




什麼是批處理任務
深度學習中經常會出現多機多卡的任務,也就是同事會起多個pod,但是這多個pod屬於同一個任務。
這樣就會有一個問題
一個任務要起100個pod,每個pod需要一張卡,總共需要100張GPU卡,而集羣中只有99張空閒的GPU卡,這樣默認的k8s調度器會如何處理?
因爲默認調度器是一個一個pod調度的,只會檢查單個pod資源夠不夠,這樣前99個都能成功,最後一個pod調度失敗。
這樣非常有可能造成
- 任務跑不了
- 前99個佔着GPU不釋放,新的任務無法調度
- 嚴重時整個集羣死鎖,都“佔着茅坑不拉屎”
所以需要在調度時對整個task所需所有資源進行檢查,當集羣總體資源不夠時,一個pod都得不到調度。
社區提供了一個能支持這種特性的調度器
但是這個調度器是沒辦法和原生調度器很好的配合工作的
- 最大的問題在於兩個調度器都有cache,這樣cache的內容會衝突,導致調度混亂
- 這個調度器沒法和原生調度器同時起作用,這樣用了這個batch調度器後就沒法用親和性什麼的特性了
所以我們做的事是將兩者特性融合,選擇的方法是定製化開發kube-scheduler
其實scheduler是可以通過extender擴展的,但是extender還是太弱了,它僅能在預選和優選過程中加入自己的過濾策略,而這對於批處理任務遠遠不夠。
實現難點
需要優選時加batch任務檢查
拿到一個pod ---> 如果是一個batchpod ---> 查詢集羣資源是否滿足batch任務--->否調度失敗需要保障batch任務中其它pod能得到調度
如果集羣資源能滿足這個batch任務直接去bind有個問題:
假設調度隊列是這樣,假設集羣中有三個GPU,而batch任務需要三個GPU:
| A batch pod -> | pod -> | pod -> | A batch pod -> | A batch pod |
|---|---|---|---|---|
| 集羣資源夠 調度成功 | 調度了別的pod | 調度了別的pod | GPU被別的pod佔用 GPU不夠 失敗 | GPU不夠 失敗 |
所以最終結果是A批任務佔用了一個GPU但是整個任務是調度失敗的,那一個GPU還得不到釋放
所以需要修改pod調度隊列裏的順序?讓A batch pod連續調度? 沒這麼簡單,
pod調度是創建協程併發調度的,這樣即便去調整任務隊列裏pod的順序也不一定能保證batch任務其它pod能得到優先調度。
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)只要batch pod走到Bind邏輯了就沒有回頭路了
batch任務中所有pod先進行assume調度,其中任意一個失敗就清理掉其它已經bind但是還沒實際進行調度的pod。 並把所有pod扔回隊列,或者直接返回調度失敗清理改任務的pod,讓上層重新觸發?
scheduler流程 scheduler/sheduler.go scheduleOne邏輯:
選節點->cache assume pod on node-> 創建協程bind
所以在assume時去檢查,不滿足退還已經調度的pod是不可行的,因爲之前batch任務中的pod可能已經bind過了, 所以只能batch任務中最後一個pod得到確認才能去bind前面的pod
預佔用策略
預佔用策略: 第一個batch pod任務來時,檢查集羣資源是不是夠,如果夠進行預佔,把其它幾個node打上標記,讓接下來pod無法佔用其它的node,這樣batch任務其實pod過來就有節點可用。
回到了不能bind的問題。。。
這種問題有兩點:
如何知道batch任務中其它pod需要什麼樣的節點,如果pod都一樣問題可簡化
如果後面的pod失敗了,第一個pod還是已經bind,還是會出現一樣的問題
最終還是在所有pod assume之前不能bind單個pod
綜上,需要在幾個地方處理
隊列最好用優先級隊列,把正在調度的pod的關聯pod優先級提高
選節點時做判斷,看集羣資源是否夠
選好節點assume pod時檢查,如果自己不夠或者pod組不夠就不去bind
問題是之前的pod已經走了bind流程,所以最重要的是如何解決讓之前的pod不去bind,延遲bind
最終方案 - 延遲綁定
方案:在batch任務bind時進行特殊處理
- 如果是batch任務扔進task cache,不進行binding
- 如果batch任務最後一個pod扔進task cache,該task ready,放進bind隊列
- 在bind隊列裏取task 進行bind,task互斥鎖與普通pod bind時互斥
使用
batch任務使用,pod增加兩個註解:
annotations:
scheduling.k8s.io/group-name: qj-1
scheduling.k8s.io/group-pod-num: 3pod加上這兩個註解表示屬於同一個task, num表示task裏有多少pod。
本來是再定義一個CRD去描述這個task,耦合會小一些,但是實現麻煩些,需要多監聽一個CRD,偷懶就沒這樣做
實現
延遲綁定流程: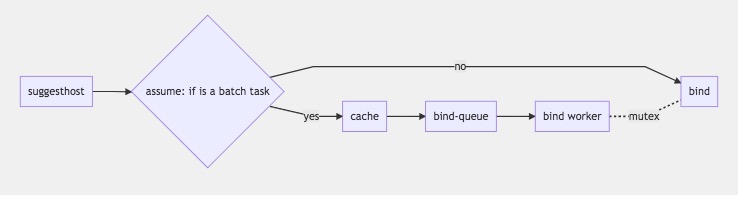
- 如果是普通的pod,找到節點後assume就直接bind
- 如果是批處理任務,直接扔到批處理緩存中返回
- 有個協程一直檢查批緩存中是否有成功的task (pod都齊了)
- 成功的task扔進binding隊列,worker取成功的task進行批量綁定,綁定時與普通pod互斥
batch scheduler接口與成員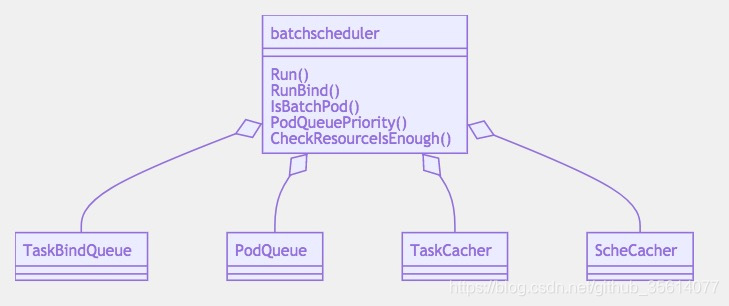
Run 起一個協程檢查成功的task並塞入隊列
RunBind 起一個task綁定協程
PodQuePriority 去動態修改pod隊列的優先級,讓同task的pod優先調度
執行流程: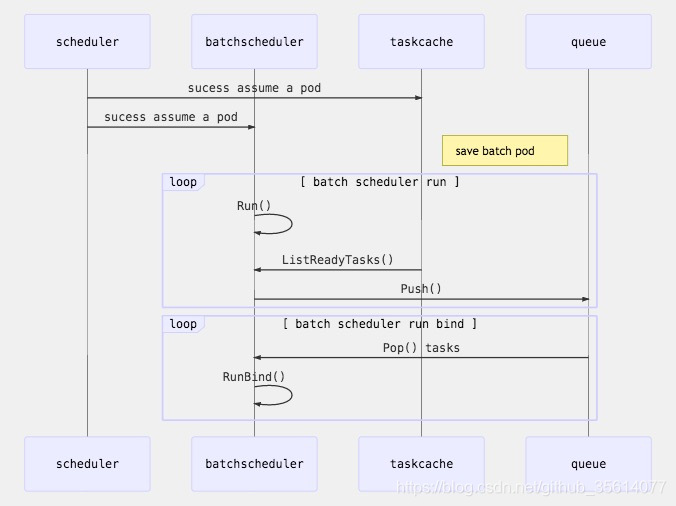
延遲綁定
scheduler/scheduler.go:
//fanux if it is a batch pod, return
if sched.Config.BatchScheduler.IsBatchPod(assumedPod) {
err = sched.Config.BatchScheduler.HandleBatchPod(assumedPod)
if err != nil {
glog.Errorf("schedule batch pod failed: %v", assumedPod.Namespace, assumedPod.Name)
}
return
}增加綁定互斥,防止batch任務和普通pod同事binding:
go func() {
//fanux add bind mutex
sched.Config.BatchScheduler.Lock()
defer sched.Config.BatchScheduler.UnLock()
err := sched.bind(assumedPod, &v1.Binding{檢查資源是否充足CheckResourceIsEnough
should't use filterFunc, needs nodelist
scheduler/util/batch.go
package util
import "api/core/v1"
//CheckResourceIsEnough is
func CheckResourceIsEnough(pod *v1.Pod, nodes []*v1.Node) (bool, error) {
return false, nil
}scheduler/core/generic_scheduler.go
//fanux add checkBatchPodResource
flag, err := util.CheckResourceIsEnough(pod, filteredNodes)
if !flag || err != nil {
return "", err
}
trace.Step("Prioritizing")處理資源不足時的情況
suggestedHost, err := sched.schedule(pod)
//fanux add handle if resource not enough
if strings.Contains(err.Error(), common.BatchResourceNotEnough) {
sched.Config.BatchScheduler.HandleResourceNotEnough(pod)
} else if err != nil {如何獲取節點已經分配GPU的數量
nodeInfo allocatableResource - requestedResource is avaliavle resource
requestedResource *Resource
nonzeroRequest *Resource
allocatableResource *ResourceGPU 是 ScalarResources, 資源名稱叫 : NVIDIAGPUResourceName = "nvidia.com/gpu"
type Resource struct {
MilliCPU int64
Memory int64
EphemeralStorage int64
// We store allowedPodNumber (which is Node.Status.Allocatable.Pods().Value())
// explicitly as int, to avoid conversions and improve performance.
AllowedPodNumber int
// ScalarResources
ScalarResources map[v1.ResourceName]int64
}增加podupdater,可更新podcondition狀態
batchScheduler := batch.NewBatchScheduler(c.schedulerCache, c.podQueue, &binder{c.client}, &podConditionUpdater{c.client})需要把batch scheduler的cache給generic_scheduler資源檢查時需要用
需要知道已經有哪些pod已經assume過了,把這個數量減掉纔是batch任務還需要多少GPU
core/generic_scheduler.go
//fanux add batch Cache
//check batch pod resource is enough need batch scheduler cache
BatchCache common.TaskCache //fanux add checkBatchPodResource
flag, err := common.CheckResourceIsEnough(pod, filteredNodes, g.cachedNodeInfoMap, g.BatchCache)factory.go
//fanux check batch resource is enough need batch scheduler cache
batchCache := batchScheduler.GetTaskCache()
algo := core.NewGenericScheduler(
...
batchCache,
)then checkresource :
//shoud not use metadata, need use metadata - assumed pod num in batch cache
_, podNum := GetPodBathMeta(pod)
podNum -= batchCache.GetTaskAssumedPodNum(pod)檢查資源是否充足詳細算法:
有很多細節
//獲取pod需要多少GPU,這個需要把pod裏容器配額加起來
func GetPodGPUCount(pod *v1.Pod) (count int) {
for _, c := range pod.Spec.Containers {
limit, ok := c.Resources.Limits[NVIDIAGPUResourceName]
l, okay := limit.AsInt64()
if !ok || !okay {
continue
}
count += int(l)
}
glog.Infof("Pod [%s] need GPU [%d]", pod.GetName(), count)
return
}
//獲取節點空閒GPU,需要把可分配的減去已經申請的
func GetNodeFreeGPU(nodeInfo *cache.NodeInfo) int {
if nodeInfo == nil {
return 0
}
allocatable, ok := nodeInfo.AllocatableResource().ScalarResources[NVIDIAGPUResourceName]
if !ok {
glog.Errorf("can't fetch allocatable GPU : %v", nodeInfo)
return 0
}
glog.Infof("node [%s] allocatable GPU [%d]", nodeInfo.Node().Name, allocatable)
requested, ok := nodeInfo.RequestedResource().ScalarResources[NVIDIAGPUResourceName]
if !ok {
//glog.Errorf("can't fetch requested GPU : %v", nodeInfo)
//return 0
requested = 0
}
glog.Infof("node [%s] requested GPU [%d]", nodeInfo.Node().Name, requested)
available := allocatable - requested
glog.Infof("available node [%s] GPU : [%d]", nodeInfo.Node().Name, available)
return int(available)
}
//這裏最關鍵的點是需要把annotations裏面獲取的task pod總數減去已經assume過的batch pod,這樣纔是真實所需
func CheckResourceIsEnough(pod *v1.Pod, nodes []*v1.Node, cachedNodeInfoMap map[string]*cache.NodeInfo, batchCache TaskCache) (bool, error) {
//if is not batch pod, return true,nil
if !IsBatch(pod) {
glog.Infof("pod %s is not batch pod", pod.GetName())
return true, nil
}
//shoud not use metadata, need use metadata - ready pod num in batch cache
_, podNum := GetPodBathMeta(pod)
podNum -= batchCache.GetTaskAssumedPodNum(pod)
everyPodNeedsGPU := GetPodGPUCount(pod)
if everyPodNeedsGPU == 0 {
glog.Infof("pod %s require 0 GPU", pod.GetName())
return true, nil
}
// TODO maybe check nodes[1:], node[0] already allocate a pod, CPU and other metric may reach limit
for _, node := range nodes {
nodeInfo, ok := cachedNodeInfoMap[node.Name]
if !ok {
continue
}
nodeFree := GetNodeFreeGPU(nodeInfo)
podNum -= nodeFree / everyPodNeedsGPU
glog.Infof("pod: [%s] node: [%s] podNum [%d] nodeFree [%d] podNeed [%d]", pod.GetName(), node.Name, podNum, nodeFree, everyPodNeedsGPU)
if podNum <= 0 {
return true, nil
}
}
return false, fmt.Errorf("BatchResourceNotEnough : pod name is %s", pod.GetName())
}
//判斷是不是batch pod
func IsBatch(pod *v1.Pod) bool {
g, n := GetPodBathMeta(pod)
if g == "" || n == 0 {
glog.Infof("The pod's group name is empty string,pod name is %v.", pod.GetName())
return false
}
return true
}關於GPU的使用與發現
這裏包含docker nv-docker GPU-device plugin
install.sh...
/etc/docker/daemon.json
[root@compute-gpu006 ~]# cat /etc/docker/daemon.json
{
"default-runtime":"nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}kubectl describe node xxx:
Capacity:
cpu: 72
ephemeral-storage: 222779Mi
hugepages-1Gi: 0
hugepages-2Mi: 2Gi
memory: 791014684Ki
nvidia.com/gpu: 2 # 這裏就能看到GPU了
pods: 110
Allocatable:
cpu: 72
ephemeral-storage: 210240641086
hugepages-1Gi: 0
hugepages-2Mi: 2Gi
memory: 788815132Ki
nvidia.com/gpu: 2
pods: 110總結
原生調度器的設計就是pod one by one,所以做這個功能的開發還是改動非常大的,也是比較困難的,工作量不大,但是需要找到一個優雅的方案,
合理的架構比較麻煩,想了很久做了這個侵入不太大的實現方案,歡迎大家一起討論
公衆號:
