼關係。說到關係……串場了串場了……對於關係,可以查閱 ERM (實體關係模型) 相關的資料,並不需要技術背景就能看明白。簡單來說,我們可以將文檔(資源、實體)之間的關係歸納爲一對一、一對多、多對多,加上依賴方向,再衍生出幾種不同的圖例。反過去向下追究,到物理模型,就只有一種關係,可以用 UML 的類圖表示爲依賴,只需要一個箭頭符號來指向被依賴方。
好久不畫了、軟件也沒裝,度娘搜來的 ERM 圖例和 UML 類圖太醜,略
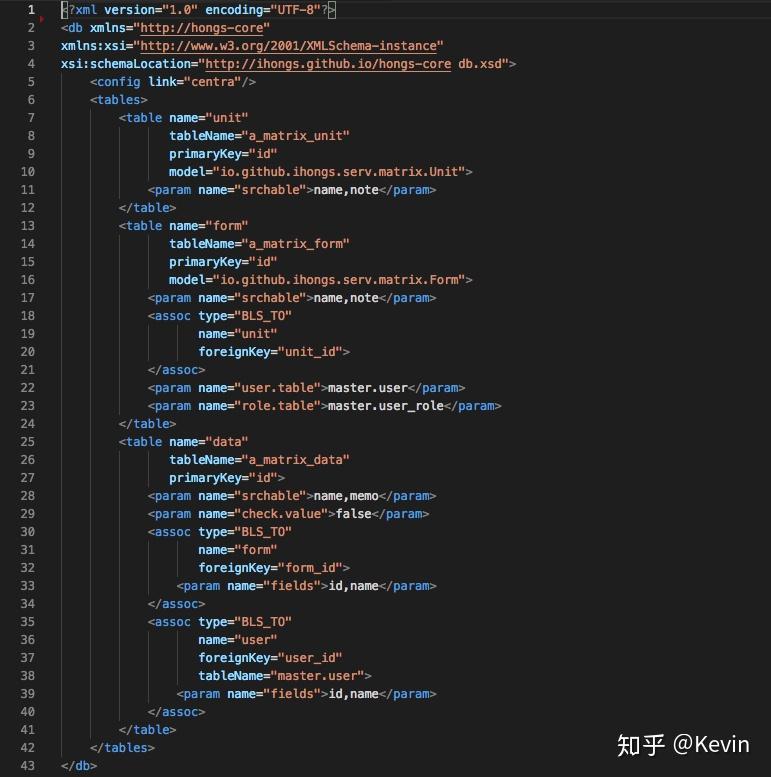
起初,我的系統建立在關係數據庫之上,這也是常見的教科書式的手段。數據庫的表結構本身含有一定的描述,比如字段名、字段類型、取值約束等。但這顯然還不夠,於是定義了一個 xml 來描述表和表之間的關係;這部分其實也能從數據庫本身取得,但獲取方式在各數據庫產商中並不像 SQL 那樣有一致的規範,而想要統一就得進行封裝,內部再來處理差異部分。這偏離了目標,因此僅在完成 MySQL 的結構提取後就終止了,改爲自行描述關聯關係。這樣做順便得到一個好處,很多時候可以不需要 JOIN 就能完成關聯查詢,甚至跨庫跨數據庫類型的關聯的——儘管可能效率不夠高。
這個關係數據庫的描述文件見:默認配置,內部註釋含寫法;格式描述。
https://pic3.zhimg.com/v2-98d...
用戶模塊的關係描述文件

後來,NoSQL 興起,有 Redis、MongoDB、CouchDB 等諸多選擇,可惜這一次這些大廠似乎誰也沒說服誰,無法形成統一的標準。如果定義一個資源對象就是一個文檔(參考簡歷的結構),因此選擇文檔類數據庫就再合適不過了。Redis 等鍵值庫肯定不行了,棄之;我還希望這個庫能嵌入我的系統,這樣就可以像 Sqlite 那樣一同打包、一併啓動。於是 Lucene 成了不二的選擇。
Lucene 非數據庫?此話怎講?阿里搞搜索的人說他們的業務部門希望他們的搜索系統像數據庫一樣即存即取,印象裏他們還專門發文談到過。坑他們都踩過了,雖不知道如何跳過去的,但只要知道能過去就行了。所以 Lucene 不但是數據庫,還是很好的文檔數據庫;需要的話還可以是圖(譜)數據庫,Neo4j 底層即爲 Lucene,我也有直接用 Lucene 開發過人脈關係引擎。
打斷一下,現在你要搜 Lucene 首先進入的是 Solr 的站點,Lucene 已經成了 Solr 的一個附件。爲什麼不選擇封裝得更完備的 Solr?除了上面說的需要嵌入的原因,還因爲將要談到的描述結構 Solr 就那麼幹了。大爺我手裏有槍,別拿你那大炮仗嚇唬人。
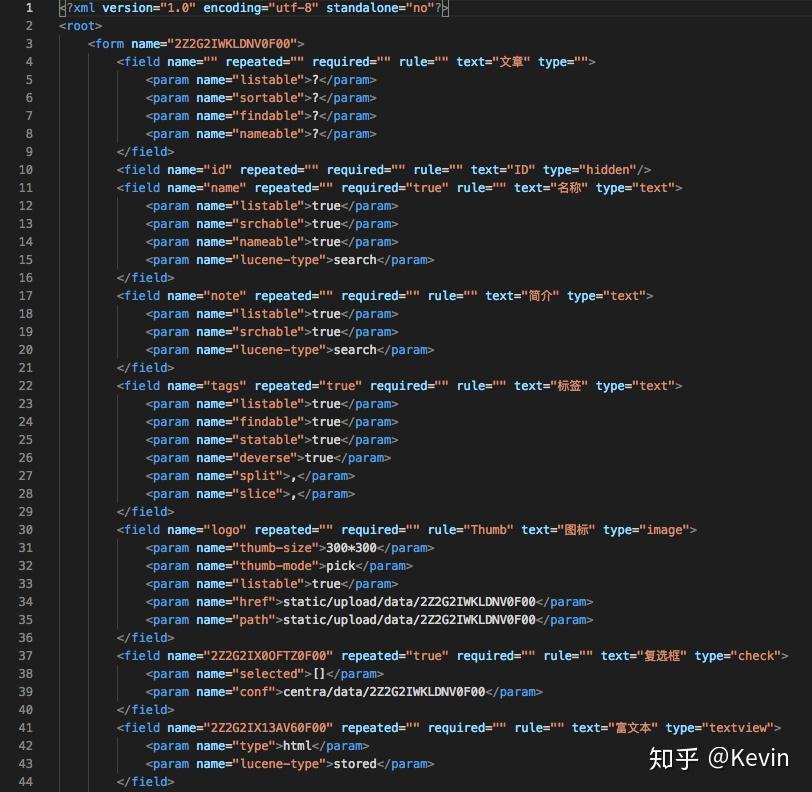
文檔數據庫是沒有固定結構的,怎麼存怎麼取你說了算。這很麻煩,但對我的需求來說,這太棒了。就意味着,只要做一個結構生成器,再也不必爲如何生成和變更表結構傷腦筋了。
先把示例文件甩出來:默認配置,內部註釋含寫法;結構描述。
https://pic3.zhimg.com/v2-be2...
自動生成的資源描述文件

至此,碼農腦子裏那份底板已經摳出來最簡單但也是最常用的部分了,碼農們在這一瞬間得到了解脫。放心,失不了業;搞成平臺除外,但也不必擔心,真那樣的話只會刺激市場釋放更多需求,然後碼農們搞得風生水起,“升值加薪,當上總經理,贏取白富美”……打住打住,“你有權保持沉默,但是你沒權扯淡啊”。
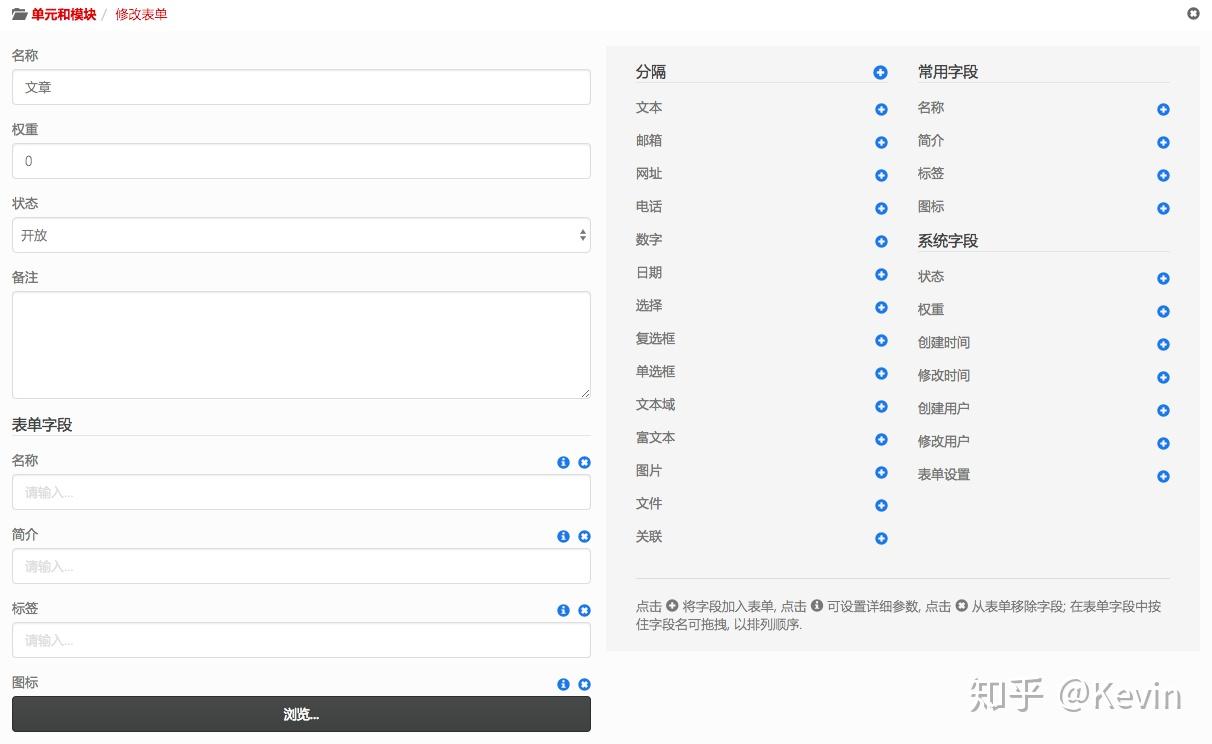
然後呢?讓產品經理去寫配置?倒也是,這 XML 看上去也沒比 PRD 難在哪嘛。但送佛還是要送上西天D,拿鍵盤敲代碼(儘管不是邏輯代碼)這種蠢事讓我們碼農幹就行了,還是要搞個圖形界面好讓人指點江山呀。
https://pic1.zhimg.com/v2-ed0...
資源設置界面

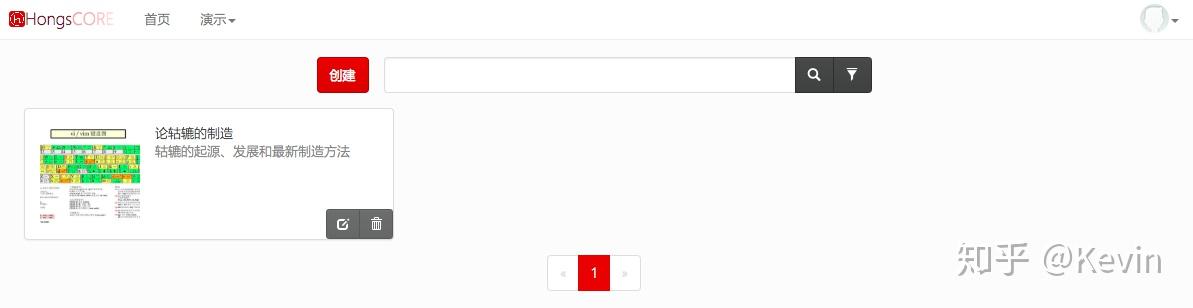
https://pic1.zhimg.com/v2-6ff...
資源管理界面

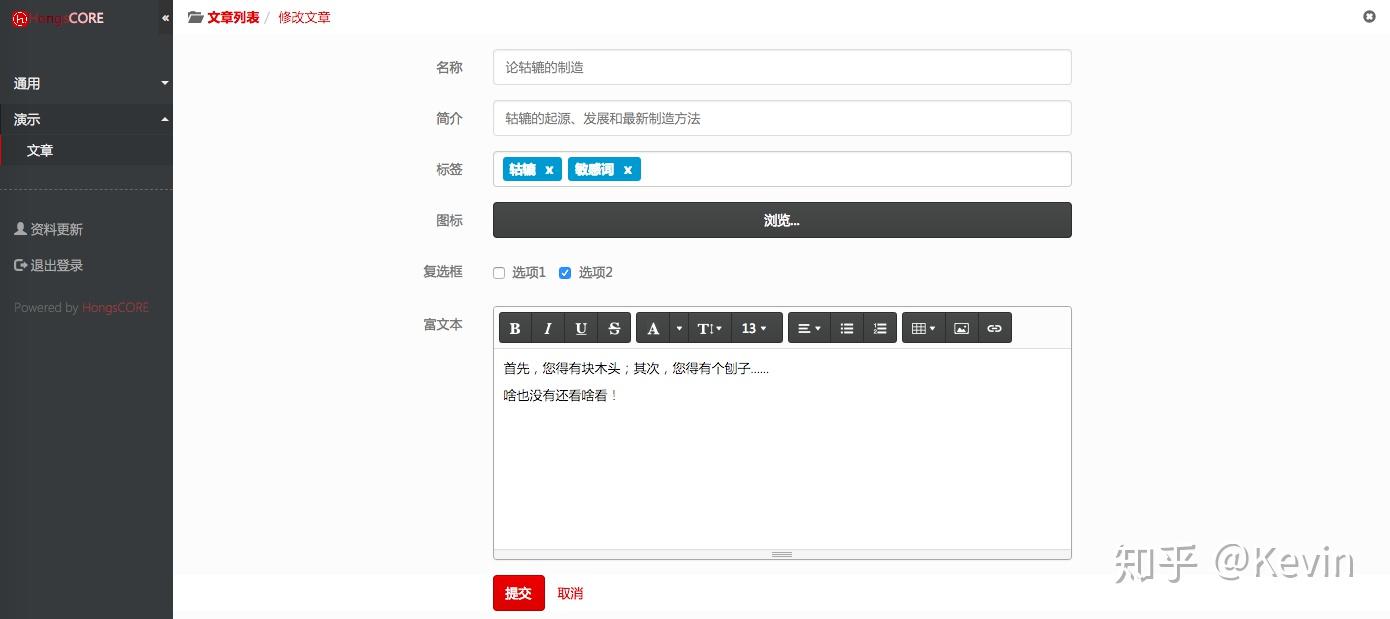
https://pic1.zhimg.com/v2-655...
資源編輯界面

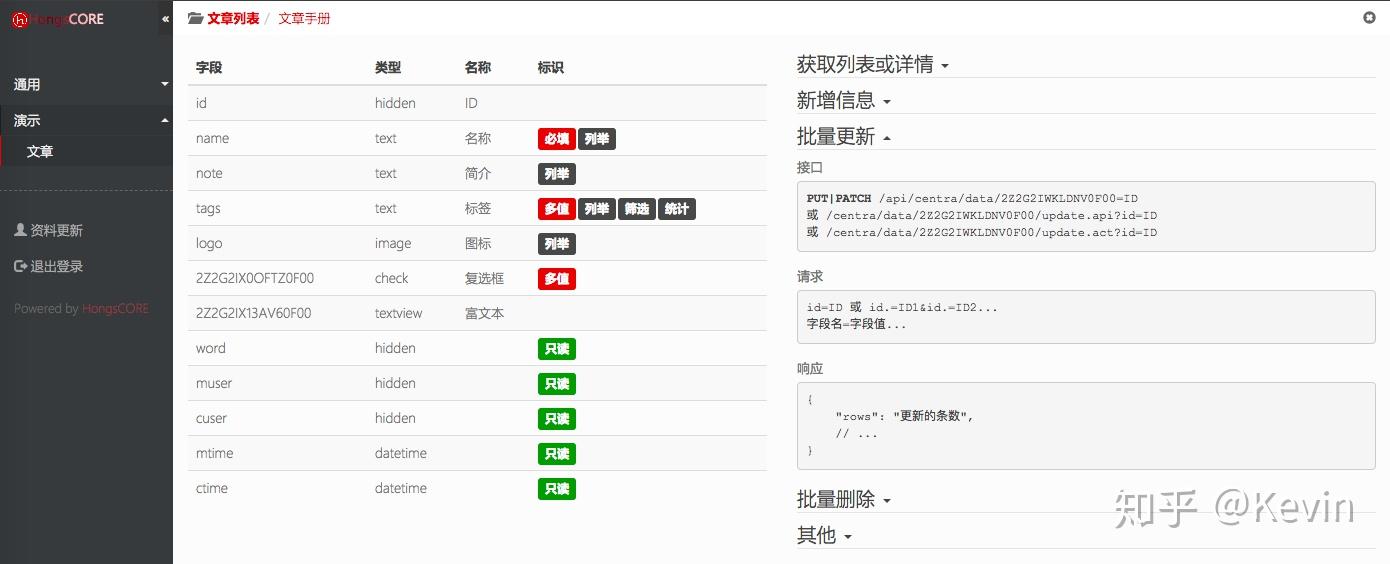
https://pic2.zhimg.com/v2-8e0...
接口文檔界面

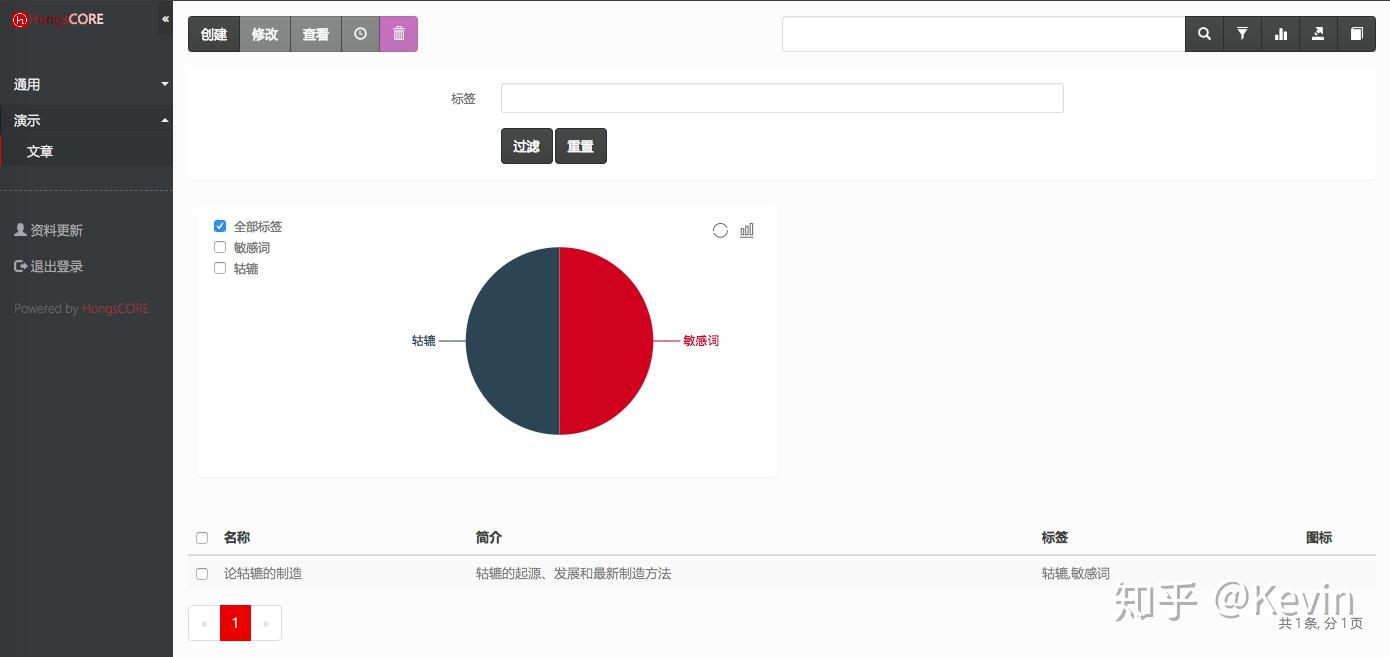
https://pic1.zhimg.com/v2-758...
對外開放界面

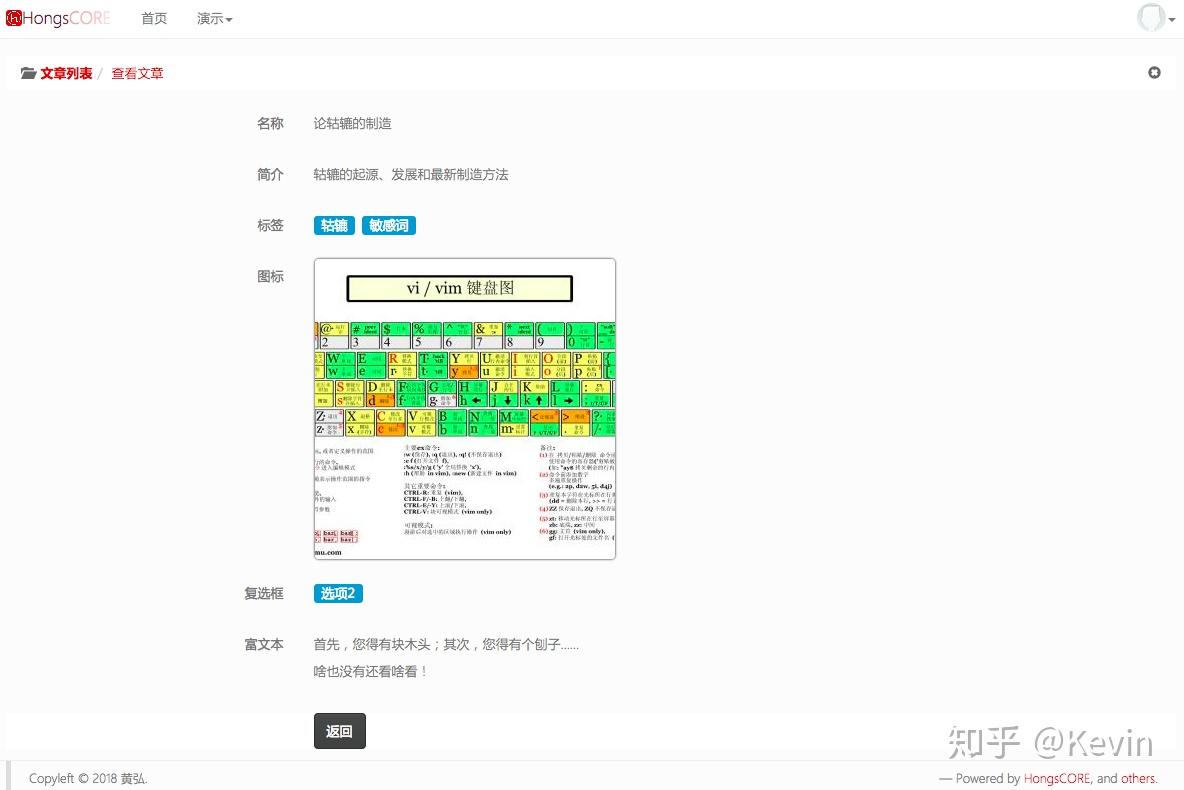
https://pic2.zhimg.com/v2-ef7...
開放查看界面

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
第一幅圖的設置完成後,後面的界面就自動產生了。這個依據是什麼呢?產品經理、助理們會畫出一個個原型圖,程序員看了後想象數據該如何存儲,然後倒騰腦海裏那一堆代碼底板,最終變成邏輯和頁面。這要說回上十年以前,沒有產品經理,沒有 UI、UE,幾個程序員在白板上比劃兩下就擼起袖子開幹了;至於界面,頂多再拉個美工做幾個水晶按鈕,現實中相近的東西長什麼樣,軟件就儘量做成什麼樣。
這個話題深入下去可以談到“自頂而下”和“自底而上”兩種設計方式。簡單來說,一個是從表面看問題,最後確定一下如何將狀態持久化;一個是從底層看問題,先確定數據如何存儲然後向上逐層擴展直至界面。實際的情況多是兩者相結合的,“自頂而下設計,自底而上實現”。
現在穿越時空回到過去,定義有什麼樣的結構就該有什麼的界面,那麼從那個表單配置 XML 出發,通過研究歷史的界面和操作流程,進行總結並將過程固定下來,形成映射關係,就自然可以產生操作界面了。
具體點來說,總結髮現一個普通的 UI 流轉過程可以抽象爲 加載、打開、發送 3 種類型,採用事件驅動,並在流程上規定“誰打開、誰負責”,讓各大組件間可以用最通用、最簡單方式交換狀態。但與面向前端程序員的接口不同,UI 是面向人的,而人的思想和喜好具有很大的不確定性,因此,並未對 UI 部分提供更多的輔助設置。一個註定要被重新編寫的東西,你做的越多那麼定製的人改起來就越累,一點多餘也不做,就是最好的選擇。
當超越時間去看待問題,一切過程都是結構。
TODO:沒人願意看你的代碼,這裏應當放一個演示視頻。
談一個技術上有爭議的事,爲了實現這個系統,我打造了一個完整的應用框架,完全不同於 Spring,Struts 這些業界流行的產品。參考了 PHP 的鬆散數據結構,參考了 Spring 的反轉控制,參考了 Python Django 的校驗模型(有四五年沒用了,不知道現在套路變了沒)。而且大量使用集合框架,而很少去構造私有結構,這在部分程序員看來可能是過於鬆散,有些應該做只讀隔離的卻沒有做封裝。但熟悉 Java 的都知道,反射其實能跳過很多限制,有些隔離封裝就是防君子不防小人。我沒有必要對此上工作的程序員像防賊一樣時刻惦記着,而只要一個約定即可:有些全局的東西你最好別去變更。
不管您認不認同,看在碼了這麼多年的份上,給我 GayHub 上可憐的星星數 ++
再補充一個,知乎上有談到人工智能生成代碼的話題。AI 很火,2018 年火得一塌糊塗,我所在公司的一個兄弟單位也在搞,一下子好像 AI 要統治世界。那麼,這裏面最讓各路人員不爽的當然是碼農兄弟們了,讓你們做個軟件磨磨唧唧的,如果機器能寫代碼了,那就不需要僱傭程序員了,再也不會跟他們因討論識別手機殼換主題顏色的問題幹仗了。可是,如果某個系統的產出是程序代碼,那麼他首先的用戶不應該是碼農嗎?如果您的系統是爲了解決某些普遍的問題,能生成代碼爲什麼不直接執行解決問題呢?如果需要生成代碼,那只有一種可能就是那個生成的代碼不夠完善沒法直接應用於終端,需要碼農去微調。
一二十年前的一些 UML 工具箱就能生成代碼,人類似乎太健忘了。5 年前我還在魔都幹着互聯網廣告的勾當(所以沒準幾年前您在各網站上瞎點時咱們就產生間接聯繫了),也寫過一個小的報告系統,中間會生成報表代碼,原因正是上面說到的,跟各不同報表需求部門扯不清楚,短時間內沒法總結出普適的規則,所以生成腳本代碼,以便在接到特殊邏輯後快速微調。
所以,雖然我認同 AI 的發展方向,並因不能全身進入而爲自己的未來感到擔憂;但是,我不認同用 AI 生產代碼是個好主意。承載代碼的是編程語言,而語言就是溝通的橋樑。AI 與 AI 之間可能在未來會產生屬於他們自己的溝通規則,但那不應當是適合人類閱讀的程序邏輯代碼。