




更多精彩內容參見雲棲社區大數據頻道https://yq.aliyun.com/big-data;此外,通過Maxcompute及其配套產品,低廉的大數據分析僅需幾步,詳情訪問https://www.aliyun.com/product/odps。
摘要:回顧大數據技術領域大事件,最早可追溯到06年Hadoop的正式啓動,而環顧四下,圍繞着數據庫及數據處理引擎,業內充斥着各種各樣的大數據技術。這是個技術人的好時代,僅數據庫領域熱門DB就有300+,圍繞着Hadoop生態圈的大數據處理技術更是繁花似錦。在雲棲社區2017在線技術峯會大數據技術峯會上,阿里雲大數據計算平臺架構師林偉做了題爲《MaxCompute的大腦:基於代價的優化器》的分享,爲大家分享阿里巴巴大數據計算服務的大腦——基於代價的優化器的設計和架構。
MaxCompute簡介
大數據計算服務(MaxCompute)是一種快速、完全託管的PB/EB級數據倉庫解決方案,MaxCompute具備萬臺服務器擴展能力和跨地域容災能力,是阿里巴巴內部核心大數據平臺,承擔了集團內部絕大多數的計算任務,支撐每日百萬級作業規模。MaxCompute向用戶提供了完善的數據導入方案以及多種經典的分佈式計算模型,能夠更快速的解決用戶海量數據計算問題,有效降低企業成本,並保障數據安全。
MaxCompute架構

MaxCompute基本的體系結構如上圖所示,最底層就是在物理機器之上打造的提供統一存儲的盤古分佈式文件存儲系統;在盤古之上一層就是伏羲分佈式調度系統,這一層將包括CPU、內存、網絡以及磁盤等在內的所有計算資源管理起來;再上一層就是統一的執行引擎也就是MaxCompute執行引擎;而在執行引擎之上會打造各種各樣的運算模式,比如流計算、圖計算、離線處理、內存計算以及機器學習等等;在這之上還會有一層相關的編程語言,也就是MaxCompute語言;在語言上面希望爲各應用方能夠提供一個很好的平臺,讓數據工程師能夠通過平臺開發相關的應用,並使得應用能夠快速地在分佈式場景裏面得到部署運行。
MaxCompute的研發思路

MaxCompute的研發思路主要分爲以下四個方面:
高性能、低成本和大規模。希望打造的MaxCompute平臺能夠提運算的高性能,儘可能降低用戶的使用成本,並且在規模上面能夠達到萬臺機器以及多集羣的規模。
穩定性,服務化。希望MaxCompute平臺能夠提供穩定性和服務化的方式,使得用戶不用過多地考慮分佈式應用的難度,而只需要注重於用戶需要進行什麼樣的計算,讓系統本身服務於用戶,並能夠提供穩定性,服務化的接口。
易用性,服務於數據開發者。希望MaxCompute平臺是易用的,並且能夠很方便地服務於數據開發工程師,不需要數據工程師對於分佈式的場景進行很深的理解,而只要關注於需要用這些數據進行什麼樣的運算就可以,接下來就是由MaxCompute平臺幫助數據開發工程師高效並且低成本地執行自己的想法。
多功能。希望MaxCompute能夠具有更多的功能,不僅僅是支持流計算、圖計算、批處理和機器學習等,而希望更多種類的計算能夠在MaxCompute平臺上得到更好的支持。
MaxCompute的大腦——優化器
基於以上的研發思路,MaxCompute平臺需要擁有一個更加強大的大腦,這個大腦需要更加理解用戶的數據,更加理解用戶的計算,並且更加理解用戶本身,MaxCompute的大腦需要能夠幫助用戶更加高效地優化運算,通過系統層面去理解用戶到底需要進行什麼樣的運算,從而達到之前提到的各種目的,使得用戶能夠從分佈式場景中脫離出來,不必去考慮如何才能使得運算高效地執行,而將這部分工作交給MaxCompute的大腦,讓它來爲用戶提供更智能的平臺,這也就是MaxCompute所能夠爲用戶帶來的價值。

那麼MaxCompute的大腦究竟是什麼呢?其實就是優化器。優化器能夠將所有信息串聯在一起,通過理解系統中數據的相關性以及用戶的企圖,並通過機器的能力去充分地分析各種各樣的環境,在分佈式場景中以最高效的方式實現對於用戶運算的執行。在本次分享中以離線計算作爲主要例子來對於MaxCompute的大腦——優化器進行介紹。
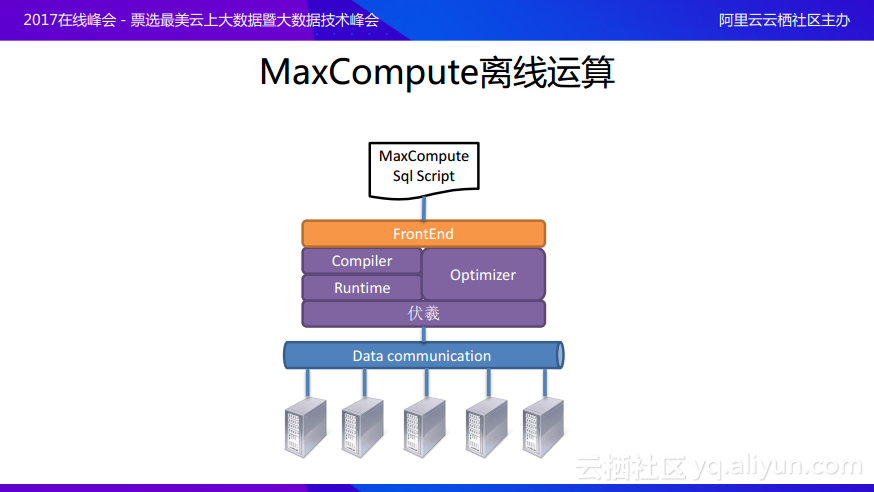
首先對於離線計算的概念進行簡單介紹,MaxCompute離線計算架構設計如上圖所示。在計算層面往往會存在一個類似高級語言的腳本語言,MaxCompute提供的是類SQL的腳本語言,將腳本語言通過FrontEnd提交進來,之後經過處理轉化成爲邏輯執行計劃,邏輯執行計劃在Optimizer(優化器)的指導下翻譯成更加高效的物理執行計劃,並通過與Runtime的連接之後由伏羲分佈式調度系統將物理執行計劃分解到運算節點上進行運算。
上述過程的核心就在於如何充分地理解用戶的核心計劃並通過優化得到高效的物理執行計劃,這樣的過程就叫做優化器Optimizer。目前開源社區內的Hive以及Spark的一些優化器基本上都是基於規則的優化器,其實對於優化器而言,單機系統上就存在這樣的分類,分成了基於規則的優化器和基於代價的優化器。

在單機場景裏面,Oracle 6-9i中使用的是基於規則的優化器,在Oracle 8開始有了基於代價的優化器,而Oracle 10g則完全取代了之前基於規則的優化器;而在大數據場景裏面,像Hive最開始只有基於規則的優化器,而新版的Hive也開始引入了基於代價的優化器,但是Hive中還並不是正真意義上的代價優化器。而MaxCompute則使用了完全的基於代價的優化器。那麼這兩種優化器有什麼區別呢?其實基於規則的優化器理論上會根據邏輯模式的識別進行規則的轉換,也就是識別出一個模式就可能觸發一個規則將執行計劃從A改成B,但是這種方式對數據不敏感,並且優化是局部貪婪的,就像爬山的人只看眼前10米的範圍內哪裏是向上的,而不考慮應該先向下走才能走到更高的山頂,所以基於規則的優化器容易陷入局部優但是全局差的場景,容易受應用規則的順序而生產迥異的執行計劃,所以往往結果並不是最優的。而基於代價的優化器是通過Volcano火山模型,嘗試各種可能等價的執行計劃,然後根據數據的統計信息,計算這些等價執行計劃的“代價”,最後從中選用代價Cost最低的執行計劃,這樣可以達到全局的最優性。
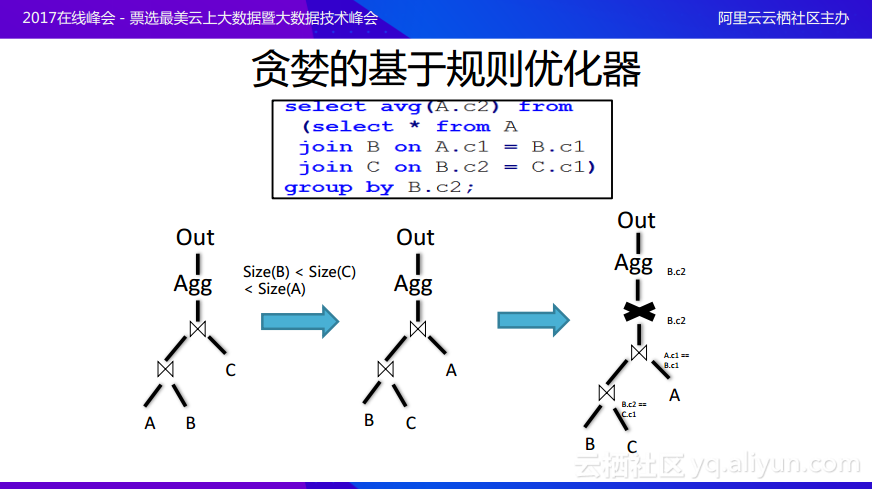
這裏分享一個具體的例子幫助大家理解爲什麼基於規則的優化器無法實現全局的最優化。上圖中的這段腳本的意思就是先在A、B和C上面做完join,join出來的結果在某一列上面進行group by操作並計算出平均值。可以將上述的查詢過程畫成樹形的邏輯執行計劃,在數據庫領域往往是bottom-up的,也就是對於邏輯計劃樹而言,葉子節點是輸入,最終的目標輸出則是根節點,所以最終的數據流向是從下向上的。可以看到在這個邏輯計劃裏面,首先是對於A、B、C三個表進行join,假設Size(B)<Size(C)<Size(A),也就是B、C這兩張表的大小是比A小的,這樣就可以獲得另一種執行的方案就是先將B和C進行join之後再與A進行join,這之後再進行計算平均值,這樣的做法B和C join的中間結果從概率上面就會比較小,再與A join之後最終產生的結果規模也就會比較小,但是後面還需要對於B的c2列計算平均值,所以如果先做完B和C的join,而在第二次join時需要按照join的條件進行partition分區,需要按照A表的c1列和B表的c1列進行分區,但是後面需要在B表的c2列上計算平均值,這時候就會引入一個改變。因爲在做完join之後,其實partition分區是在A表或者B表的c1上面的,但是要做的group by卻是在B表的c2上面的,所以需要引入exchange,這樣就會引入額外的data shuffling。而如果A、B、C三張表的大小差別並不大,其實就可以先讓A和B進行join之後再與C進行join,這樣第二次join正好是在B的c2列上進行的,所以在接下來進行計算平均值的時候就不需要引入額外的data shuffling,雖然進行join的時候代價比原來高,但是因爲省去了一次data shuffling,所以從全局上來看則是更爲優化的,這個例子就說明了基於規則的優化器可以得到基於局部優化,但是可能無法得到全局的優化。
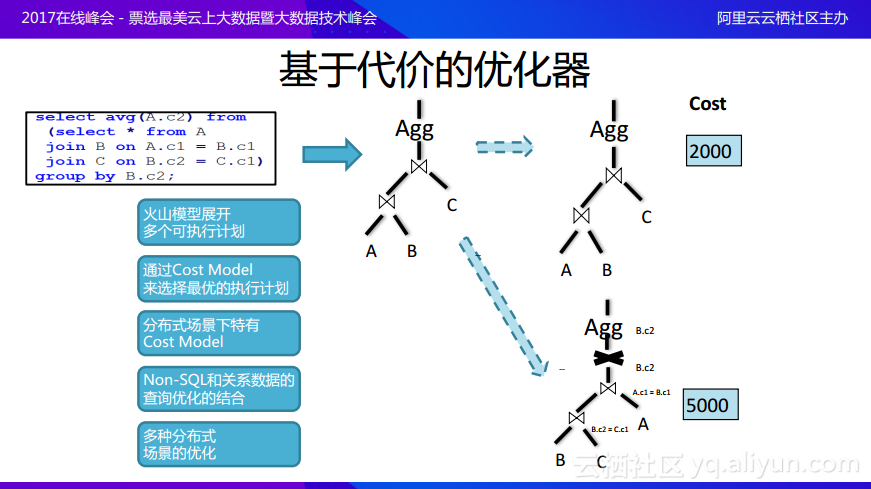
基於代價的優化器則採用了不同的方案,它首先通過火山模型將查詢展開成爲多個等價的可執行計劃。例子中可以先讓A和B join之後再join C或者先讓B和C join之後再join A,在這兩個計劃中,因爲下面的計劃中多了一個exchange,而對於基於代價的優化器而言會在最後面有一個Cost代價模型,通過計算髮現第一個計劃在Cost上面更優,所以就會選擇最優的計劃進行執行。在基於代價的優化器中做了很多分佈式場景之下特有的Cost模型,並且考慮到了Non-SQL,因爲很多場景是與互聯網有關的應用,用戶需要很多Non-SQL的支持,所以可以通過用戶自定義函數幫助用戶實現一些Non-SQL與關係數據結合的查詢優化,最後還有一些多種分佈式場景的優化,這也是基於代價的優化器區別於單機優化器所做的一些工作。
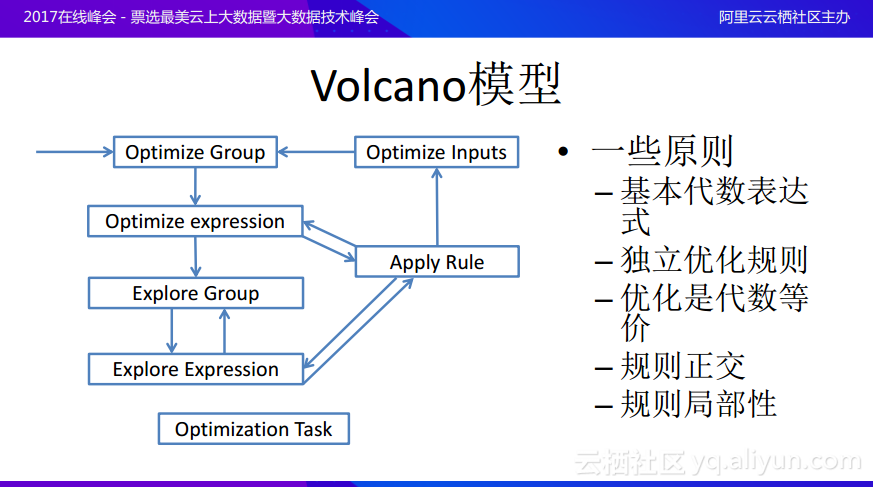
接下來分享一下Volcano火山模型的相關,其實Volcano模型是代價模型的一個引擎,這個引擎其實在單機系統上面就已經提出來了。Volcano模型裏面也會有一些規則,但是與基於規則的優化器中的規則不同,這裏面的規則更像是一些轉化函數。Volcano模型首先會對於邏輯執行計劃進行分組,之後在組上面要完成一件工作,就會先在組裏面探索局部的表達式,然後根據一些規則應用一些變換,這些變換原則上都是代數等價的,在每次進行等價變化的時候其實並不是取代原來的邏輯執行計劃樹,而是在原本的基礎之上分裂出新樹。所以最後將會出現很多個等價的執行計劃樹,最終可以通過基於代價的優化器去選取最好的執行計劃。Volcano模型的原則是首先希望每個規則更加局部性,也就是局部性和正交的規則越好,就越能夠使得對於空間探索得更加全面。舉個例子,如果在平面上定義了前後左右四個方向,那麼就可以通過這四個方向搜索整個二維平面的任何一個點,同樣的優化問題就是在空間裏選取最好的計劃,那麼就希望在每一次變化時候的探索規則都能夠正交,這樣就可以用更少的規則去探索整個空間,這樣如何去探索空間和選取探索最優路徑就可以交給引擎了。
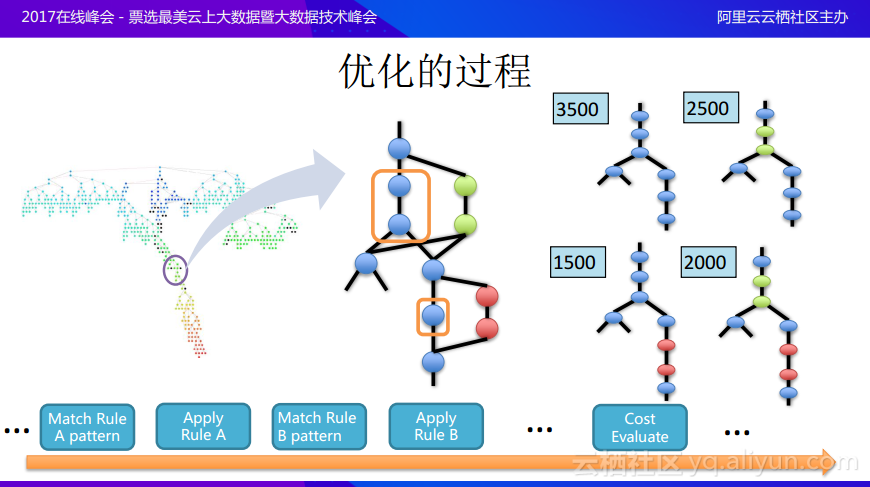
前面分享的比較抽象,這裏進一步進行舉例說明,希望能夠加深大家對於優化過程的理解。假設有一個非常複雜的邏輯執行計劃樹,這就是真正需要做的用戶的任務,現在將其中一小部分提取出來,在進行計劃的優化時首先會分析有沒有已有的規則可以與模式匹配,假設圖中的兩個節點正好能與模式匹配,一個是filter一個是project,理論上filter想要推到葉節點,也就是越早進行filter越好,現在就有一個模式:如果filter出現在project之上,也就是需要先做filter之後進行project,這樣就可以轉換成另一種計劃,將這兩個節點變成新的節點,也就是可以將filter和project換順序,這樣就是應用規則的過程。同樣的還有另外一個節點,比如是aggregate操作能夠與其他的模式匹配,之後就可以尋找對應的規則,並轉化出等價的節點操作,這樣就可以通過複用一棵樹節點的模式來維護多棵樹,在這裏例子中可以看到使用了兩個規則,看上去節點上是隻是一個存儲,但是實際上卻描述了四棵等價樹。之後會對於這四棵等價樹花費的代價進行計算,最後選取花費代價最低的樹作爲執行計劃。整體的基於代價的優化過程就是這樣,但是可以看到當邏輯計劃樹規模很大並且規則變化有很多種的情況下,整個的探索空間還是非常龐大的,所以需要在很多因素上對於優化過程進行考慮。
接下來爲大家介紹一下優化引擎的大致算法,下圖是簡化後的優化引擎算法,而在真正實施時還有很多需要考慮的因素下圖中並沒有表示出來。
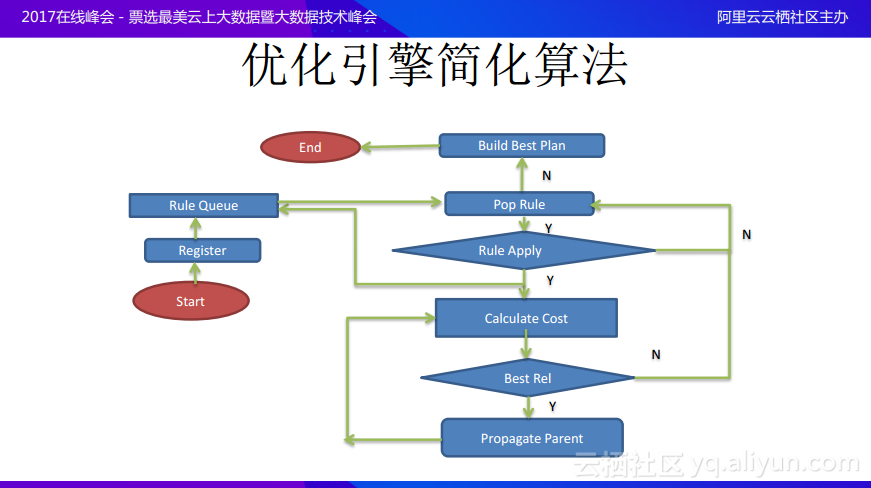
首先會將一個邏輯執行計劃中的所有邏輯節點都註冊進去,註冊進去的同時就會將規則與已有的邏輯模式進行匹配,然後將匹配成功的規則推到規則隊列裏面,然後循環地彈出規則隊列中的規則,並真正地應用這個規則。當然應用規則存在兩種條件,一種就是應用之後能夠產生等價樹,也就是能夠在樹的局部分裂出另外一種樹形狀態,而在分裂出來的樹上面也可能與其他的模式匹配,如果局部範圍內的全部規則都已經匹配完成,就可以開始計算花費的代價。而當通過計算代價得出最佳方案之後,就可以放棄在該局部進行繼續優化,如果認爲當前的計劃仍然不是最優的,就可以將該Cost記錄下來,繼續優化樹的其他部分,直到最終找到最佳計劃。
分佈式查詢中的優化問題實例
在這裏給大家列舉一些在分佈式系統中有別與單機系統中分佈式查詢中的優化問題的實例。
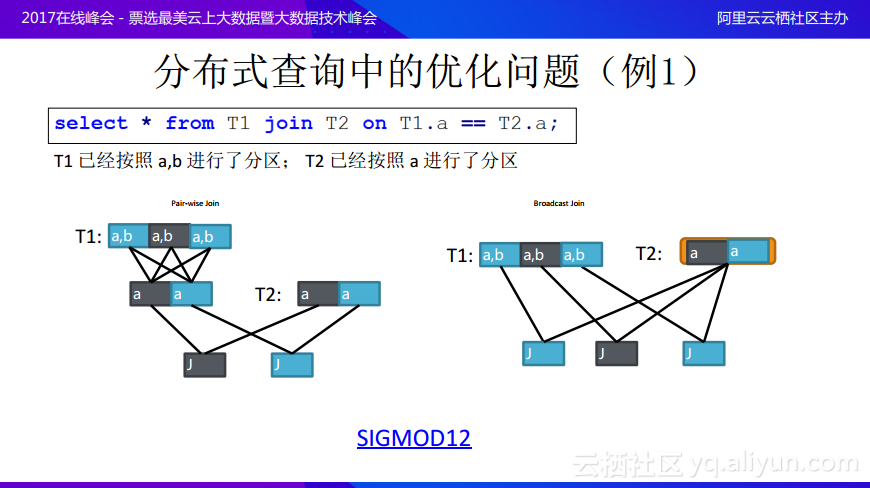
例1其實很簡單,就是對於兩個表進行join操作,T1已經按照a,b進行了分區;T2已經按照a進行了分區,join的條件就是T1.a=T2.a。一種方法因爲T1是按照a和b分區好的,join條件在a上面,所以需要對於T1按照a重新進行分區之後再與T2進行join。但是如果T1表非常大,遠遠大於T2表的規模,這時候就不想將T1按照重新進行分區,反而可以採用另一種方案,就是將T2作爲一個整體,將T2的所有數據廣播給T1每一個數據,因爲join條件是在a上面做內連接,所以可以做這樣的選擇,這樣就可以避免將很大的數據進行reshuffle。在這個場景中,如何去感知join的條件是關鍵。上圖例子中的兩個計劃並不存在絕對的最優,而是需要根據的數據的大小、T2數據量以及T1數據分片的分佈情況來決定哪一種方案纔是最優解,對於這個問題在SIFMOD12上面有很多的論文進行了討論,在此就不再展開詳細的敘述。
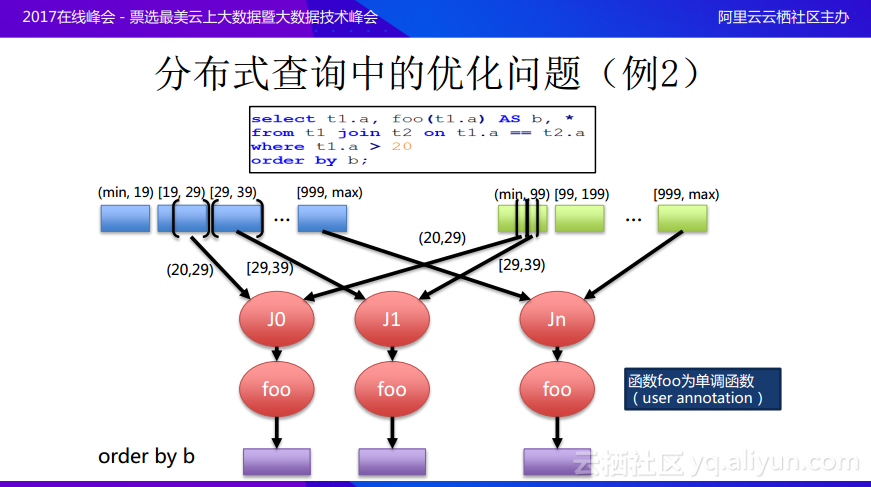
再分享分佈式優化問題的裏另外一個例子,如圖所示,T1和T2還是在a上面進行join,join完成之後會有一個條件限制T1.a>20,完成之後會進行project,並將完成的結果當做新的一列b,最終希望所有的結果是order by b的。T1和T2都是range partition好了,這裏不是hash partition,而且因爲已經進行了global sort,所以這裏在做join的時候就可以利用到兩個表之間的range partition boundary,而不需要重新reshuffle數據,比如目前已經知道大於20會在哪些分區裏面出現,可以根據選擇的boundary去讀取相應的數據之後進行作爲,可以儘量避免數據shuffling,在做完join之後,還會有一個用戶定義方法,將這個方法出來的結果按照order by b的規則進行排序,假設這個foo()方法是單調遞增的函數,這樣就可以利用上面的條件也就是已經按照範圍分區好了,經過join和foo()還能保存b的順序,就不用引入一個exchange,可以直接order by b操作。這樣就是分佈式中的一個查詢優化,也就是如果能夠理解數據裏面的分片,能夠知道數據的分佈式情況還能理解用戶的自定義函數方法,以及這些方法通過什麼樣的途徑與優化器進行互動,就可以對於分佈式查詢進行優化。這其實是通過了用戶的Annotation就可以知道用戶的方法具有什麼樣的特性,能夠保持什麼樣的數據屬性。
用戶自定義函數UDF
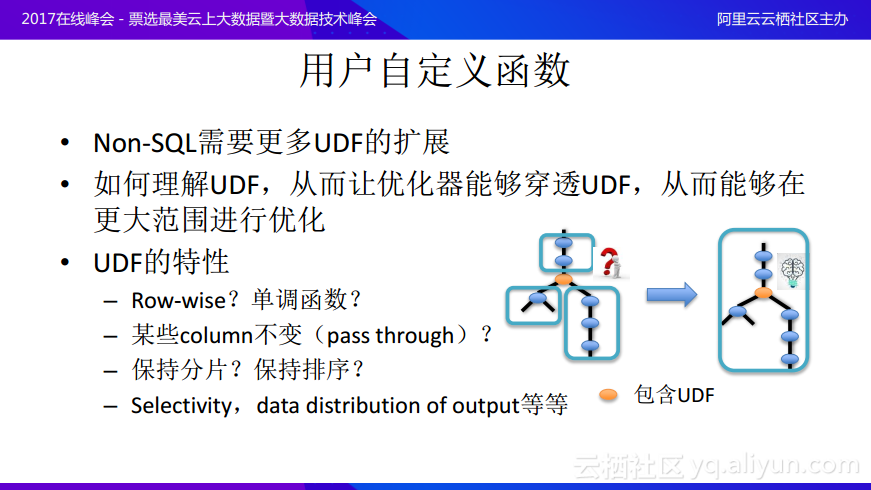
在分佈式系統特別是Non-SQL中需要大量的用戶定義函數來進行擴展,因爲很多查詢過程不是像join和aggregate這麼簡單的,而需要對於很多比較獨特的功能進行建模,所以需要用戶自定義的函數實現。一旦有了用戶自定義的函數,優化器往往難以理解UDF,那麼優化的範圍將會極大地受到限制,如上圖中的中間黃色的節點包含了用戶自定義的函數,但是可能系統並不知道這個函數所做的事情,那麼在優化的時候就可能分成三個更小的可優化片段,在在三個小片段中進行進一步優化。如果優化器能夠理解用戶自定義的函數在做什麼事情,那麼就可以讓優化器穿透UDF達到更大範圍的優化。那麼UDF有什麼特性能夠幫助優化器穿透它呢?其實可以分析UDF是不是Row-wise操作的,考慮它是不是一行一行處理,不存在跨行的,考慮UDF是不是單調函數,是不是在處理時有些列是不變的,也就是可以穿透的,它是不是可以保持數據分片或者保持排序,以及在Cost上面的一些信息,它的Selectivity高還是低,以及data distribution of output是多還是少等等都能優化器更好地優化,爲優化器打開更大的優化空間,實現更加靈活的優化,幫助Cost模型選出更優的方案。這也是阿里巴巴目前在MaxCompute優化器上正在做的一些工作。
優化規則
MaxCompute基於代價的優化器做了大量的優化,實現如下圖所示的各種優化,這裏就不展敘述開了。可以從下圖中看到在查詢中有很多優化可以去做,這些所有的優化在整個系統引擎上面都是一個個算子,這些算子也在變化圖,產生了很多個等價的樹,由優化的引擎通過Cost模型去選擇最佳的方案。

Cost模型
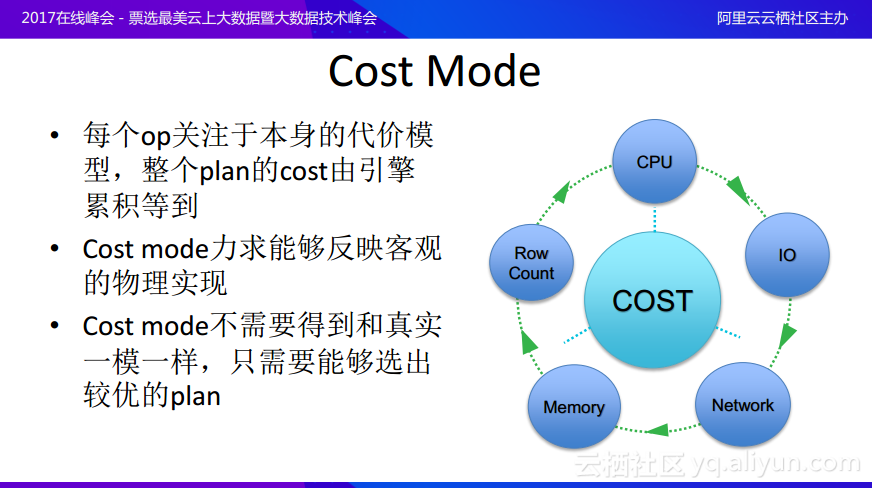
什麼是Cost模型呢?其實Cost模型最需要關注的就是本身的代價模型。每個Cost模型都需要關注於局部,比如input是什麼樣的Cost,經過join之後又會得到什麼樣的Cost,而不需要關注於全局,全局方案的Cost則是由引擎通過累計得到的整體Cost。好的Cost模型力求能夠反映客觀的物理實現,Cost模型不需要得到和真實一模一樣,Cost模型的最終目的是希望區別方案的優劣,只需要能夠選出較優的計劃,並不需要Cost的絕對值具有什麼樣的特性。現在傳統的數據庫的Cost模型還是很早以前的模型,就算硬件結構已經發生了變化,只要還是馮諾依曼體系結構,架構沒有發生改變,Cost模型就可以用於選擇最優的方案。
其實優化器還有很多其他方面的因素可以考慮,比如在規則方面,需要根據規則進行等價的變換,最後根據Cost模型選取最優的方案。隨着邏輯計劃規模的變大,如果枚舉所有可能的方案就會極大地耗費時間,特別是在MaxCompute上希望邏輯執行計劃越大越好,因爲這樣就能給優化引擎更大的空間,但是這就帶來當枚舉所有的計劃時,有些枚舉的計劃其實是不必要的,可能已經處於在一個不優化的情況下了。所以如何去做有效的剪枝,如何去避免不必要的探索空間,也是實現一個好的優化器所需要考慮的。另外對探索空間的選擇,可以將時間用在最有可能是最優化的計劃的空間上面,這可能是一個比較好的選擇,因爲不能希望通過NP-hard的時間去選擇最優的計劃,而應該希望在有限的時間內選取比較好的執行計劃,所以在優化領域中其實不一定需要尋找最佳的方案,而是要避免最差的方案,因爲在優化上面總會存在時間約束。
爲什麼基於代價的優化器對於MaxCompute平臺越來越重要了呢?

這是因爲阿里巴巴希望能從Hive的一條條查詢語句中走出來,提供更加複雜的存儲過程。在上圖中有一個展示,可以通過變量賦值以及預處理if-else編寫出更加複雜的查詢過程和存儲過程,而基於規則的優化器會因爲貪婪算法而越走越偏,最終很可能得不到全局最優方案,而邏輯計劃的複雜化使得可以優化的空間變大了,但是同時也使得對於優化器的要求變得更高,所以需要更好的基於代價的優化器幫助選擇比較好的執行計劃。而在分佈式以及Non-SQL等新型的場景下,使用基於代價的優化器有別於傳統單機優化器的方式,所以需要有對於數據、運算和用戶更加深刻的理解來使得基於代價的優化器更加智能。
理解數據

那麼展開來看,什麼叫做理解數據呢。在數據格式方面,理解數據需要對於更多的數據索引以及異構的數據類型進行理解,對於結構化的數據、非結構化的數據以及半結構化的數據都進行理解,而在大數據的場景裏面數據是有一些Power-law屬性的,有百萬稀疏列的表格,需要在這樣的場景下實現一個更好的優化;理解數據也需要理解豐富的數據分片方式,這是在分佈式場景中才有的,數據分片可以是Range/Hash/DirectHash的,而存儲可以是Columnstorage/Columngrouping的,還需要用Hierarchy Partition來進行分級分區;還會需要理解完善的數據統計信息和運行時數據,需要理解Histogram、Distinct value以及Data Volume等等。
理解運算

從理解運算方面,需要更加理解用戶自定義的函數,能夠與優化器進行互動,更夠讓用戶通過Annotation的方式顯示在運算中數據的屬性上具有的特性,使得可以進行全局範圍的優化。在運行時也會進行更多的優化,比如會在中間運行到一定階段時需要判斷數據量的大小,根據數據量的大小進行並行化的選擇,並根據數據的位置選擇網絡拓撲上的優化策略。還可以做實時性,規模性,性能,成本,可靠性之間的平衡,並且使用網絡Shuffling做內存計算以及流計算等。
理解用戶

從理解用戶的角度,需要理解在優化器上的用戶場景,理解多租戶場景下用戶對規模,性能,延時以及成本不同需求等,並在這樣的場景下讓優化器選取最佳的方案;在生態上面,優化器是核心的優化引擎,希望能夠在語言上面更多地開放,希望能與更多的語言和生態進行對接,也希望能夠提供強大的IDE能來爲開發者提供完整的開發體驗;最後希望能夠在統一的平臺上提供多種運算的模式,使得優化器真正能夠成爲運算的大腦。
文章轉自雲棲社區