




四、代碼結構(2) space manager
這一篇和下一篇我們來介紹dm dedup的空間管理的部分和核心流程I/O寫流程
在此之前,我們先分析一下用到的資源有哪些,和了解dm dedup的space manager空間管理器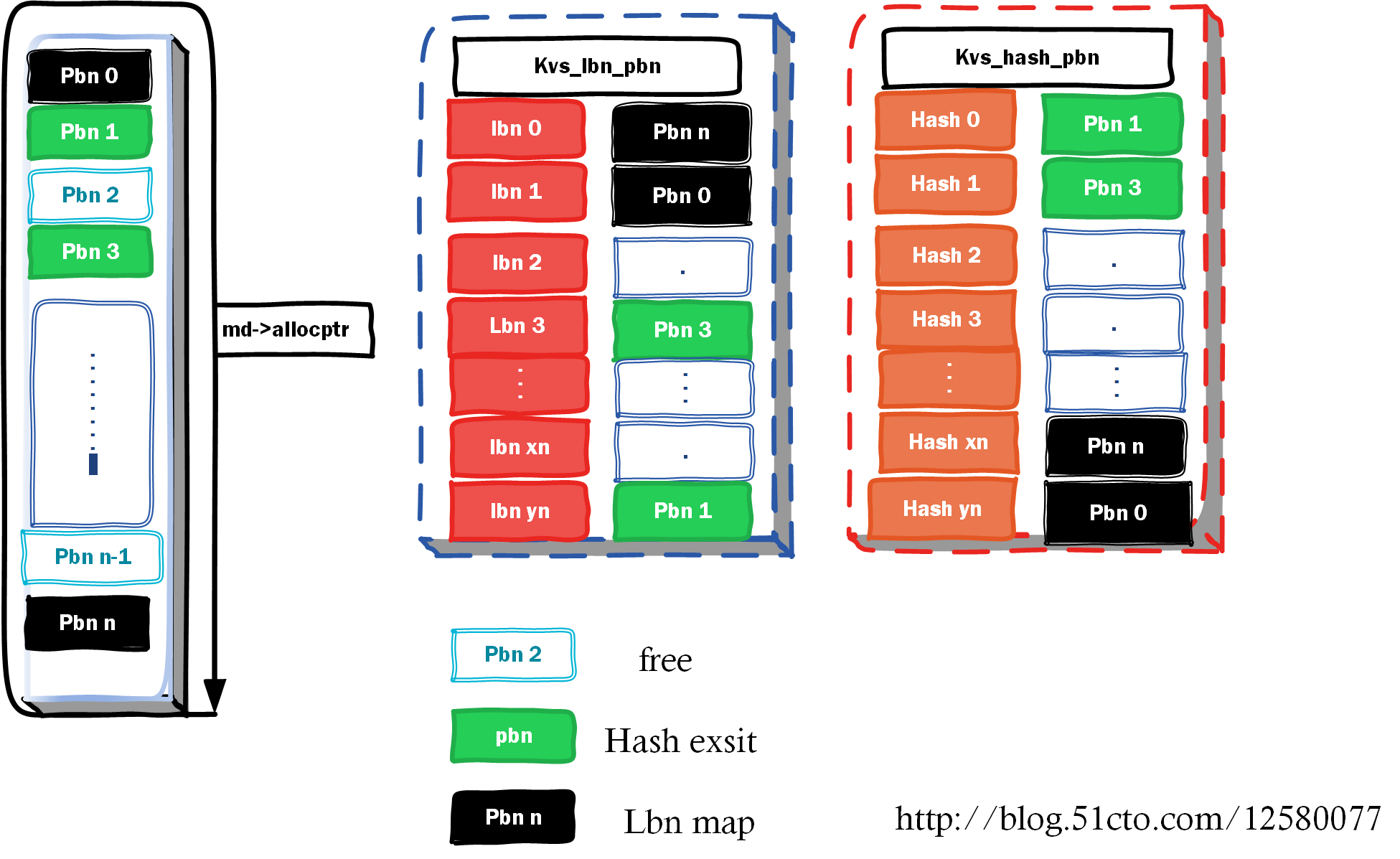
空間管理器,是一個巨型的數組,以allocptr申請指針爲標,對整個space進行掃描一週(回到current allocptr)。
用來找到空閒的塊(白色),並把它分配給一個hash request,把它變成一個綠色的塊,並把這個信息hash_pbn,放到kvs_hash_pbn的表內。
kvs_lbn_pbn和kvs_hash_pbn的空間是預先分配好的,所以這兩個表的index都是有確定的含義,非常利於查找。
dc->kvs_hash_pbn = dc->mdops->kvs_create_sparse(md, crypto_key_size,sizeof(struct hash_pbn_value),dc->pblocks, unformatted);
dc->kvs_lbn_pbn = dc->mdops->kvs_create_linear(md, 8,sizeof(struct lbn_pbn_value), dc->lblocks, unformatted);在創建kvs(key value space)的時候,有兩種選擇,一種是按照linear就是一一映射的lbn-pbn的方式,還有一種是hash index的方式。
其中都會將ksize和vsize會在兩種space類型不同而會以不同的方式保存。
① kvs-lbn-pbn,linear的create space方式inram
static struct kvstore *kvs_create_linear_inram(struct metadata *md,u32 ksize, u32 vsize,u32 kmax, bool unformatted)
{
struct kvstore_inram *kvs;
u64 kvstore_size, tmp;
kvs = kmalloc(sizeof(*kvs), GFP_NOIO);
if (!kvs)
return ERR_PTR(-ENOMEM);
kvstore_size = (kmax + 1) * vsize;
kvs->store = vmalloc(kvstore_size);
/*確定kvs->store的大小,這裏的思想很簡單,
就是64 bit的lbn尋址到一個ksize的pbn上面,一般的pbn也是64 bit*/
/*kmax是 邏輯設備的大小,這個map-table的含義就是lbn-pbn的映射關係*/
tmp = kvstore_size;
(void)do_div(tmp, (1024 * 1024));
memset(kvs->store, EMPTY_ENTRY, kvstore_size);
kvs->ckvs.vsize = vsize;
kvs->ckvs.ksize = ksize;
kvs->kmax = kmax;
kvs->ckvs.kvs_insert = kvs_insert_linear_inram; /*插入api*/
kvs->ckvs.kvs_lookup = kvs_lookup_linear_inram; /*查找api*/
kvs->ckvs.kvs_delete = kvs_delete_linear_inram; /*刪除api*/
kvs->ckvs.kvs_iterate = kvs_iterate_linear_inram; /*迭代api*/
md->kvs_linear = kvs;
return &(kvs->ckvs);
}我們簡單看一看kvs_insert_linear_inram和kvs_lookup_linear_inram,刪除和迭代留在垃圾回收的部分介紹。
static int kvs_insert_linear_inram(struct kvstore *kvs, void *key,s32 ksize, void *value,int32_t vsize)
{
u64 idx;
char *ptr;
struct kvstore_inram *kvinram = NULL;
kvinram = container_of(kvs, struct kvstore_inram, ckvs);
idx = *((uint64_t *)key);
ptr = kvinram->store + kvs->vsize * idx; /*以lbn爲key,pbn爲value的map*/
memcpy(ptr, value, kvs->vsize);
return 0;
}插入的代碼非常簡單,就可以理解成linear是個 u64 kvs[kmax] 這樣的數組,lbn是數組下標,而value是數組內容。
static int kvs_lookup_linear_inram(struct kvstore *kvs, void *key,
s32 ksize, void *value,
int32_t *vsize)
{
u64 idx;
char *ptr;
int r = -ENODATA;
struct kvstore_inram *kvinram = NULL;
kvinram = container_of(kvs, struct kvstore_inram, ckvs);
idx = *((uint64_t *)key);
ptr = kvinram->store + kvs->vsize * idx;
if (is_empty(ptr, kvs->vsize))
return r;
memcpy(value, ptr, kvs->vsize);
*vsize = kvs->vsize;
return 0;
}② kvs-hash-pbn,sparse的create space方式inram
sparse 的方式和linear不太一樣,它的組織形式會更加複雜一些
他要存 key和value兩個,key_size是採用hash算法的大小,如:md5是128 bit,value是pbn是64 bit
static struct kvstore *kvs_create_sparse_inram(struct metadata *md,
u32 ksize, u32 vsize,
u32 knummax, bool unformatted)
{
struct kvstore_inram *kvs;
u64 kvstore_size, tmp;
kvs = kmalloc(sizeof(*kvs), GFP_NOIO);
/* knummax key的最大值這裏是按照pbn的最大值申請的,物理設備的大小*/
knummax += (knummax * HASHTABLE_OVERPROV) / 100;/*額外申請了十分之一的空間*/
kvstore_size = (knummax * (vsize + ksize)); /*申請單位是vsize(pbn)64bit ksize(hash_size)128 bit*/
kvs->store = vmalloc(kvstore_size);
tmp = kvstore_size;
(void)do_div(tmp, (1024 * 1024));
memset(kvs->store, EMPTY_ENTRY, kvstore_size);
/*將所有的key都預先變成EMPTY_ENTRY= 0xFB(最新的代碼4.13是0xFF)*/
kvs->ckvs.vsize = vsize;
kvs->ckvs.ksize = ksize;
kvs->kmax = knummax;
kvs->ckvs.kvs_insert = kvs_insert_sparse_inram; /*插入api*/
kvs->ckvs.kvs_lookup = kvs_lookup_sparse_inram; /*查找api*/
kvs->ckvs.kvs_delete = kvs_delete_sparse_inram; /*刪除api*/
kvs->ckvs.kvs_iterate = kvs_iterate_sparse_inram; /*迭代api*/
md->kvs_sparse = kvs;
return &(kvs->ckvs);
}
接下來看一下插入和查找函數,這個函數會比linear的難一些,只要一點例子會很好理解。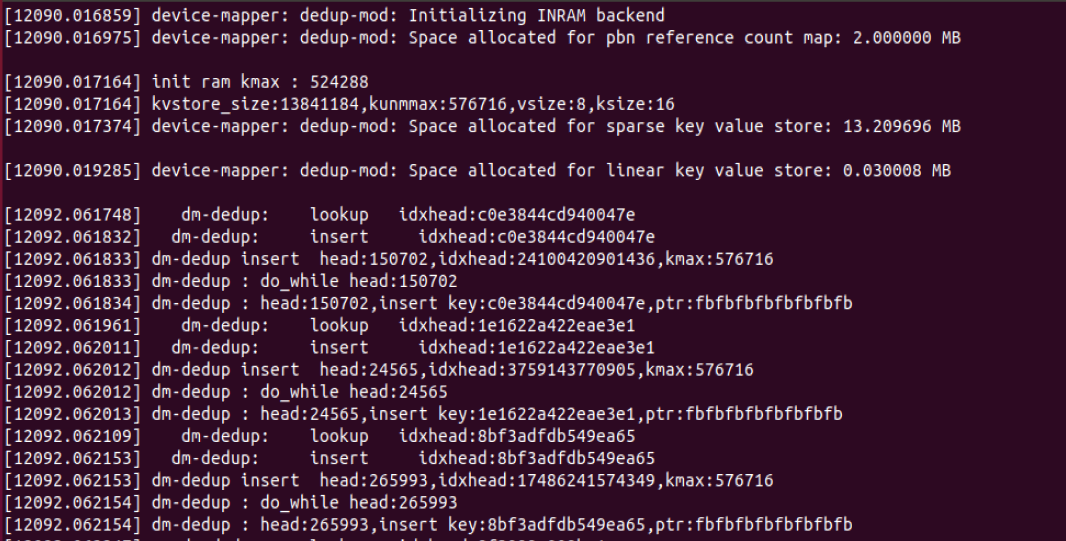
看到調試信息中有初始化的過程。
其中也包括兩個寫流程包括lookup和insert,爲了幫助快速理解,就按照這個例子來說會比較容易。
static int kvs_insert_sparse_inram(struct kvstore *kvs, void *key,s32 ksize, void *value, s32 vsize)
{
u64 idxhead = *((uint64_t *)key); /*無論key是128bit還是64bit,我們取64bit出來*/
u32 entry_size, head, tail;
char *ptr;
struct kvstore_inram *kvinram = NULL;
kvinram = container_of(kvs, struct kvstore_inram, ckvs);
entry_size = kvs->vsize + kvs->ksize; /*確立每個單位entry_size,一般是:64bit + 128 bit*/
head = do_div(idxhead, kvinram->kmax);
/*這一步算出具體key在散列的位置,是把idxhead取餘爲head,
hash出來的key相同的概率之前算過了是非常低,除以kmax取餘,
就是給key在找位置,這個位置head也一部分key的散列屬性*/
tail = head;
/*這個循環很逗,雖然我的調試裏沒有顯示出它起了作用,
但是我們前面說head雖然具有一定的散列屬性,但它在這裏並不具有唯一性,
因爲key本身非常大128bit,他能代表一個pbn的內容的唯一性,
取餘出的head卻是一個小值,他不能唯一代表pbn,
雖然你可以認爲head:150702代表idxhead:0x24100420901436,
並且在這個head位置保存它,但它卻沒有一唯一性,
那麼如果產生了取餘後的head所在位置的*ptr已經存在了,
就需要給這個key另找一個head來保存它,代碼這裏的做法是向後取,
找到一個NULL或者被deleted掉的*ptr,在這個位置把key記錄下來*/
do {
ptr = kvinram->store + entry_size * head;
if (is_empty(ptr, entry_size) || is_deleted(ptr, entry_size)) {
memcpy(ptr, key, kvs->ksize);
memcpy(ptr + kvs->ksize, value, kvs->vsize);
return 0;
}
head = next_head(head, kvinram->kmax);
} while (head != tail);
return -ENOSPC;
}查找的代碼和插入的代碼,幾乎就是一樣的。
就是在do{}while裏先從head開始找,找到一樣的key值,就把它的value(pbn)拿出來。
static int kvs_lookup_sparse_inram(struct kvstore *kvs, void *key,s32 ksize, void *value, int32_t *vsize)
{
u64 idxhead = *((uint64_t *)key);
u32 entry_size, head, tail;
char *ptr;
struct kvstore_inram *kvinram = NULL;
int r = -ENODATA;
kvinram = container_of(kvs, struct kvstore_inram, ckvs);
entry_size = kvs->vsize + kvs->ksize;
head = do_div(idxhead, kvinram->kmax);
tail = head;
do {
ptr = kvinram->store + entry_size * head;
if (is_empty(ptr, entry_size))
return r;
if (memcmp(ptr, key, kvs->ksize)) {
head = next_head(head, kvinram->kmax);
} else {
memcpy(value, ptr + kvs->ksize, kvs->vsize);
return 0;
}
} while (head != tail);
return r;
}這裏可能大家就會覺得很奇怪,爲什麼這裏是這麼簡單的搜索方法,爲什麼不排序等等。
這裏我的思考是這樣的:首先這個是在inram的搜索,所以本身查找的性能還是很高的,其次在這個key取餘的head值,雖然它不具有唯一性,但他具有key的散列屬性,也就是說讓它產生衝突的概率都不高,所以在pbn沒有申請很多的情況下,應該都是直接一步就可以找到的,而且就算產生了衝突,它也是向後找,很可能就是下一個,所以就算碰撞,它保存的位置也具有相關聯性,都會在它的後面的幾個就可以找到,我認爲這個性能應該還不錯。
【本文只在51cto博客作者 “底層存儲技術” https://blog.51cto.com/12580077 個人發佈,公衆號發佈:存儲之谷】,如需轉載,請於本人聯繫,謝謝。