




目錄
1.TextRNN原理概述
在一些自然語言處理任務中,當對序列進行處理時,我們一般會採用循環神經網絡RNN,尤其是它的一些變種,如LSTM(更常用),GRU。當然我們也可以把RNN運用到文本分類任務中。
這裏的文本一般包含若干句子,因此每段文本的長度都不盡相同。在對文本進行分類時,我們一般會指定一個固定的輸入序列/文本長度:該長度可以是最長文本/序列的長度,此時其他所有文本/序列都要進行填充以達到該長度;該長度也可以是訓練集中所有文本/序列長度的均值,此時對於過長的文本/序列需要進行截斷,過短的文本則進行填充。總之,要使得訓練集中所有的文本/序列長度相同,該長度除之前提到的設置外,也可以是其他任意合理的數值。在測試時,也需要對測試集中的文本/序列做同樣的處理。
假設訓練集中所有文本/序列的長度統一爲n,我們需要對文本進行分詞,並使用詞嵌入得到每個詞固定維度的向量表示。對於每一個輸入文本/序列,我們可以在RNN的每一個時間步長上輸入文本中一個單詞的向量表示,計算當前時間步長上的隱藏狀態,然後用於當前時間步驟的輸出以及傳遞給下一個時間步長並和下一個單詞的詞向量一起作爲RNN單元輸入,然後再計算下一個時間步長上RNN的隱藏狀態,以此重複...直到處理完輸入文本中的每一個單詞,由於輸入文本的長度爲n,所以要經歷n個時間步長。
基於RNN的文本分類模型非常靈活,有多種多樣的結構。接下來,我們主要介紹兩種典型的結構。
2.TextRNN的典型結構
- structure v1: embedding--->BiLSTM--->concat final output/average all output----->softmax layer

一般取前向/反向LSTM在最後一個時間步長上隱藏狀態,然後進行拼接,在經過一個softmax層(輸出層使用softmax激活函數)進行一個多分類;或者取前向/反向LSTM在每一個時間步長上的隱藏狀態,對每一個時間步長上的兩個隱藏狀態進行拼接,然後對所有時間步長上拼接後的隱藏狀態取均值,再經過一個softmax層(輸出層使用softmax激活函數)進行一個多分類(2分類的話使用sigmoid激活函數)。
上述結構也可以添加dropout/L2正則化或BatchNormalization 來防止過擬合以及加速模型訓練。
- structure v2: embedding-->BiLSTM---->(dropout)-->concat ouput--->UniLSTM--->(droput)-->softmax layer
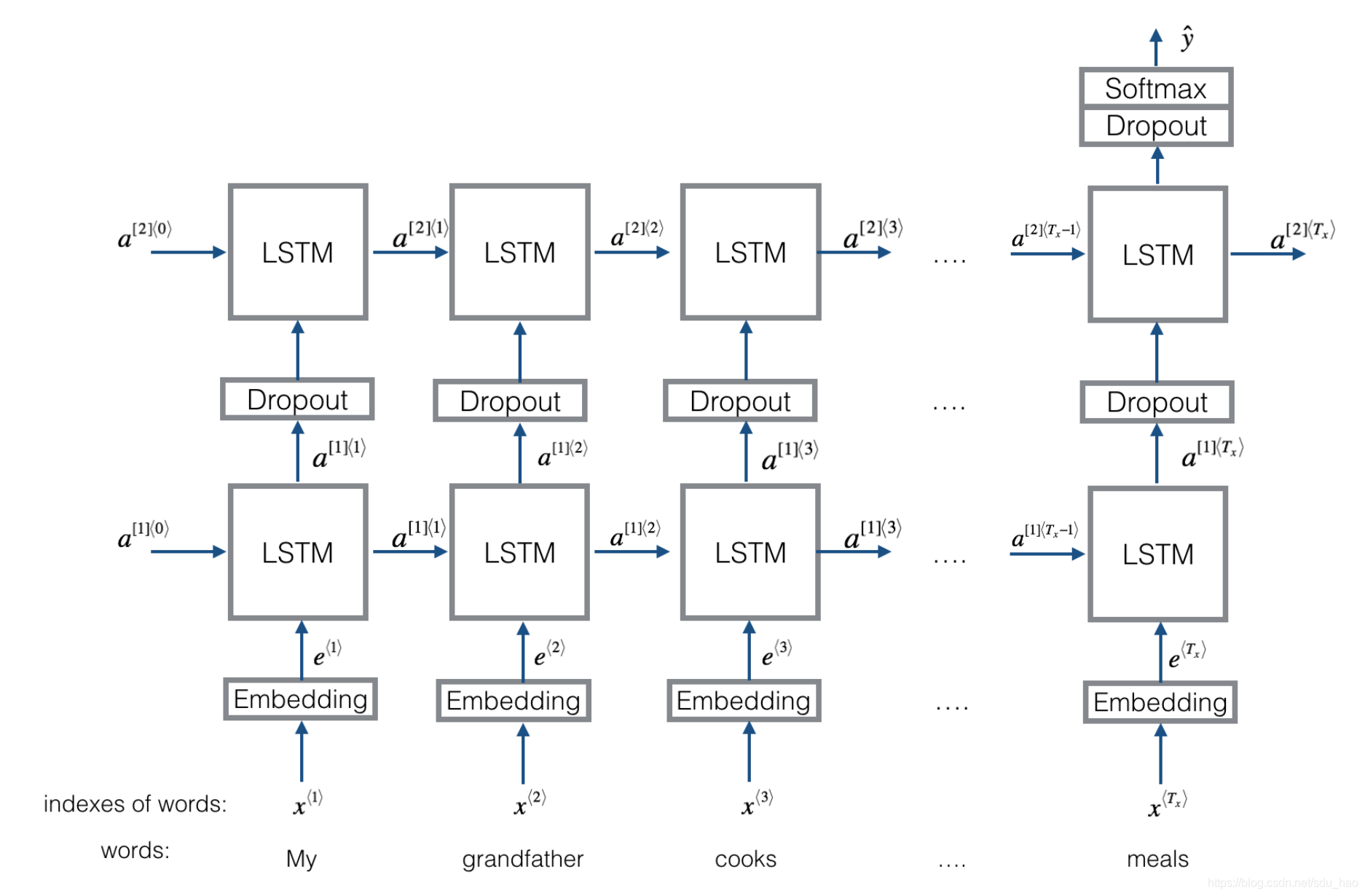
與之前結構不同的是,在雙向LSTM(上圖不太準確,底層應該是一個雙向LSTM)的基礎上又堆疊了一個單向的LSTM。把雙向LSTM在每一個時間步長上的兩個隱藏狀態進行拼接,作爲上層單向LSTM每一個時間步長上的一個輸入,最後取上層單向LSTM最後一個時間步長上的隱藏狀態,再經過一個softmax層(輸出層使用softamx激活函數,2分類的話則使用sigmoid)進行一個多分類。
3.總結
TextRNN的結構非常靈活,可以任意改變。比如把LSTM單元替換爲GRU單元,把雙向改爲單向,添加dropout或BatchNormalization以及再多堆疊一層等等。TextRNN在文本分類任務上的效果非常好,與TextCNN不相上下,但RNN的訓練速度相對偏慢,一般2層就已經足夠多了。