




Python編程語言無疑是人工智能最重要的語言之一,但是其中語音識別是當前人工智能比較熱門的方向,百度的小度機器人、阿里的天貓精靈等其他各大公司都推出了各自的語音助手機器人,其識別算法主要是由RNN、LSTM、DNN-HMM等機器學習和深度學習技術做支撐。但訓練這些模型的第一步就是將音頻文件數據化,提取當中的語音特徵。
MP3文件轉化爲WAV文件
錄製音頻文件的軟件大多數都是以mp3格式輸出的,但mp3格式文件對語音的壓縮比例較重,因此首先利用ffmpeg將轉化爲wav原始文件有利於語音特徵的提取。其轉化代碼如下: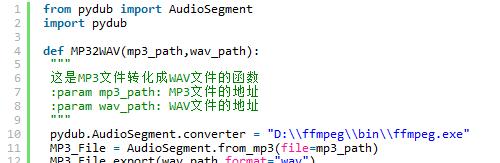
讀取WAV語音文件,對語音進行採樣
利用wave庫對語音文件進行採樣。
代碼如下: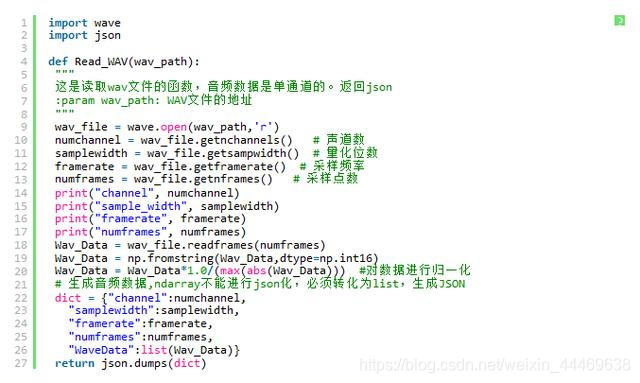
繪製聲波折線圖與頻譜圖
代碼如下: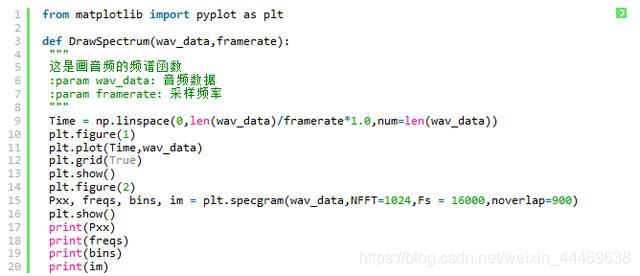
首先利用百度AI開發平臺的語音合API生成的MP3文件進行上述過程的結果。
聲波折線圖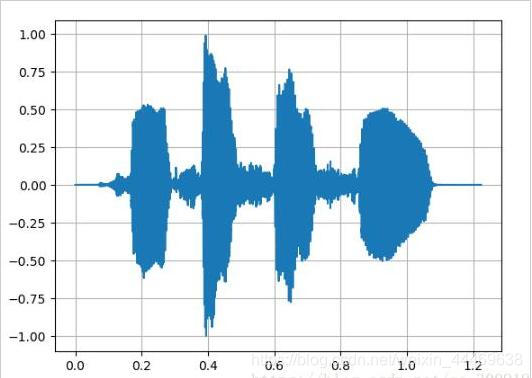
頻譜圖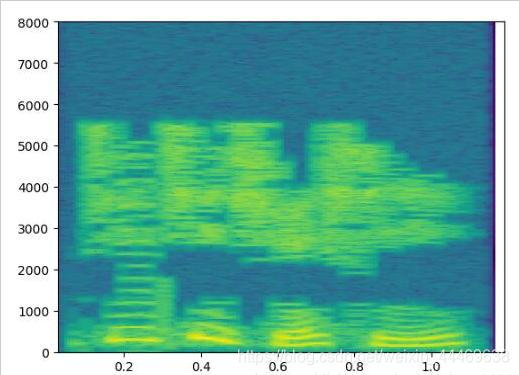
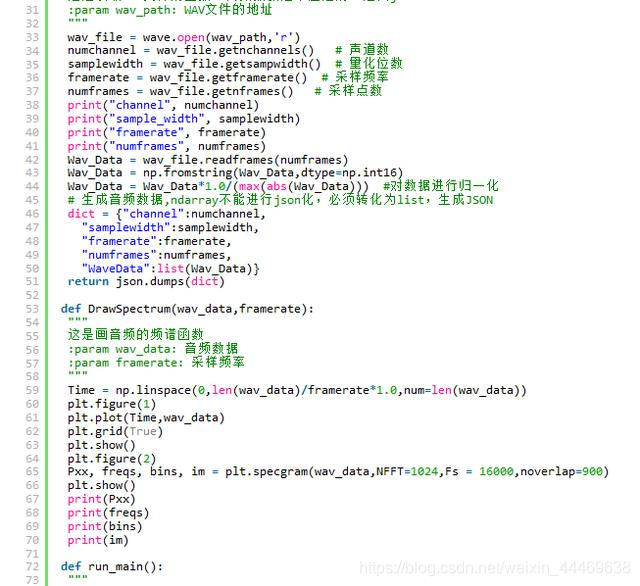
全部代碼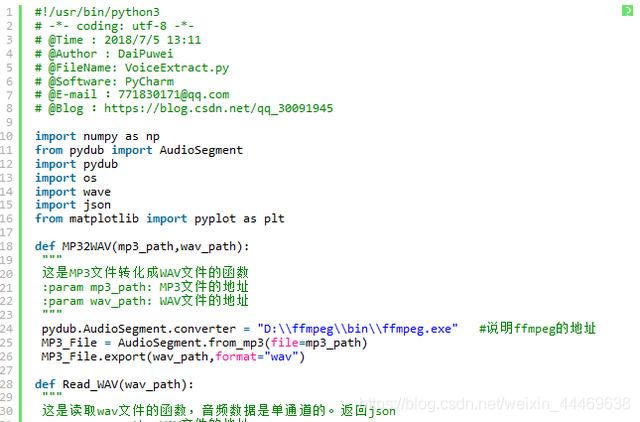

以上這篇就是小編分享的使用python實現語音文件的特徵提取方法。