




1.HDFS常用操作
HDFS文件操作有2種方式:命令行方式和API方式
我們以Hadoop自帶的wordcout實例來演示HDFS分佈式文件系統的命令行方式常用操作。
[liuqingjie@master ~]$ mkdir input
[liuqingjie@master ~]$ cd input/
[liuqingjie@master input]$ echo "hello world" >test1.txt
[liuqingjie@master input]$ echo "hello hadoop" >test2.txt
[liuqingjie@master input]$ cd ../hadoop-0.20.2
//將輸入文件複製到分佈式系統裏(in)
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -put ../input in
//查看分佈式系統裏的文件
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls ./in/*
-rw-r--r-- 2 liuqingjie supergroup 12 2015-05-09 04:18 /user/liuqingjie/in/test1.txt
-rw-r--r-- 2 liuqingjie supergroup 13 2015-05-09 04:18 /user/liuqingjie/in/test2.txt
注意,/user/liuqingjie/in/ 並不是linux裏面實際存在的目錄,而是分佈式系統裏的虛擬根目錄
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop jar hadoop-0.20.2-examples.jar wordcount in out
15/05/09 04:25:23 INFO input.FileInputFormat: Total input paths to process : 2
15/05/09 04:25:23 INFO mapred.JobClient: Running job: job_201505090340_0001
15/05/09 04:25:24 INFO mapred.JobClient: map 0% reduce 0%
15/05/09 04:25:35 INFO mapred.JobClient: map 50% reduce 0%
15/05/09 04:25:36 INFO mapred.JobClient: map 100% reduce 0%
15/05/09 04:25:47 INFO mapred.JobClient: map 100% reduce 100%
15/05/09 04:25:49 INFO mapred.JobClient: Job complete: job_201505090340_0001
15/05/09 04:25:49 INFO mapred.JobClient: Counters: 17
15/05/09 04:25:49 INFO mapred.JobClient: Job Counters
15/05/09 04:25:49 INFO mapred.JobClient: Launched reduce tasks=1
15/05/09 04:25:49 INFO mapred.JobClient: Launched map tasks=2
15/05/09 04:25:49 INFO mapred.JobClient: Data-local map tasks=2
15/05/09 04:25:49 INFO mapred.JobClient: FileSystemCounters
15/05/09 04:25:49 INFO mapred.JobClient: FILE_BYTES_READ=55
15/05/09 04:25:49 INFO mapred.JobClient: HDFS_BYTES_READ=25
15/05/09 04:25:49 INFO mapred.JobClient: FILE_BYTES_WRITTEN=180
15/05/09 04:25:49 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=25
15/05/09 04:25:49 INFO mapred.JobClient: Map-Reduce Framework
15/05/09 04:25:49 INFO mapred.JobClient: Reduce input groups=3
15/05/09 04:25:49 INFO mapred.JobClient: Combine output records=4
15/05/09 04:25:49 INFO mapred.JobClient: Map input records=2
15/05/09 04:25:49 INFO mapred.JobClient: Reduce shuffle bytes=61
15/05/09 04:25:49 INFO mapred.JobClient: Reduce output records=3
15/05/09 04:25:49 INFO mapred.JobClient: Spilled Records=8
15/05/09 04:25:49 INFO mapred.JobClient: Map output bytes=41
15/05/09 04:25:49 INFO mapred.JobClient: Combine input records=4
15/05/09 04:25:49 INFO mapred.JobClient: Map output records=4
15/05/09 04:25:49 INFO mapred.JobClient: Reduce input records=4
//查看測試結果
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls
Found 2 items
drwxr-xr-x - liuqingjie supergroup 0 2015-05-09 04:18 /user/liuqingjie/in
drwxr-xr-x - liuqingjie supergroup 0 2015-05-09 04:25 /user/liuqingjie/out
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls ./out
Found 2 items
drwxr-xr-x - liuqingjie supergroup 0 2015-05-09 04:25 /user/liuqingjie/out/_logs
-rw-r--r-- 2 liuqingjie supergroup 25 2015-05-09 04:25 /user/liuqingjie/out/part-r-00000
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -cat ./out/*
hadoop1
hello2
world1
//將HDFS的文件複製到本地
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -get ./out ./xyz
[liuqingjie@master hadoop-0.20.2]$ ll
drwxrwxr-x. 3 liuqingjie liuqingjie 4096 May 9 05:37 xyz
//刪除HDFS下的文檔
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls ./out
Found 2 items
drwxr-xr-x - liuqingjie supergroup 0 2015-05-09 04:25 /user/liuqingjie/out/_logs
-rw-r--r-- 2 liuqingjie supergroup 25 2015-05-09 04:25 /user/liuqingjie/out/part-r-00000
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -rmr ./out/_logs
Deleted hdfs://master:9000/user/liuqingjie/out/_logs
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls ./out
Found 1 items
-rw-r--r-- 2 liuqingjie supergroup 25 2015-05-09 04:25 /user/liuqingjie/out/part-r-00000
//查看HDFS基本統計信息
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfsadmin -report
Configured Capacity: 38516342784 (35.87 GB)
Present Capacity: 29941987116 (27.89 GB)
DFS Remaining: 29941833728 (27.89 GB)
DFS Used: 153388 (149.79 KB)
DFS Used%: 0%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 2 (2 total, 0 dead)
Name: 192.168.132.132:50010
Decommission Status : Normal
Configured Capacity: 19770150912 (18.41 GB)
DFS Used: 76694 (74.9 KB)
Non DFS Used: 4366947434 (4.07 GB)
DFS Remaining: 15403126784(14.35 GB)
DFS Used%: 0%
DFS Remaining%: 77.91%
Last contact: Sat May 09 05:42:42 PDT 2015
Name: 192.168.132.131:50010
Decommission Status : Normal
Configured Capacity: 18746191872 (17.46 GB)
DFS Used: 76694 (74.9 KB)
Non DFS Used: 4207408234 (3.92 GB)
DFS Remaining: 14538706944(13.54 GB)
DFS Used%: 0%
DFS Remaining%: 77.56%
Last contact: Sat May 09 05:42:41 PDT 2015
//進入和退出安全模式
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfsadmin -safemode enter
Safe mode is ON
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfsadmin -safemode leave
Safe mode is OFF
2.HDFS設計原理
(1)HDSF設計基礎與目標
硬件錯誤是常態。因此需要冗餘
流式數據訪問。即數據批量讀取而非隨機讀寫,Hadoop擅長做的是數據分析而不是事務處理
大規模數據集
簡單一致性模型。爲了降低系統複雜度,對文件採用一次性寫多次讀的邏輯設計,即是文件一經寫入,關閉,就再也不能修改
程序採用“數據就近”原則分配節點執行
(2)HDFS體系結構
HDFS採用了主從(Master/Slave)結構模型,一個HDFS集羣是由一個NameNode和若干個DataNode組成的。下圖給出了HDFS的體系結構。
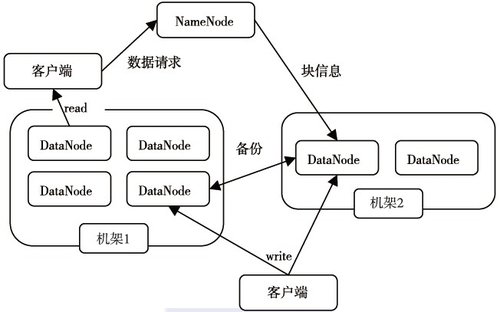
NameNode
管理文件系統的命名空間
記錄每個文件數據塊在各個Datanode上的位置和副本信息
協調客戶端對文件的訪問
記錄命名空間內的改動或空間本身屬性的改動
Namenode使用事務日誌記錄HDFS元數據的變化。使用映像文件存儲文件系統的命
名空間,包括文件映射,文件屬性等
DataNode
負責所在物理節點的存儲管理
一次寫入,多次讀取(不修改)
文件由數據塊組成,典型的塊大小是64MB
數據塊儘量散佈道各個節點
數據讀取流程
客戶端要訪問HDFS中的一個文件,首先從namenode獲得組成這個文件的數據塊位置列表,根據列表知道存儲數據塊的datanode,訪問datanode獲取數據。Namenode並不參與數據實際傳輸。
(3)HDSF的可靠性理念
a.冗餘副本策略
*可以在hdfs-site.xml中設置複製因子指定副本數量
*所有數據塊都有副本
*Datanode啓動時,遍歷本地文件系統,產生一份hdfs數據塊和本地文件的對應關係列
表(blockreport)彙報給namenode
b.機架策略
*集羣一般放在不同機架上,機架間帶寬要比機架內帶寬要小
HDFS的“機架感知”
*一般在本機架存放一個副本,在其它機架再存放別的副本,這樣可以防止機架失效時
丟失數據,也可以提高帶寬利用率
c.心跳機制
*Namenode週期性從datanode接收心跳信號和塊報告
*Namenode根據塊報告驗證元數據
*沒有按時發送心跳的datanode會被標記爲宕機,不會再給它任何I/O請求
*如果datanode失效造成副本數量下降,並且低於預先設置的閾值,namenode會檢測
出這些數據塊,並在合適的時機進行重新複製
*引發重新複製的原因還包括數據副本本身損壞、磁盤錯誤,複製因子被增大等
d.安全模式
*Namenode啓動時會先經過一個“安全模式”階段
*安全模式階段不會產生數據寫
*在此階段Namenode收集各個datanode的報告,當數據塊達到最小副本數以上時,會被認爲 是“安全”的
*在一定比例(可設置)的數據塊被確定爲“安全”後,再過若干時間,安全模式結束
*當檢測到副本數不足的數據塊時,該塊會被複制直到達到最小副本數
e.校驗和
*在文件創立時,每個數據塊都產生校驗和
*校驗和會作爲單獨一個隱藏文件保存在命名空間下
*客戶端獲取數據時可以檢查校驗和是否相同,從而發現數據塊是否損壞
*如果正在讀取的數據塊損壞,則可以繼續讀取其它副本
f.回收站
*刪除文件時,其實是放入回收站/trash
*回收站裏的文件可以快速恢復
*可以設置一個時間閾值,當回收站裏文件的存放時間超過這個閾值,就被徹底刪除,
並且釋放佔用的數據塊
g.元數據保護
*映像文件剛和事務日誌是Namenode的核心數據。可以配置爲擁有多個副本
*副本會降低Namenode的處理速度,但增加安全性
*Namenode依然是單點,如果發生故障要手工切換
h.快照機制
*支持存儲某個時間點的映像,需要時可以使數據重返這個時間點的狀態
*Hadoop目前還不支持快照,已經列入開發計劃