




Oracle的備份與恢復一直是很吸引我的一個地方。一直搞不明白到底是怎麼個標準來恢復,怎麼來備份。今天就來稍微就這其中的一點名詞和過程來寫寫:
都知道,在創建Oracle的時候,初始默認都會建立三個redo log的文件組。可能大家對這三個log文件組的作用可能不太理解,我自己的理解是這三個log文件組就類似於一個循環,一個組寫滿了,Oracle就切換到另外的一個組裏面去,然後就這麼來來去去。大家可能又會問到,那麼如果這三個組都滿了,怎麼辦?這個我也不太清楚,據我跟一個DBA的探討,應該Oracle就不會忘Redo log文件裏記錄了。但是Oracle也可以通過設置備份策略來避免這種情況的發生。
通常Oracle在提交一個事務,或者是做一個操作的時候,首先將數據讀到內存中來,然後做修改。修改完成後,一般的步驟會是先想Redo log文件裏寫入修改的記錄,然後等待一段時間,由Oracle統一將一批修改寫入磁盤。
那麼怎麼來查看當前是哪個一個redo log文件組被使用呢:
- SQL> select * from v$logfile;
- GROUP# STATUS TYPE MEMBER IS_
- ---------- ------- ------- -------------------- ---
- 3 STALE ONLINE D:\ORACLE\DATA\GJSID NO
- \REDO03.LOG
- 2 ONLINE D:\ORACLE\DATA\GJSID NO
- \REDO02.LOG
- 1 ONLINE D:\ORACLE\DATA\GJSID NO
- \REDO01.LOG
- SQL> select * from v$log;
- GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS
- ---------- ---------- ---------- ---------- ---------- --- ----------------
- FIRST_CHANGE# FIRST_TIME
- ------------- --------------
- 1 1 11 52428800 1 NO CURRENT
- 814175 06-3月 -11
- 2 1 9 52428800 1 YES INACTIVE
- 791711 05-3月 -11
- 3 1 10 52428800 1 NO INACTIVE
- 791923 05-3月 -11
可以看到現在系統中總共是有三組redo log文件組,而且當前被激活是是第一個redo log文件組。
接下來可能會涉及到一個概念,SCN - system change number。這個數字是Oracle在內部用來記錄變化的唯一的一個標示,事務的提交,各種修改的發生,都會修改到這個SCN。也就是可以這樣講到SCN是Oracle的內部邏輯時鐘。那麼怎麼樣子纔可以查看到當前的SCN呢:
- SQL> select dbms_flashback.get_system_change_number from dual;
- GET_SYSTEM_CHANGE_NUMBER
- ------------------------
- 815255
通過這樣的一條語句就可以看到current SCN是多少,你也可以反覆的查看,你就會發現SCN經常在變。
通過上述的語句檢查出來的SCN是系統最新的SCN,上面也講到了,Oracle會統一地將一批數據寫入磁盤,可能就會有這樣的情況,數據修改在Redo log文件中,還沒有及時地反映到磁盤中去,數據庫就發生了Crush,這樣就意味數據的完整性沒有保證,那麼Oracle是怎麼做到恢復的呢。
這個時候,一個檢查點的概念就出來了,checkpoint scn。檢查點就相當於Oracle每隔多長時間做了一次寫入磁盤的批處理動作一樣。
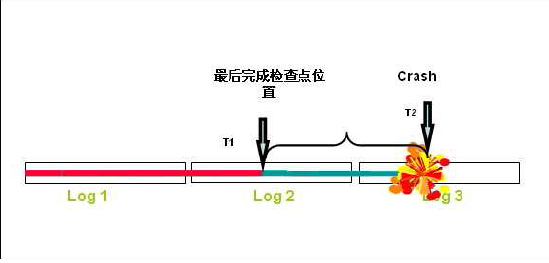
看到了吧,如果在T1時刻Oracle做了一次check,然後在T2時刻數據庫崩潰,那麼Oracle就只需要做T1 - T2時刻的redo log的恢復就Ok。
那麼我是如何知道Oracle是在哪個時刻做了一個check呢:
- SQL> select file#,checkpoint_change#,to_char(checkpoint_time,'yyyy-mm-dd hh24:mm:ss') from v$datafile;
- FILE# CHECKPOINT_CHANGE# TO_CHAR(CHECKPOINT_
- ---------- ------------------ -------------------
- 1 814915 2011-03-06 16:03:55
- 2 814915 2011-03-06 16:03:55
- 3 814915 2011-03-06 16:03:55
- 4 814915 2011-03-06 16:03:55
看到了吧,這個時候,在SCN是814915的時候,Oracle做了一次check。
- SQL> select dbms_flashback.get_system_change_number from dual;
- GET_SYSTEM_CHANGE_NUMBER
- ------------------------
- 816436
而當前最新的Oracle SCN是816436,所以說如果當前Oracle崩潰了,系統需要從814915恢復到816436.
其實我還是有一點不太明白,Oracle難道是隻有發生check的時候,纔將數據寫向磁盤麼,還是一直都在寫。如果是前者的話,那麼這麼長間隔的數據修改,只能從redo log裏查詢麼?如果是後者的話,如果數據已經寫到了磁盤,Oracle在恢復的時候,會不會造成數據的重複寫的情況呢?