安全漏洞CVE-2019-1002100
3月2日,kubernetes社區公佈了一箇中等程度的安全漏洞CVE-2019-1002100。該漏洞最早由Carl Henrik Lunde發現,並於2月25日在kubernetes發佈issue(#74534)。根據描述,具有patch權限的用戶可以通過發送一個精心構造的patch請求來消耗apiserver的資源,最終會導致apiserver無法響應其他請求。
具體被構造的請求是一個json-patch類型的patch請求,比如kubectl patch --type json或"Content-Type: application/json-patch+json",大家可以通過構造類似的請求檢查自己的apiserver是否有此漏洞。
kubernetes宣佈這是一箇中等嚴重程度的漏洞,並且很快發佈了修復的版本,包括v1.11.8、v1.12.6、v1.13.4,大家可以升級到對應的版本以修復此漏洞。
當然,如果不想升級kubernetes版本的話,也可以規避掉這個問題。只給可信任的用戶發放patch權限就行了。
最後,該漏洞對應的issue和修復pr信息如下,大家可以自行參考學習:

Scheduler相關bug fix分析隨着kubernetes的成熟,集羣規模也越來越大,而在大規模集羣中,scheduler似乎越來越成爲整個集羣的瓶頸。近期的bug fix都有不少是scheduler相關的問題。下面就根據這段時間scheduler相關的bug fix,分析大規模集羣中調度器可能出問題的地方。
#72754 修復
unscheduleable pod過多可能的調度問題該問題的背景是#71486這個issue。加入大規模集羣存在很多暫時不能調度的pod,當有事件更新
時,scheduler會將這些pod放到active隊列重新進行調度,而新加入的pod也會進入這個隊列。這就會導致這個隊列過大,這個隊列本身是按照pod優先級排列,這樣新加入的pod可能會排到同優先級的其他不可調度的pod之後。
由於經常會有事件觸發unscheduleable的pod重新調度,這就可能會導致有些pod一直排不到。
針對這個問題的修復方式就是修改優先級隊列的排序邏輯,這個過程也經過了兩輪優化,最終版本是:
- 默認按照pod優先級排序
- pod優先級相同的話使用pod的podTimestamp排序,時間越早,優先級越高。
而podTimestamp根據pod生命週期的不同會選擇不同的時間標籤:
-
新創建的pod:CreationTimestamp
-
已經成功調度過的pod:LastTransitionTime
-
調度失敗的pod:LastProbeTime
#73296 防止pod調度到not ready的節點
該問題由issue#72129提出,因爲scheduler調度時不再關心node狀態(只根據node上的taint調度),而新創建的node雖然狀態爲not ready,但是沒有被打上notready的taint,scheduler可能在節點ready之前就把pod調度到not ready的節點上,這顯然不是我們期望的行爲。
該bug fix對這個問題的解決方法是,添加一個名爲nodetaint的admission controller,這樣在節點創建時就會給節點添加一個taint,從而無差別的給新創建的node添加notready的taint。
#73454 添加協程定時
將不可調度的pod移動到active隊列scheduler之前的邏輯,是通過事件觸發不可調度的pod移動到active隊列重新調度。
這個邏輯在大部分場景下沒什麼問題,但是在大規模集羣中,有可能出現有新的事件觸發,但是scheduler沒有及時同步這個事件,pod根據之前的信息放入不可調度的隊列。而這時候事件已經發生過了,不會觸發它重新調度。
這就有一定的概率導致pod可以被調度,但是放到了不可調度隊列,又在很長一段事件不會重試。
本bug fix是通過添加一個協程,以1min爲間隔,將不可調度隊列中的pod放到active隊列重新調度。
kubernetes 1.13.2-1.13.4
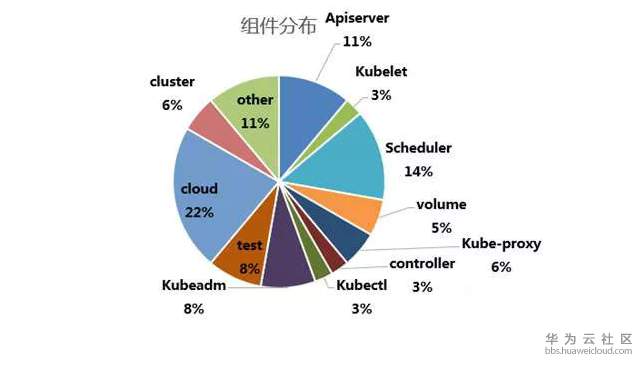
bug fix數據分析本週更新1/11-3/4期間的相關bug fix數據,正好是1.13.2-1.13.4兩個版本間的數據。
總體來說,這兩個版本更新的內容並不多,總共也才36條bug fix,去第三方雲提供商相關的、test相關的,則只有20+條。其中比較嚴重的bug就更稀缺了。可見kubernetes核心組件已經愈趨穩定。
另外前幾天社區公佈了一個不大不小的漏洞,具體上文已經分析過了。大家可以根據自己的情況決定是否升級到最新版本。
下面是這段時間值得關注的一些pr,大家有興趣的話可以自行前往社區查看原始pr學習:
#72754 #73296 #73454 #73562 #73909 #74102
最後,關於具體數據,還是查看圖表吧:
bug嚴重程度統計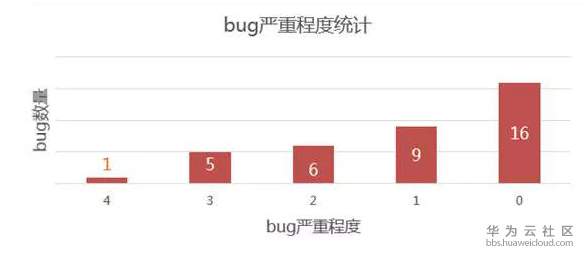
近期bug fix數據分析: