




Oracle裏存儲的結構化數據導出到Hadoop體系做離線計算是一種常見數據處置手段。近期有場景需要做Oracle到Hadoop體系的實時導入,這裏以此案例做以介紹。
Oracle作爲商業化的數據庫解決方案,自發性的獲取數據庫事務日誌等比較困難,故選擇官方提供的同步工具OGG(Oracle GoldenGate)來解決。
安裝與基本配置
環境說明
軟件配置
| 角色 | 數據存儲服務及版本 | OGG版本 | IP |
|---|---|---|---|
| 源服務器 | OracleRelease11.2.0.1 | Oracle GoldenGate 11.2.1.0 for Oracle on Linux x86-64 | 10.0.0.25 |
| 目標服務器 | Hadoop 2.7.2 | Oracle GoldenGate for Big Data 12.2.0.1 on Linux x86-64 | 10.0.0.2 |
以上源服務器上OGG安裝在Oracle用戶下,目標服務器上OGG安裝在root用戶下。
注意
Oracle導出到異構的存儲系統,如MySQL,DB2,PG等以及對應的不同平臺,如AIX,Windows,Linux等官方都有提供對應的Oracle GoldenGate版本,可在這裏或者在舊版本查詢下載安裝。
Oracle源端基礎配置
將下載到的對應OGG版本放在方便的位置並解壓,本示例Oracle源端最終的解壓目錄爲/u01/gg。
配置環境變量
這裏的環境變量主要是對執行OGG的用戶添加OGG相關的環境變量,本示例爲Oracle用戶添加的環境變量如下:(/home/oracle/.bash_profile文件)Oracle打開歸檔模式
使用如下命令查看當前是否爲歸檔模式(archive)如非以上狀態,手動調整即可
Oracle打開日誌相關
OGG基於輔助日誌等進行實時傳輸,故需要打開相關日誌確保可獲取事務內容。通過一下命令查看當前狀態:如果以上查詢結果非YES,可通過以下命令修改狀態:
Oracle創建複製用戶
爲了使Oracle裏用戶的複製權限更加單純,故專門創建複製用戶,並賦予dba權限最終這個ggs帳號的權限如下所示:
OGG初始化
進入OGG的主目錄執行./ggsci,進入OGG命令行Oracle創建模擬複製庫表
模擬建一個用戶叫tcloud,密碼tcloud,同時基於這個用戶建一張表,叫t_ogg。
目標端基礎配置
將下載到的對應OGG版本放在方便的位置並解壓,本示例Oracle目標端最終的解壓目錄爲/data/gg。
配置環境變量
這裏需要用到HDFS相關的庫,故需要配置java環境變量以及OGG相關,並引入HDFS的相關庫文件,參考配置如下:OGG初始化
目標端的OGG初始化和源端類似進入OGG的主目錄執行./ggsci,進入OGG命令行
Oracle源配置
Oracle實時傳輸到Hadoop集羣(HDFS,Hive,Kafka等)的基本原理如圖: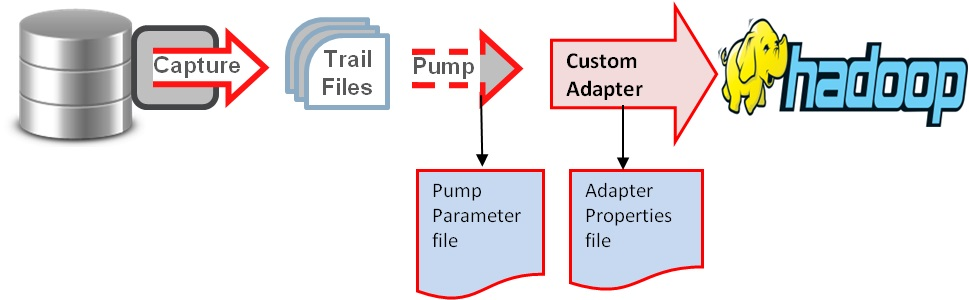
根據如上原理,配置大概分爲如下步驟:源端目標端配置ogg管理器(mgr);源端配置extract進程進行Oracle日誌抓取;源端配置pump進程傳輸抓取內容到目標端;目標端配置replicate進程複製日誌到Hadoop集羣或者複製到用戶自定義的解析器將最終結果落入到Hadoop集羣。
配置全局變量
在源端服務器OGG主目錄下,執行./ggsci到OGG命令行下,執行如下命令:
其中./globals變量沒有的話可以用edit params ./globals來編輯添加即可(編輯器默認使用的vim)
配置管理器mgr
在OGG命令行下執行如下命令:
說明:PORT即mgr的默認監聽端口;DYNAMICPORTLIST動態端口列表,當指定的mgr端口不可用時,會在這個端口列表中選擇一個,最大指定範圍爲256個;AUTORESTART重啓參數設置表示重啓所有EXTRACT進程,最多5次,每次間隔3分鐘;PURGEOLDEXTRACTS即TRAIL文件的定期清理
在命令行下執行start mgr即可啓動管理進程,通過info mgr可查看mgr狀態
添加複製表
在OGG命令行下執行添加需要複製的表的操作,如下:
配置extract進程
配置extract進程OGG命令行下執行如下命令:
說明:第一行指定extract進程名稱;dynamicresolution動態解析;SETENV設置環境變量,這裏分別設置了Oracle數據庫以及字符集;userid ggs,password ggs即OGG連接Oracle數據庫的帳號密碼,這裏使用2.3.4中特意創建的複製帳號;exttrail定義trail文件的保存位置以及文件名,注意這裏文件名只能是2個字母,其餘部分OGG會補齊;table即複製表的表明,支持*通配,必須以;結尾
接下來在OGG命令行執行如下命令添加extract進程:
最後添加trail文件的定義與extract進程綁定:
可在OGG命令行下通過info命令查看狀態:
配置pump進程
pump進程本質上來說也是一個extract,只不過他的作用僅僅是把trail文件傳遞到目標端,配置過程和extract進程類似,只是邏輯上稱之爲pump進程
在OGG命令行下執行:
說明:第一行指定extract進程名稱;passthru即禁止OGG與Oracle交互,我們這裏使用pump邏輯傳輸,故禁止即可;dynamicresolution動態解析;userid ggs,password ggs即OGG連接Oracle數據庫的帳號密碼,這裏使用2.3.4中特意創建的複製帳號;rmthost和mgrhost即目標端OGG的mgr服務的地址以及監聽端口;rmttrail即目標端trail文件存儲位置以及名稱
分別將本地trail文件和目標端的trail文件綁定到extract進程:
同樣可以在OGG命令行下使用info查看進程狀態:
配置define文件
Oracle與MySQL,Hadoop集羣(HDFS,Hive,kafka等)等之間數據傳輸可以定義爲異構數據類型的傳輸,故需要定義表之間的關係映射,在OGG命令行執行:
在OGG主目錄下執行:./defgen paramfile dirprm/tcloud.prm
完成之後會生成這樣的文件/u01/gg/dirdef/tcloud.t_ogg,將這個文件拷貝到目標端的OGG主目錄下的dirdef目錄即可。
目標端的配置
創建目標表(目錄)
這裏主要是當目標端爲HDFS目錄或者Hive表或者MySQL數據庫時需要手動先在目標端創建好目錄或者表,創建方法都類似,這裏我們模擬實時傳入到HDFS目錄,故手動創建一個接收目錄即可hadoop –fs mkdir /gg/replication/hive/
配置管理器mgr
目標端的OGG管理器(mgr)和源端的配置類似,在OGG命令行下執行:
配置checkpoint
checkpoint即複製可追溯的一個偏移量記錄,在全局配置裏添加checkpoint表即可
保存即可
配置replicate進程
在OGG的命令行下執行:
說明:REPLICATE r2hdfs定義rep進程名稱;sourcedefs即在3.6中在源服務器上做的表映射文件;TARGETDB LIBFILE即定義HDFS一些適配性的庫文件以及配置文件,配置文件位於OGG主目錄下的dirprm/hdfs.props;REPORTCOUNT即複製任務的報告生成頻率;GROUPTRANSOPS爲以事務傳輸時,事務合併的單位,減少IO操作;MAP即源端與目標端的映射關係
其中property=dirprm/hdfs.props的配置中,最主要的幾項配置及註釋如下:
具體的OGG for Big Data支持參數以及定義可參考地址
最後在OGG的命令行下執行:
將文件與複製進程綁定即可
測試
啓動進程
在源端和目標端的OGG命令行下使用start [進程名]的形式啓動所有進程。
啓動順序按照源mgr——目標mgr——源extract——源pump——目標replicate來完成。
檢查進程狀態
以上啓動完成之後,可在源端與目標端的OGG命令行下使用info [進程名]來查看所有進程狀態,如下:
源端:
目標端:
所有的狀態均是RUNNING即可。(當然也可以使用info all來查看所有進程狀態)
測試同步更新效果
測試方法比較簡單,直接在源端的數據表中insert,update,delete操作即可。由於Oracle到Hadoop集羣的同步是異構形式,目前尚不支持truncate操作。
源端進行insert操作
查看源端trail文件狀態
查看目標端trail文件狀態
查看HDFS中是否有寫入
注意:從寫入到HDFS的文件內容看,文件的格式如下:
很明顯Oracle的數據已準實時導入到HDFS了。導入的內容實際是一條條的類似流水日誌(具體日誌格式不同的傳輸格式,內容略有差異,本例使用的delimitedtext。格式爲操作符 數據庫.表名 操作時間戳(GMT+0) 當前時間戳(GMT+8) 偏移量 字段1名稱 字段1內容 字段2名稱 字段2內容),如果要和Oracle的表內容完全一致,需要客戶手動實現解析日誌並寫入到Hive的功能,這裏官方並沒有提供適配器。目前騰訊側已實現該功能的開發。
當然你可以直接把這個HDFS的路徑通過LOCATION的方式在Hive上建外表(external table)達到實時導入Hive的目的。
總結
OGG for Big Data實現了Oracle實時同步到Hadoop體系的接口,但得到的日誌目前仍需應用層來解析(關係型數據庫如MySQL時OGG對應版本已實現應用層的解析,無需人工解析)。
OGG的幾個主要進程mgr,extract,pump,replicate配置方便,可快速配置OGG與異構關係存儲結構的實時同步。後續如果有新增表,修改對應的extract,pump和replicate進程即可,當然如果是一整個庫,在配置上述2個進程時,使用通配的方式即可。
附錄
OGG到Hadoop體系的實時同步時,可在源端extract和pump進程配置不變的情況下,直接在目標端增加replicate進程的方式,增加同步目標,以下簡單介紹本示例中增加同步到Kafka的配置方法。
本示例中extract,pump進程都是現成的,無需再添加。只需要在目標端增加同步到Kafka的replicate進程即可。
在OGG的命令行下執行:
replicate進程和導入到HDFS的配置類似,差異是調用不同的配置dirprm/r2kafka.props。這個配置的主要配置如下:
r2kafka.props引用的custom_kafka_producer.properties定義了Kafka的相關配置如下:
以上配置以及其他可配置項可參考地址:
以上配置完成後,在OGG命令行下添加trail文件到replicate進程並啓動導入到Kafka的replicate進程
檢查實時同步到kafka的效果,在Oracle源端更新表的同時,使用kafka客戶端自帶的腳本去查看這裏配置的ggtopic這個kafkatopic下的消息:
目標端Kafka的同步情況:
顯然,Oracle的數據已準實時同步到Kafka。從頭開始消費這個topic發現之前的同步信息也存在。架構上可以直接接Storm,SparkStreaming等直接消費kafka消息進行業務邏輯的處理。
從Oracle實時同步到其他的Hadoop集羣中,官方最新版本提供了HDFS,HBase,Flume和Kafka,相關配置可參考官網給出的例子配置即可。
版權聲明:本文由王亮原創文章,轉載請註明出處:
文章原文鏈接:https://www.qcloud.com/community/article/220