




下圖列出了Python支持的正則表達式元字符和語法: 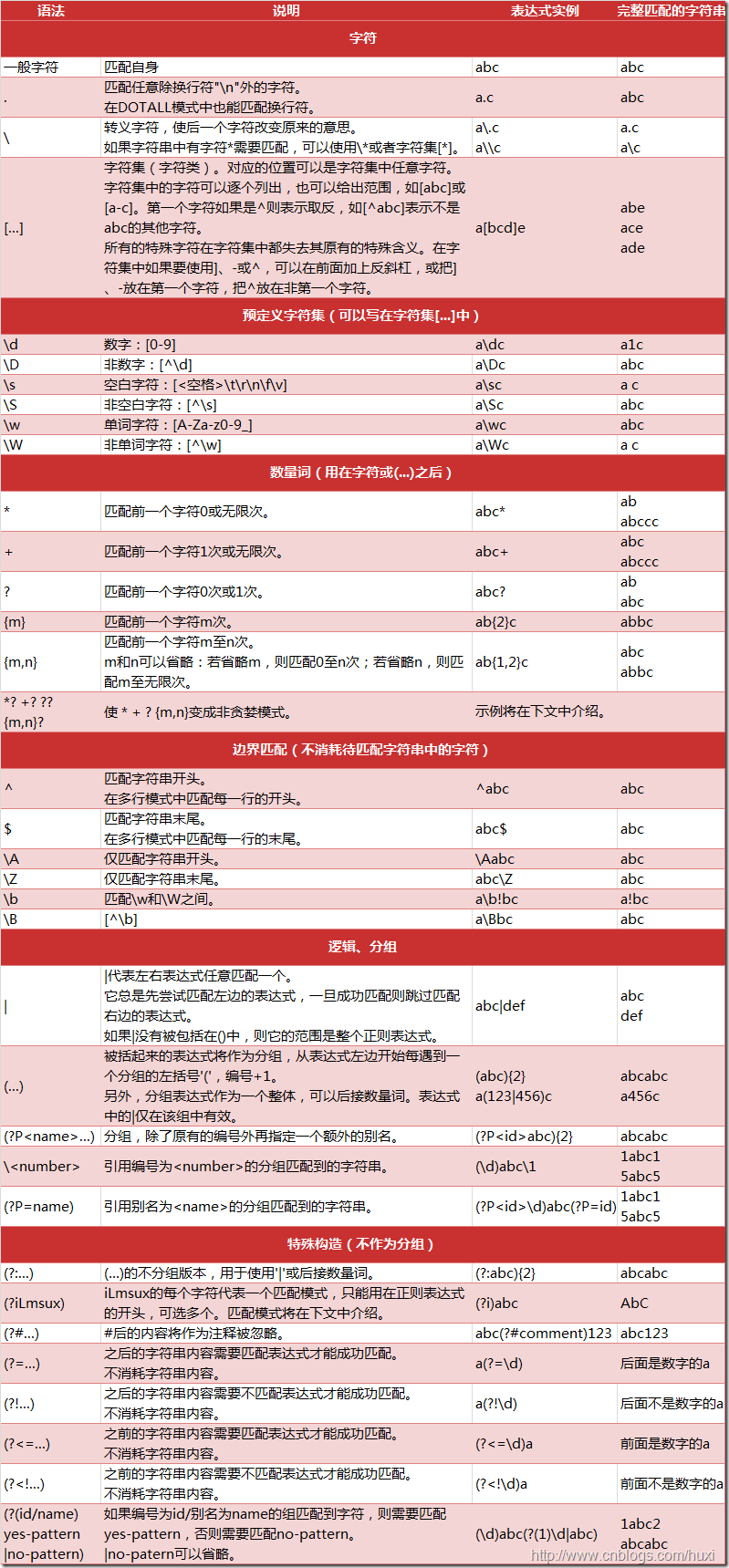
1 -1
Python通過re模塊提供對正則表達式的支持。使用re的一般步驟是先將正則表達式的字符串形式編譯爲Pattern實例,然後使用Pattern實例處理文本並獲得匹配結果(一個Match實例),最後使用Match實例獲得信息,進行其他的操作。
# encoding: UTF-8
import re
# 將正則表達式編譯成Pattern對象
pattern = re.compile(r'hello')
# 使用Pattern匹配文本,獲得匹配結果,無法匹配時將返回None
match = pattern.match('hello world!')
if match:
# 使用Match獲得分組信息
print match.group()
### 輸出 ###
# hello2.2. Match
Match對象是一次匹配的結果,包含了很多關於此次匹配的信息,可以使用Match提供的可讀屬性或方法來獲取這些信息。
屬性:
string: 匹配時使用的文本。
re: 匹配時使用的Pattern對象。
pos: 文本中正則表達式開始搜索的索引。值與Pattern.match()和Pattern.seach()方法的同名參數相同。
endpos: 文本中正則表達式結束搜索的索引。值與Pattern.match()和Pattern.seach()方法的同名參數相同。
lastindex: 最後一個被捕獲的分組在文本中的索引。如果沒有被捕獲的分組,將爲None。
lastgroup: 最後一個被捕獲的分組的別名。如果這個分組沒有別名或者沒有被捕獲的分組,將爲None。
方法:
group([group1, …]):
獲得一個或多個分組截獲的字符串;指定多個參數時將以元組形式返回。group1可以使用編號也可以使用別名;編號0代表整個匹配的子串;不填寫參數時,返回group(0);沒有截獲字符串的組返回None;截獲了多次的組返回最後一次截獲的子串。
groups([default]):
以元組形式返回全部分組截獲的字符串。相當於調用group(1,2,…last)。default表示沒有截獲字符串的組以這個值替代,默認爲None。
groupdict([default]):
返回以有別名的組的別名爲鍵、以該組截獲的子串爲值的字典,沒有別名的組不包含在內。default含義同上。
start([group]):
返回指定的組截獲的子串在string中的起始索引(子串第一個字符的索引)。group默認值爲0。
end([group]):
返回指定的組截獲的子串在string中的結束索引(子串最後一個字符的索引+1)。group默認值爲0。
span([group]):
返回(start(group), end(group))。
expand(template):
將匹配到的分組代入template中然後返回。template中可以使用\id或\g<id>、\g<name>引用分組,但不能使用編號0。\id與\g<id>是等價的;但\10將被認爲是第10個分組,如果你想表達\1之後是字符'0',只能使用\g<1>0。
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能夠匹配的子串將string分割後返回列表。maxsplit用於指定最大分割次數,不指定將全部分割。
import re
p = re.compile(r'\d+')
print p.split('one1two2three3four4')
### output ###
# ['one', 'two', 'three', 'four', '']
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。
import re
p = re.compile(r'\d+')
print p.findall('one1two2three3four4')
### output ###
# ['1', '2', '3', '4']refer : http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html