




什麼是socket
Socket(也稱作套接字)是一組接口,是應用層與 TCP/IP協議族 通信的中間軟件抽象層,它對TCP/IP協議進行了實現,應用層需要網絡通信,直接調用這些接口即可~
從應用層的角度,也可以簡單地將 Socket 理解爲 ip+port,ip用來定位互聯網中的一臺主機,port用來定位該主機上的應用程序,所以通過 ip+port 能夠找到需要通信的另一個程序,通信過程的底層由 Socket 模塊實現~
基於文件類型的套接字
套接字家族名稱:AF_UNIX
基於文件的套接字就是通過對同一個文件的讀寫來完成進程間的通信。若兩個進程運行在同一臺服務器上,使用這種方式來通信效率更高~
基於網絡類型的套接字
套接字家族名稱:AF_INET
跨越網絡的通信使用 AF_INET,還有AF_INET6,用於ipv6。常用的就這幾個,剩下的無需關心~
基於TCP連接的socket
創建TCP連接時,由客戶端主動發起連接,建立連接之後,基於這個連接開始通信。TCP連接是可靠的連接~
服務端
import socket
sk = socket.socket()
sk.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 8888)) # 綁定套接字
sk.listen(10) # 監聽連接,10表示 server 端最多同時響應10個連接
conn, _ = sk.accept() # 接收連接
msg = conn.recv(1024) # 接收 client 端發來的信息
print(msg)
conn.send(b'hi') # 向客戶端發送信息
conn.close() # 關閉連接
sk.close() # 關閉 server端套接字 說明:
setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) 表示對IP地址和端口進行重用,可避免端口已被佔用的問題(上一次服務端程序退出之後,其使用的端口還未完全關閉)
OSError: [Errno 48] Address already in use
這裏的 socket.socket() 省略了默認參數,等同於 socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
family 指定 套接字家族,可以是AF_UNIX或者AF_INET
type 指定套接字類型,是面向連接的(SOCK_STREAM)還是非連接(SOCK_DGRAM),基於TCP的連接使用 SOCK_STREAM,基於UDP的使用 SOCK_DGRAM~
客戶端
import socket
sk = socket.socket()
ip_addr = ('127.0.0.1', 8888)
sk.connect(ip_addr)
sk.send(b'hello')
rece_msg = sk.recv(1024)
print(rece_msg)
sk.close()基於UDP的socket
TCP是基於可靠的連接,並且通信雙方都以流的形式發送數據,相對於TCP,UDP則是面向無連接的協議。
使用UDP協議通信,不需要建立連接,只需要知道對方的IP地址和端口號,就可以直接發送數據包。使用UDP傳輸數據是不可靠的,發送端只管發送,並不會對數據包的到達進行確認,但相對於TCP,它的優點是速度快~
服務端
import socket
udp_sk = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
udp_sk.bind(('127.0.0.1', 8888))
msg, addr = udp_sk.recvfrom(1024) # 接受數據
print(msg)
udp_sk.sendto(u'你好'.encode('utf-8'), addr) # 發送數據
udp_sk.close()創建 socket 時指定套接字類型 爲 socket.SOCK_DGRAM。綁定端口之後(bind),不需要 listen,便可以直接 recvfrom 接受客戶端的數據
客戶端
import socket
udp_sk = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
ip_addr = ('127.0.0.1', 8888)
udp_sk.sendto(b'from udp client', ip_addr)
msg, addr = udp_sk.recvfrom(1024)
print(msg.decode('utf-8'))
udp_sk.close()客戶端創建基於UDP的Socket後,不需要連接(connect),可直接使用sendto發送數據
socket的其他方法介紹
服務端套接字函數
s.bind() 綁定(主機,端口號)到套接字,在AF_INET下,以元組(host,port)的形式表示地址。
s.listen(n) 開始TCP監聽,你表示能同時建立的連接數據
s.accept() 被動接受TCP客戶的連接,(阻塞式)等待連接的到來
客戶端套接字函數
s.connect() 主動初始化TCP服務器連接,一般address的格式爲元組(hostname,port),如果連接出錯,返回socket.error錯誤。
s.connect_ex() connect()函數的擴展版本,出錯時返回出錯碼,而不是拋出異常
公共用途的套接字函數
s.recv(bufsize) 接收TCP數據,數據以bytes形式返回,bufsize指定要接收的最大數據量。
s.send(string) 發送TCP數據,將string(bytes)中的數據發送到連接的套接字。返回值是要發送的字節數量,該數量可能小於string的字節大小。
s.sendall(string) 完整發送TCP數據。將string中的數據發送到連接的套接字,但在返回之前會嘗試發送所有數據。成功返回None,失敗則拋出異常。
s.recvfrom(buffer) 接收UDP數據,與recv()類似,但返回值是(data,address)。其中data是包含接收數據的字符串,address是發送數據的套接字地址。
s.sendto(string, addr) 發送UDP數據,將數據發送到套接字,addr是形式爲(ipaddr,port)的元組,指定遠程地址。返回值是發送的字節數。
s.getpeername() 連接到當前套接字的遠端的地址
s.getsockname() 當前套接字的地址
s.getsockopt() 返回指定套接字的參數
s.setsockopt() 設置指定套接字的參數
s.close() 關閉套接字
面向鎖的套接字方法
s.setblocking() 設置套接字的阻塞與非阻塞模式
s.settimeout() 設置阻塞套接字操作的超時時間
s.gettimeout() 得到阻塞套接字操作的超時時間
面向文件的套接字的函數
s.fileno() 返回套接字的文件描述符
s.makefile() 創建一個與該套接字相關的文件簡單說明一下 send 和 sendall 方法的區別:
上面已經說明 send(string) 方法發送的數據量可能小於string的字節大小,就是說可能無法發送string中的所有數據,所以簡單起見,一般使用sendall方法。如下兩種方式是等價的:
# sendall
sock.sendall('Hello world\n')
# send
buffer = 'Hello world\n'
while buffer:
bytes = sock.send(buffer)
buffer = buffer[bytes:]黏包現象
如下示例是遠程執行命令的程序,客戶端發送命令到服務器端,服務器端執行完成後,將結果返回給客戶端~
服務端
ip_port = ('127.0.0.1', 8888)
BUFSIZE = 1024
tcp_sk_server = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
tcp_sk_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
tcp_sk_server.bind(ip_port)
tcp_sk_server.listen(5)
while True:
conn, addr = tcp_sk_server.accept()
print("from %s:%s" % (addr[0], addr[1]))
while True:
cmd = conn.recv(BUFSIZE) # recv 方法會阻塞,直到接收到數據;若是連接關閉,則會接收一個 b'',程序繼續往後執行
if len(cmd) == 0: break
res = subprocess.Popen(cmd, shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE)
stderr = res.stderr.read()
stdout = res.stdout.read()
if stderr:
send_mes = stderr
else:
send_mes = stdout
conn.sendall(send_mes)客戶端
import socket
ip_port = ('127.0.0.1', 8888)
BUFSIZE = 100
tcp_sk_client = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
tcp_sk_client.connect_ex(ip_port)
while True:
cmd = input(">>: ").strip()
if len(cmd) == 0: continue
if cmd == 'quit': break
tcp_sk_client.send(cmd.encode('utf-8'))
cmd_res = tcp_sk_client.recv(BUFSIZE)
print(cmd_res.decode('utf-8'))
tcp_sk_client.close()注意客戶端接收數據的 BUFSIZE 調整成了100,如下是客戶端執行的返回結果:
>>: ls /tmp
VMwareDnD
com.apple.launchd.Q7QRr2IZct
com.apple.launchd.gOYBDHgesI
powerlog
>>: ifconfig
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
options=1203<RXCSUM,TXCSUM,TXSTATUS,SW_TIM
>>: ls /tmp
ESTAMP>
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 6
>>: 第一個命令 'ls /tmp' 完整的輸出了,但是第二個命令由於其返回數據的長度大於100,只顯示了一部分,剩下沒有顯示的在下一個返回結果中輸出,而下一個命令的返回結果應該還在緩存中,這就是黏包現象
發生黏包現象的原因
TCP協議是基於數據流的,數據發送之後,數據的長度對於客戶端的應用程序而言是不可見的,客戶端程序在從緩衝區提取數據的時候不知道一段數據從哪裏開始到哪裏結束,這就造成了黏包現象。
還有就是TCP協議中的Nagle算法,將多次間隔較小且數據量小的數據,合併成一個大的數據塊,然後進行封包,發送。這也是造成客戶端接收數據時產生黏包現象的原因~
總之面向流的通信(基於TCP協議的通信)是無消息保護邊界的,這是造成黏包的主要原應~
UDP協議是無連接的,面向消息的。由於UDP支持的是一對多模式,接收端的套接字緩衝區採用了鏈式結構來記錄每一個到達的UDP包,在每個UDP包中有消息頭(消息來源地址,端口等信息),這樣,對於接收端來說,就容易進行區分處理了。 即面向消息的通信是有消息保護邊界的。
所以基於UDP協議的通信是不會有黏包現象的。客戶端使用 recvfrom(bufsize) 接收bufsize 大小的數據後,這個消息剩下的數據就丟失了。下一次接收數據從另一個消息的開頭開始提取。而基於TCP協議的通信,客戶端使用 recv(bufsize) 接收 bufsize 大小的數據後,剩下的數據會依舊留在緩存中,下一次接收數據會從上一次結束的地方開始提取~
綜上所述,基於TCP協議的通信,以下兩種情況下會出現黏包:
情況_1
發送端將多次間隔較小且數據量小的數據,合併成一個大的數據塊發送出去,造成接收端的黏包~
服務端(接收端)
import socket
ip_port = ('127.0.0.1', 8888)
BUFSIZE = 1024
sk = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
sk.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sk.bind(ip_port)
sk.listen(5)
conn, addr = sk.accept()
info_1 = conn.recv(BUFSIZE)
info_2 = conn.recv(BUFSIZE)
print('info_1: %s' % info_1.decode('utf-8'))
print('info_2: %s' % info_2.decode('utf-8'))
conn.close()客戶端(發送端)
import socket
ip_port = ('127.0.0.1', 8888)
sk = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
sk.connect(ip_port)
sk.send(b'hello')
sk.send(b'hi')
sk.close()在服務端(接收端)的輸出結果:
info_1: hellohi
info_2: 情況_2
接收端在接收數據時只接收了一部分,下一次接收數據時,會接受到上一次遺留的數據~
服務端(接收端)
import socket
ip_port = ('127.0.0.1', 8888)
# BUFSIZE = 1024
sk = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
sk.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sk.bind(ip_port)
sk.listen(5)
conn, addr = sk.accept()
info_1 = conn.recv(2) # 這裏將 BUFSIZE 僅設置成2字節
info_2 = conn.recv(5)
print('info_1: %s' % info_1.decode('utf-8'))
print('info_2: %s' % info_2.decode('utf-8'))
conn.close()客戶端(發送端)
import socket
ip_port = ('127.0.0.1', 8888)
sk = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
sk.connect(ip_port)
sk.send(b'hello')
sk.send(b'hi')
sk.close()在服務端(接收端)的輸出結果:
info_1: he
info_2: llohi第一次發送的數據出現在下一次的接收中,上述給出的遠程執行命令的程序就屬於這種情況~
解決方式1
解決方式,就是在發送數據前提前通知數據的長度,這樣在接收數據時僅接收指定長度的數據,從而避免黏包~
服務端
import socket
import subprocess
ip_port = ('127.0.0.1', 8888)
BUFSIZE = 1024
tcp_sk_server = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
tcp_sk_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
tcp_sk_server.bind(ip_port)
tcp_sk_server.listen(5)
while True:
conn, addr = tcp_sk_server.accept()
print("from %s:%s" % (addr[0], addr[1]))
while True:
cmd = conn.recv(BUFSIZE)
if len(cmd) == 0: break
res = subprocess.Popen(cmd, shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE)
stderr = res.stderr.read()
stdout = res.stdout.read()
if stderr:
send_mes = stderr
else:
send_mes = stdout
data_length = len(send_mes)
conn.send(str(data_length).encode('utf-8'))
back_data = conn.recv(BUFSIZE).decode('utf-8')
if back_data == 'OK':
conn.sendall(send_mes)
conn.close()客戶端
import socket
ip_port = ('127.0.0.1', 8888)
BUFSIZE = 1024
tcp_sk_client = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
tcp_sk_client.connect_ex(ip_port)
while True:
cmd = input(">>: ").strip()
if len(cmd) == 0: continue
if cmd == 'quit': break
tcp_sk_client.send(cmd.encode('utf-8'))
# 接收長度信息
data_length = int(tcp_sk_client.recv(BUFSIZE).decode('utf-8'))
tcp_sk_client.send('OK'.encode('utf-8'))
cmd_res = b''
recv_length = 0
while recv_length < data_length:
cmd_res += tcp_sk_client.recv(BUFSIZE)
recv_length += BUFSIZE
print(cmd_res.decode('utf-8'))
tcp_sk_client.close()在這個示例中,雖然服務端提前發送了數據的長度信息,但是這個長度信息的長度,客戶端任然不知道,這樣若是發送完數據的長度信息之後,直接發送數據,依舊會存在黏包現象;因爲 數據的長度信息 的數據量很小,發送端在發送的時候可能會將其和後面的部分數據 合併成一個大的數據塊發送出去,接收端不知道 長度信息 的數據長度,兩個數據之間也沒有邊界。
而在這個示例中,發送端在發送完數據的長度之後,接收了客戶端(接收端)的反饋信息(tcp_sk_client.send('OK'.encode('utf-8'))),確認是"OK"之後再發送數據信息。這就相當於 兩個數據之間 有了 邊界(發送端 在發送數據長度 和 發送數據 之間有一個 recv 動作),繞過了黏包問題~
這種解決方式存在一個問題,就是發送端和接收端多了一次交互過程,這可能會放大網絡延遲帶來的性能損耗~
另一種方式就是使用struct模塊來解決黏包問題~
struct 模塊
struct 模塊可以一個類型的數據轉成固定長度的 bytes ~
import struct
struct_num = struct.pack('i', 123)
print(struct_num) # b'{\x00\x00\x00'
num = struct.unpack('i', struct_num)
print(num[0]) # 123'i' 表示 要轉換的類型是 int類型~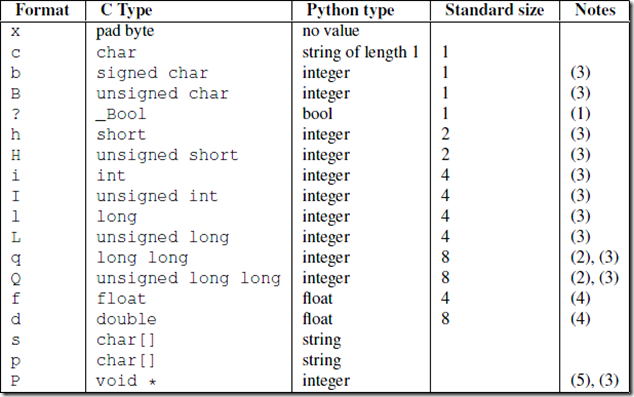
關於struct模塊的具體使用方式可參見:http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html
解決方式2(使用 struct 模塊)
使用struct 模塊,將數據的長度轉換成一個4字節數字。這樣接收端就知道了表示數據長度的數據量的大小,直接接收即可,省去了發送接送反饋信息這一步~
服務端
import socket
import subprocess
import struct
ip_port = ('127.0.0.1', 8888)
BUFSIZE = 1024
tcp_sk_server = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
tcp_sk_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
tcp_sk_server.bind(ip_port)
tcp_sk_server.listen(5)
while True:
conn, addr = tcp_sk_server.accept()
print("from %s:%s" % (addr[0], addr[1]))
while True:
cmd = conn.recv(BUFSIZE)
if len(cmd) == 0: break
res = subprocess.Popen(cmd, shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE)
stderr = res.stderr.read()
stdout = res.stdout.read()
if stderr:
send_mes = stderr
else:
send_mes = stdout
conn.send(struct.pack('i', len(send_mes)))
conn.sendall(send_mes)
conn.close()客戶端
import socket
import struct
ip_port = ('127.0.0.1', 8888)
BUFSIZE = 1024
tcp_sk_client = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
tcp_sk_client.connect_ex(ip_port)
while True:
cmd = input(">>: ").strip()
if len(cmd) == 0: continue
if cmd == 'quit': break
tcp_sk_client.send(cmd.encode('utf-8'))
# 接收長度信息
data_length = struct.unpack('i', tcp_sk_client.recv(4))[0]
cmd_res = b''
recv_length = 0
while recv_length < data_length:
cmd_res += tcp_sk_client.recv(BUFSIZE)
recv_length += BUFSIZE
print(cmd_res.decode('utf-8'))
tcp_sk_client.close()發送端發送完長度信息後,可直接發送數據,因爲接收端知道長度信息的數據量(4字節),可直接接收~
其實解決黏包問題的關鍵就是讓接收端知道將要接收的數據的長度,從而不多不少的接收數據~
socketserver
SocketServer 對 socket 進行了封裝,內部使用 IO多路複用 以及 “多線程” 和 “多進程” ,從而實現併發處理多個客戶端請求的 Socke t服務端。
在 SocketServer 中有這些類:ThreadingTCPServer、TCPServer、ForkingTCPServer 是基於TCP實現的。
TCPServer 並不是併發的,在接收到請求後逐一進行處理,如果前一個的 handle 沒有結束,那麼其他的請求將不會處理。
ThreadingTCPServer 和 ForkingTCPServer 則可以併發處理請求,其實現原理是 沒接收到一個請求就開啓一個線程或者進程進行處理。ThreadingTCPServer 通過建立新線程來運行handle,ForkingTCPServer 則通過建立新進程來運行 handle ~
遠程執行命令的程序 通過 socketserver 來實現
服務端
import socketserver
import subprocess
import json
import struct
IP, PORT = '127.0.0.1', 9999
BUFSIZE = 1024
class MyServer(socketserver.BaseRequestHandler):
def handle(self):
print("hello %s" % self.request)
while True:
cmd = self.request.recv(BUFSIZE)
if len(cmd) == 0: break
res = subprocess.Popen(cmd, shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE)
stderr = res.stderr.read()
stdout = res.stdout.read()
if stderr:
send_mes = stderr
else:
send_mes = stdout
res_heads = {'data_len': len(send_mes)}
res_heads_json = json.dumps(res_heads).encode('utf-8')
self.request.send(struct.pack('i', len(res_heads_json)))
self.request.send(res_heads_json)
self.request.sendall(send_mes)
if __name__ == '__main__':
socketserver.TCPServer.allow_reuse_address = True
server = socketserver.ThreadingTCPServer((IP, PORT), MyServer)
server.serve_forever()客戶端
import socket
import struct
import json
ip_port = ('127.0.0.1', 9999)
BUFSIZE = 1024
tcp_sk_client = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
tcp_sk_client.connect_ex(ip_port)
while True:
cmd = input(">>: ").strip()
if len(cmd) == 0: continue
if cmd == 'quit': break
tcp_sk_client.send(cmd.encode('utf-8'))
# 接收 head 長度信息
head_length = struct.unpack('i', tcp_sk_client.recv(4))[0]
res_heads = json.loads(tcp_sk_client.recv(head_length).decode('utf-8'))
cmd_res = b''
recv_length = 0
while recv_length < res_heads['data_len']:
cmd_res += tcp_sk_client.recv(BUFSIZE)
recv_length += BUFSIZE
print(cmd_res.decode('utf-8'))
tcp_sk_client.close()上述示例中通過一個字典(dict)來標識數據的一些信息(例如長度),發送端在發送數據時,先發送這個字典的長度,再發送這個字典(字典中攜帶了數據長度),最後發送數據信息~
.................^_^