




Celery 分佈式任務隊列
同步與異步
比如說你要去一個餐廳吃飯,你點完菜以後假設服務員告訴你,你點的菜,要兩個小時才能做完,這個時候你可以有兩個選擇
- 一直在餐廳等着飯菜上桌
- 你可以回家等着,這個時候你就可以把你的電話留給服務員,告訴服務員等什麼時候你的飯菜上桌了,在給你打電話
所謂同步就是一個任務的完成需要依賴另外一個任務時,只有等待被依賴的任務完成後,依賴的任務才能算完成,這是一種可靠的任務序列。要麼成功都成功,失敗都失敗,兩個任務的狀態可以保持一致。
所謂異步是不需要等待被依賴的任務完成,只是通知被依賴的任務要完成什麼工作,依賴的任務也立即執行,只要自己完成了整個任務就算完成了至於被依賴的任務最終是否真正完成,依賴它的任務無法確定,所以它是不可靠的任務序列。
阻塞與非阻塞
繼續上面的例子
- 不管你的在餐廳等着還是回家等着,這個期間你的都不能幹別的事,那麼該機制就是阻塞的,表現在程序中,也就是該程序一直阻塞在該函數調用處不能繼續往下執行。
- 你回家以後就可以去做別的事了,一遍做別的事,一般去等待服務員的電話,這樣的狀態就是非阻塞的,因爲你(等待者)沒有阻塞在這個消息通知上,而是一邊做自己的事情一邊等待。
阻塞和非阻塞這兩個概念與程序(線程)等待消息通知(無所謂同步或者異步)時的狀態有關。也就是說阻塞與非阻塞主要是程序(線程)等待消息通知時的狀態角度來說的
同步/異步與阻塞/非阻塞
同步阻塞形式
效率最低。拿上面的例子來說,就是你專心的在餐館等着,什麼別的事都不做。
異步阻塞形式
在家裏等待的過程中,你一直盯着手機,不去做其它的事情,那麼很顯然,你被阻塞在了這個等待的操作上面;
異步操作是可以被阻塞住的,只不過它不是在處理消息時阻塞,而是在等待消息通知時被阻塞。
同步非阻塞形式
實際上是效率低下的。
想象一下你如果害怕服務員忘記給你打電話通知你,你過一會就要去餐廳看一下你的飯菜好了沒有,沒好 ,在回家等待,過一會再去看一眼,沒好再回家等着,那麼效率可想而知是低下的。
異步非阻塞形式
比如說你回家以後就直接看電視了,把手機放在一邊,等什麼時候電話響了,你在去接電話.這就是異步非阻塞形式,大家想一下這樣是不是效率是最高的
那麼同步一定是阻塞的嗎?異步一定是非阻塞的嗎?
生產者消費者模型
在實際的軟件開發過程中,經常會碰到如下場景:某個模塊負責產生數據,這些數據由另一個模塊來負責處理(此處的模塊是廣義的,可以是類、函數、線程、進程等)。產生數據的模塊,就形象地稱爲生產者;而處理數據的模塊,就稱爲消費者。
單單抽象出生產者和消費者,還夠不上是生產者消費者模式。該模式還需要有一個緩衝區處於生產者和消費者之間,作爲一箇中介。生產者把數據放入緩衝區,而消費者從緩衝區取出數據,如下圖所示:

生產者消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通訊,而通過消息隊列(緩衝區)來進行通訊,所以生產者生產完數據之後不用等待消費者處理,直接扔給消息隊列,消費者不找生產者要數據,而是直接從消息隊列裏取,消息隊列就相當於一個緩衝區,平衡了生產者和消費者的處理能力。這個消息隊列就是用來給生產者和消費者解耦的。------------->這裏又有一個問題,什麼叫做解耦?
解耦:假設生產者和消費者分別是兩個類。如果讓生產者直接調用消費者的某個方法,那麼生產者對於消費者就會產生依賴(也就是耦合)。將來如果消費者的代碼發生變化,可能會影響到生產者。而如果兩者都依賴於某個緩衝區,兩者之間不直接依賴,耦合也就相應降低了。生產者直接調用消費者的某個方法,還有另一個弊端。由於函數調用是同步的(或者叫阻塞的),在消費者的方法沒有返回之前,生產者只好一直等在那邊。萬一消費者處理數據很慢,生產者就會白白糟蹋大好時光。緩衝區還有另一個好處。如果製造數據的速度時快時慢,緩衝區的好處就體現出來了。當數據製造快的時候,消費者來不及處理,未處理的數據可以暫時存在緩衝區中。等生產者的製造速度慢下來,消費者再慢慢處理掉。
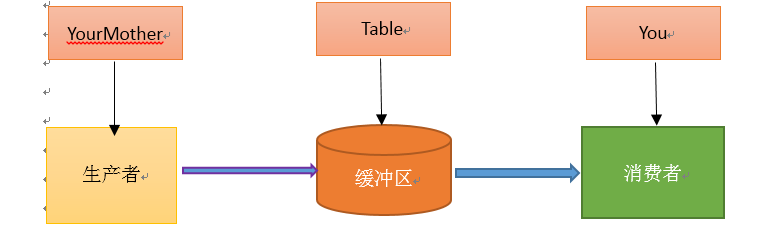
因爲太抽象,看過網上的說明之後,通過我的理解,我舉了個例子:吃包子。
假如你非常喜歡吃包子(吃起來根本停不下來),今天,你媽媽(生產者)在蒸包子,廚房有張桌子(緩衝區),你媽媽將蒸熟的包子盛在盤子(消息)裏,然後放到桌子上,你正在看巴西奧運會,看到蒸熟的包子放在廚房桌子上的盤子裏,你就把盤子取走,一邊吃包子一邊看奧運。在這個過程中,你和你媽媽使用同一個桌子放置盤子和取走盤子,這裏桌子就是一個共享對象。生產者添加食物,消費者取走食物。桌子的好處是,你媽媽不用直接把盤子給你,只是負責把包子裝在盤子裏放到桌子上,如果桌子滿了,就不再放了,等待。而且生產者還有其他事情要做,消費者吃包子比較慢,生產者不能一直等消費者吃完包子把盤子放回去再去生產,因爲吃包子的人有很多,如果這期間你好朋友來了,和你一起吃包子,生產者不用關注是哪個消費者去桌子上拿盤子,而消費者只去關注桌子上有沒有放盤子,如果有,就端過來吃盤子中的包子,沒有的話就等待。對應關係如下圖:
celery
生產者消費者模型
消費者
from celery import Celery
task=Celery('task',broker="redis://10.211.55.19:6379") #task可以是任何名稱,後面跟的是隊列的緩存者,celery中一般稱爲中間人,如果要是密碼訪問的話,需要是redis://:{pass}@IP地址:端口
@task.task()
def add(a,b):
return a+b啓動 celery從4.0版本以後就不在支持windows了,如果想在windows環境下使用的話,需要安裝eventlet這個包,啓動的時候需要指定-P eventlet
celery worker -A c -l info 生產者
from c import add
for i in range(10):
add.delay(1,2)模擬兩個消費者
在不同的位置在啓動一個worker既可以了
celery worker -A c -l info 獲取執行狀態
```倘若任務拋出了一個異常, get() 會重新拋出異常, 但你可以指定 propagate 參數來覆蓋這一行爲:>>> result.get(propagate=False)如果任務拋出了一個異常,你也可以獲取原始的回溯信息:>>> result.traceback…
print(t)
print(t.ready())
print(t.get())
print(t.ready())
倘若任務拋出了一個異常, `get()` 會重新拋出異常, 但你可以指定 `propagate` 參數來覆蓋這一行爲:
>> t.get(propagate=False)
如果任務拋出了一個異常,你也可以獲取原始的回溯信息:
>>> t.traceback生產者消費者模型升級
消費者
from celery import Celery
task=Celery('task',broker="redis://10.211.55.19:6379/0",backend="redis://10.211.55.19:6379/2")#broker和backend可以是不同的隊列,這裏使用redis不同的庫來模擬不同的隊列,當然也可以一樣
@task.task()
def add(a,b):
return a+b啓動過程跟上面一樣
生產者
from c import add
for i in range(10):
t=add.delay(i,2)
print(t.get()) #獲取結果登錄redis查看信息
redis-cli
127.0.0.1:6379[1]> SELECT 2
127.0.0.1:6379[2]> KEYS *
127.0.0.1:6379[2]> get celery-task-meta-6c8dda5e-c8a3-4f5f-8c2b-e7541aafdc42
"{\"status\": \"SUCCESS\", \"result\": 3, \"traceback\": null, \"children\": [], \"task_id\": \"6c8dda5e-c8a3-4f5f-8c2b-e7541aafdc42\"}"
## 解析數據
d="{\"status\": \"SUCCESS\", \"result\": 3, \"traceback\": null, \"children\": [], \"task_id\": \"6c8dda5e-c8a3-4f5f-8c2b-e7541aafdc42\"}"
import json
print(json.loads(d))定時任務
apply_async
t=add.apply_async((1,2),countdown=5) #表示延遲5秒鐘執行任務
print(t)
print(t.get())
問題:是延遲5秒發送還是立即發送,消費者延遲5秒在執行那?支持的參數 :
-
countdown : 等待一段時間再執行.
add.apply_async((2,3), countdown=5) -
eta : 定義任務的開始時間.這裏的時間是UTC時間,這裏有坑
add.apply_async((2,3), eta=now+tiedelta(second=10)) -
expires : 設置超時時間.
add.apply_async((2,3), expires=60) -
retry : 定時如果任務失敗後, 是否重試.
add.apply_async((2,3), retry=False) -
retry_policy : 重試策略.
- max_retries : 最大重試次數, 默認爲 3 次.
- interval_start : 重試等待的時間間隔秒數, 默認爲 0 , 表示直接重試不等待.
- interval_step : 每次重試讓重試間隔增加的秒數, 可以是數字或浮點數, 默認爲 0.2
- interval_max : 重試間隔最大的秒數, 即 通過 interval_step 增大到多少秒之後, 就不在增加了, 可以是數字或者浮點數, 默認爲 0.2 .
週期任務
from c import task
task.conf.beat_schedule={
timezone='Asia/Shanghai',
"each10s_task":{
"task":"c.add",
"schedule":3, # 每3秒鐘執行一次
"args":(10,10)
},
}其實celery也支持linux裏面的crontab格式的書寫的
from celery.schedules import crontab
task.conf.beat_schedule={
timezone='Asia/Shanghai',
"each3m_task":{
"task":"c.add",
"schedule":crontab(minute=3), #每小時的第3分鐘執行
"args":(10,10)
},
"each3m_task":{
"task":"c.add",
"schedule":crontab(minute=*/3), #每小時的第3分鐘執行
"args":(10,10)
},
}後臺啓動
worker:
celery multi start worker1 \
-A c \
--pidfile="$HOME/run/celery/%n.pid" \
--logfile="$HOME/log/celery/%n%I.log"
celery multi restart worker1 \
-A proj \
--logfile="$HOME/log/celery/%n%I.log" \
--pidfile="$HOME/run/celery/%n.pid
celery multi stopwait worker1 --pidfile="$HOME/run/celery/%n.pid"
beat:
celery -A d beat --detach -l info -f beat.log
與django結合
1.執行異步任務
1.1 在生成的目錄文件中添加celery文件,內容如下
from __future__ import absolute_import, unicode_literals
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'tests.settings') #與項目關聯
app = Celery('tests',backend='redis://10.211.55.19/3',broker='redis://10.211.55.19/4')
#創建celery對象
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')
#在django中創建celery的命名空間
# Load task modules from all registered Django app configs.
app.autodiscover_tasks()
#自動加載任務1.2編輯settings.py同級目錄的init.py
from __future__ import absolute_import, unicode_literals
from .celery import app as celery_app
__all__ = ['celery_app']1.3 在項目中添加tasks文件,用來保存tasks的文件
from celery import shared_task
@shared_task
def add(x, y):
return x + y
@shared_task
def mul(x, y):
return x * y
@shared_task
def xsum(numbers):
return sum(numbers)1.4添加views文件內容
from .tasks import add
def index(request):
result = add.delay(2, 3)
return HttpResponse('返回數據{}'.format(result.get()))
1.5 啓動worker
celery -A tests worker -l info1.6添加url並調用
2.執行週期性任務
2.1需要安裝一個django的組件來完成這個事情
pip install django-celery-beat2.2將django-celery-beat添加到INSTALLED_APPS裏面
INSTALLED_APPS = (
...,
'django_celery_beat',
)2.3刷新到數據庫
python3 manage.py makemigrations #不執行這個會有問題
python3 manage.py migrate2.4 admin配置
2.5啓動beat
celery -A tests beat -l info --scheduler django_celery_beat.schedulers:DatabaseScheduler
2.6 啓動worker
celery -A tests worker -l info