認識Scrapy
Scrapy,Python開發的一個快速、高層次的屏幕抓取和web抓取框架
用於抓取web站點並從頁面中提取結構化的數據
Scrapy用途廣泛,可以用於數據挖掘、監測和自動化測試
Scrapy吸引人的地方在於它是一個框架,任何人都可以根據需求方便的修改
它也提供了多種類型爬蟲的基類
如BaseSpider、sitemap爬蟲等,最新版本又提供了web2.0爬蟲的支持Scrapy 架構
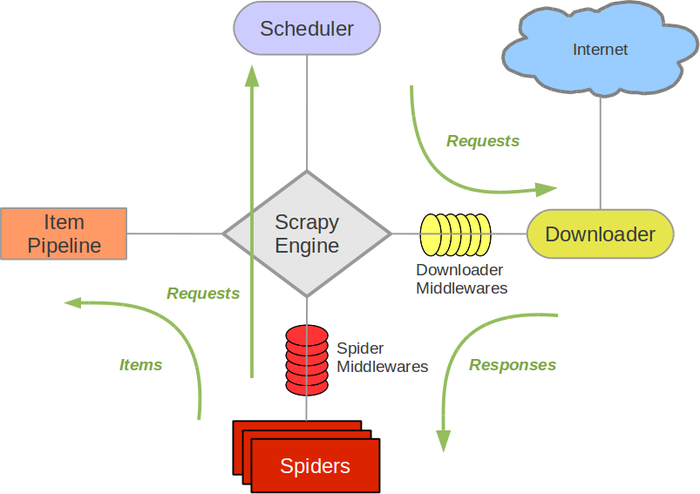
Scrapy Engine(引擎): 分配任務給其他模塊,負責其它模塊之間的通信,數據傳遞等
Scheduler(調度器): 接受引擎發送的Request請求,整理入隊,當需要時返回給引擎
Downloader(下載器): 從引擎處接收並下載調度器整理後返回的Requests請求,並將獲取的Responses返回給引擎
Spider(爬蟲): 提供初始網址,接收並處理從引擎處接收下載器返回的Responses
分析並提取Item需要的數據返回給管道,並將需要跟進的網址url提交給引擎
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行進行後期處理(詳細分析、過濾、存儲等)的地方。
Downloader Middlewares(下載中間件): 你可以當作是一個可以自定義擴展下載功能的組件
Spider Middlewares(Spider中間件): 你可以理解爲是一個可以自定擴展和操作引擎和Spider中間通信的功能組件
(比如進入Spider的Responses;和從Spider出去的Requests)流程:
->Spider 提交初始爬取網址相關信息給Engine
->Engine根據Spider提交的數據發起Requests給Scheduler
->Scheduler將接收到的Requests進行整理入隊,再返還給Engine
->Engine將整理後的Requests請求發送給Downloader
->Downloader將Requests請求提交給網站服務器並將服務器返回的Responses交給Engine
->Engine將Responses交給Spider進行處理
->Spider將從Responses中提取Item字段需要的信息和需要跟進的url
信息交給pipelines,url則提交給Engine,進行下一次爬取
->pipelines將完成對信息的分析,篩選和存儲等工作。
在Scheduler整理的Requests請求隊列全部執行並處理完畢後,程序結束。簡化流程:
由於在Engine主要用於個模塊之間的信息傳遞,可以簡化工作流程如下:
Spider發送初始url ---------------> Scheduler整理請求併入隊(Engine發起請求)
Scheduler 發送整理後的請求 ----------------->Downloader向網址提交請求並獲取responses
Downloader發送獲取的responses ------------------>Spider分析並提取Item所需信息和需要跟進的url
Spider發送Item所需信息 ----------------->pipelines分析,篩選,存儲信息
Spider發送需要跟進的url -----------------> Scheduler整理請求併入隊(Engine發起請求)利用Scrapy製作爬蟲
安裝Scrapy
pip install scarpy實現步驟
1.新建項目 (scrapy startproject projectname)
2.確定目標 (編寫items.py)(即編寫需要獲取的Item字段)
3.製作爬蟲 (編寫spiders/xxspider.py)(分析responses並提取數據)
4.存儲內容 (編寫pipelines.py)(分析篩選數據並儲存)1.新建項目
命令:scrapy startproject projectname
projectname爲需要指定的項目名
進入項目並利用tree命令輸出項目結構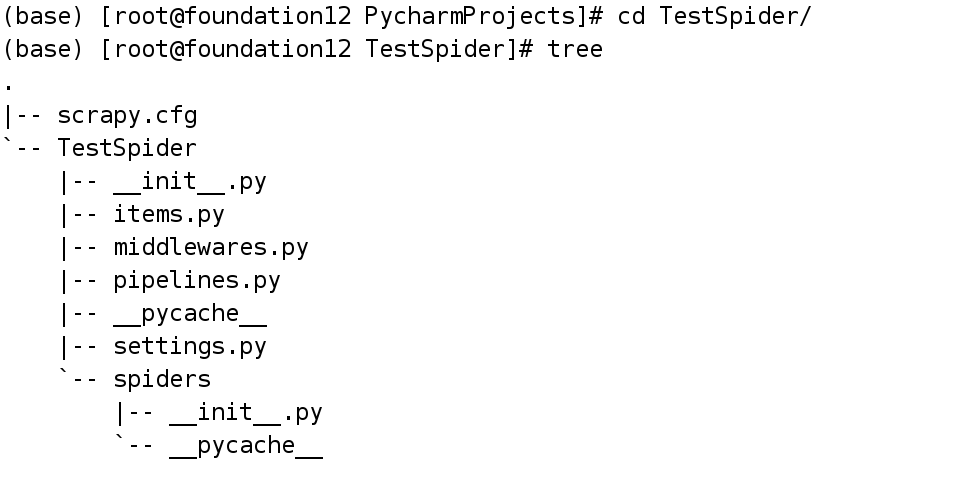
各文件作用
scrapy.cfg: 項目的配置文件。
TestSpider/: 項目的Python模塊,將會從這裏引用代碼。
TestSpider/items.py: 項目的目標文件。
TestSpider/pipelines.py: 項目的管道文件。
TestSpider/settings.py: 項目的設置文件。
TestSpider/spiders/: 存儲爬蟲代碼目錄。2.確定爬取目標(編寫items.py)
我們以爬取菜鳥教程爲例,網址: http://www.runoob.com/
需要的數據爲 教程名 圖片url 簡要描述 教程url
編輯items.py如下:
Item定義了一個結構化數據字段,類似於字典,用於保存爬取到的數據import scrapy
class TestspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() # 教程名
img_url = scrapy.Field() # 圖片地址
desc = scrapy.Field() # 描述
url = scrapy.Field() # 教程鏈接3.製作爬蟲 (編寫spiders/xxspider.py)
在項目目錄中輸入命令
命令:scrapy genspider spidername 'start_url'
spidername 爲需要指定的爬蟲名稱
start_url爲初始爬取地址
此時會在spiders目錄中創建spidername.py文件,並添加必須的代碼
import scrapy
class RunoobSpider(scrapy.Spider):
name = 'runoob'
allowed_domains = ['www.runoob.com']
start_urls = ['http://www.runoob.com/']
def parse(self, response):
pass當然,使用命令不是必需的,也可以選擇自己創建和編寫
但使用命令幫我們免去了寫一些必須代碼的麻煩
在此基礎上,根據我們的需求編寫爬蟲代碼
編寫代碼如下:import scrapy
# 導入在items中寫好的類
from TestSpider.items import TestspiderItem
# 編寫爬蟲
class RunoobSpider(scrapy.Spider):
name = 'runoob' # 文件名
allowed_domains = ['www.runoob.com'] # 允許訪問的網址
start_urls = ['http://www.runoob.com/'] # 開始訪問的網址
def parse(self, response):
course = TestspiderItem() # 實例化一個Item數據對象
# 獲取class爲"item-top item-1"的節點
courseInfos = response.xpath('//a[@class="item-top item-1"]')
# 遍歷節點
for courseInfo in courseInfos:
# 根據需求提取指定數據並存入Item的對象中
course['url'] = courseInfo.xpath('@href')[0].extract()
course['name'] = courseInfo.xpath('.//h4/text()')[0].extract()
course['img_url'] = courseInfo.xpath('.//img/@src')[0].extract()
course['desc'] = courseInfo.xpath('.//strong/text()')[0].extract()
# 輸出測試文件觀察獲取數據是否正確
#open('test.log','w').write('%s\n%s\n%s\n%s'%(type(course['url']),course['name'],type(course['img_url']),type(course['desc'])))
# 返回數據
yield course查看test.log中的數據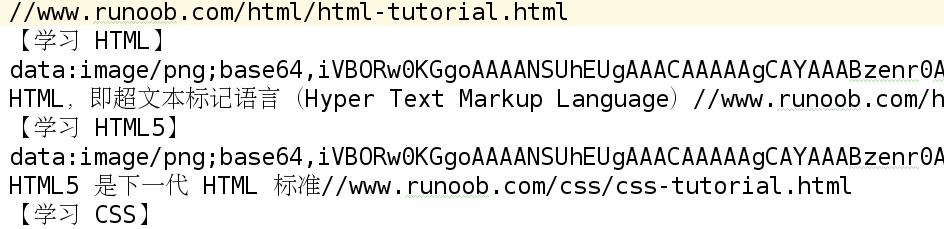
4.存儲內容 (編寫pipelines.py)
(1)使用命令存儲:
scrapy crawl spidername -o spidername.(json|jsonl|csv|xml)
以json / json lines / csv / xml格式存儲在當前路徑下
存儲的csv文件,默認按照ASCII碼編碼順序排列
(2)編寫pipelines.py(需要設置setting)自定義存儲
定義一個管道類,完成寫入操作
>>>>>>>>
保存至文件,保存json格式數據,文件名爲runoob.txtclass TestspiderPipeline(object):
# 以‘只寫’方式打開runoob.txt文件
def __init__(self):
self.f = open('runoob.txt','w')
# pipeline中執行的程序
def process_item(self, item, spider):
# 測試語句,item返回的是獲取到的Item數據類型(前面定義過的類型)
# open('runoob.log','w').write(str(type(item)))
# 存儲爲json格式,不使用ascii編碼,縮進爲4
import json
line = json.dumps(dict(item),ensure_ascii=False,indent=4)
self.f.write(line+'\n')
return item
# 關閉文件
def close_spider(self):
self.f.close()
>>>>>>>>
保存至mysql數據庫
創建數據庫runoob並指定utf8編碼格式(create database runoob default charset=utf8;)
class MysqlPipeline(object):
def __init__(self):
# 構造時鏈接數據庫
import pymysql
self.conn =pymysql.connect(
host='localhost',
user='root',
password ='redhat',
database ='runoob',
charset ='utf8',
autocommit = True
)
# 創建遊標
self.cur = self.conn.cursor()
# 創建數據表
create_sqli = 'create table if not exists course(教程名稱 varchar(50),鏈接 varchar(300),教程簡介 varchar(200))'
self.cur.execute(create_sqli)
def process_item(self, item, spider):
# 插入數據
insert_sqli = 'insert into course values("%s","%s","%s") '%(item['name'],item['url'],item['desc'])
self.cur.execute(insert_sqli)
return item
def close_spider(self):
# 關閉遊標和連接
self.cur.close()
self.conn.close()>>>>>>>>
保存媒體圖片# 圖片存儲
class ImagePipeline(ImagesPipeline):
# 獲取媒體請求
def get_media_requests(self, item, info):
# 測試語句
# open('mooc.log','w').write(item['img_url'])
# 返回圖片
yield scrapy.Request(item['img_url'])
# results是返回的一個元組(True ,{'url':xxx,'path':xxx,'checksum':xxx})
# info返回的是一個對象scrapy.pipelines.media.MediaPipeline.SpiderInfo
def item_completed(self, results, item, info):
# 測試語句
# for i in results:
# open('ni.txt', 'w').write(str(i)+'\n'+str(info))
# 獲取results中的path
image_path = [x['path'] for ok,x in results if ok]
# path爲None,則不包含圖片,否則返回item
if not image_path:
raise Exception('不包含圖片')
else:
return item保存圖片還需要在settings.py中設置圖片保存的路徑
管道默認不執行,需要在settings.py中修改設置
後面的數字設定優先級,數字越小,優先級越高
執行爬蟲並查看保存的數據
執行爬蟲
在工程路徑中輸入命令
命令: scrapy crawl spidername
spidername爲爬蟲文件名查看數據
文件
數據庫
圖片