




- 單頁應用的目標
- 實現多頁面路由的React-Router庫
- 多頁面的代碼分片
一、單頁應用
使用傳統的多頁面實現方式,即每次頁面切換都是一次網頁刷新,每次頁面切換的時候都遵從以下的步驟:
(1)瀏覽器的地址欄發生變化指向新的URL,於是瀏覽器發起一個HTTP請求到服務器獲取頁面的完整HTML;
(2)瀏覽器獲取到HTML內容後,解析HTML內容;
(3)瀏覽器根據解析的HTML內容確定還需要下載哪些其他資源,包括JavaScript和CSS資源;
(4)瀏覽器會根據HTML和其他資源渲染頁面內容,然後等待用戶的其他操作。
上面的頁面存在很大的浪費,每個頁面切換都要重新刷新一遍頁面。而“單頁應用”可以解決這樣的問題,“單頁應用”只是局部更新,需要做到“單頁應用”,需要達到以下的目標:
- **不同頁面直接切換不會造成網頁的刷新;
- 頁面內容和URL保持一致**
頁面內容和URL保持一致包含兩個方面:第一個方面是指當頁面切換的時候,URL會對應改變,這通過瀏覽器的History API可以實現在不刷新網頁的情況下修改URL;另一方面,用戶在地址欄直接輸入某個正確的URL時,網頁上要顯示對應的正確的內容。
二、React-Router
React-Router庫可以幫我們創建React單頁應用。每個URL都包含域名部分和路徑部分,例如對於URL http://localhost:3000/home 來說,路徑部分是home,因爲應用可能會被部署到任何一個域名上,所以決定一個URL顯示什麼內容的只有路徑部分,和域名以及端口沒有關係,根據路徑找到對應應用內容的過程,也就是React-Router的重要功能-路由。
-
路由
React-Router庫提供了兩個組件來完成路由功能,一個是Router,一個是Route。Router在整個應用中只需要一個實例,代表整個路由器,後者Route則代表每一個路徑對應頁面的路由規則,一個應用中應該會有多個Route實例。 -
路由鏈接和嵌套
React-Router提供了一個名爲Link的組件來支持路由鏈接,Link的作用是產生HTML的鏈接元素,但是對這個鏈接元素的點擊操作不會引起網頁跳轉,而是被Link截獲操作,把目標路徑發送給Router路由器,這樣Router就知道可以讓哪個Route下的組件顯示了。
建立Route組件之間的父子關係,這種方式,就是路由的嵌套。嵌套路由的好處就是每一層Route只決定到這一層的路徑,而不是整個路徑,所以非常靈活。 - 默認鏈接
當路徑爲空的時候,應用也應該顯示有意義的內容,通常對應主頁內容。在這個應用中,我們希望路徑爲空的時候顯示Home組件,React-Router提供了另外一個組件IndexRoute,就和傳統上index.html是一個路徑目錄下的默認頁面一樣,IndexRoute代表一個Route下的默認路由,代碼如下:![React總結篇之十一_多頁面應用]()
這樣一來,無論http://localhost:3000還是http://localhost:3000/home 訪問的都是包含home的主頁內容。

4.集成Redux
我們希望用Redux來管理應用中的狀態,所以要把Redux添加到應用中取。
使用React-Redux庫的Provider組件,作爲數據的提供者,Provider必須居於接受數據的React組件之上。而React-Redux庫Router組件,也有同樣的需要,有兩種解決辦法:
(1)讓Router成爲Provider的子組件,例如在應用的入口函數src/index.js中代碼修改成下面這樣:
Router可以是Provider的子組件,但是,不能夠讓Provider成爲Router的子組件,因爲Router的子組件只能是Route或者IndexRoute,否則運行時會報錯。
(2)使用Router的createElement屬性,通過給createElement傳遞一個函數,可以定製創建每個Route的過程,這個函數第一個參數Component代表Route對應的組件,第二個參數代表傳入組件的屬性參數。加上Provider的createElement可以這樣定義:

需要注意的是,Router會對每個Route的構造都調用一遍createElement,也就是每個組件都創造一個Provider來提供數據,這樣並不會產生性能問題。
Redux遵從一個重要的原則就是"唯一數據源",唯一數據源並不是說所有的數據都要存儲在一個地方,而是一個數據只存在一個地方,以路由爲例,使用React-Redux,即使結合了Redux,當前路由的信息也是存儲在瀏覽器的URL上,而不是像其他數據一樣存儲在Redux的Store上,這樣做並不違背“唯一數據源”的原則,獲取路由信息的唯一數據源就是當前的URL。
不過,如果不是所有應用狀態都存在Store上,就會有一個很大的缺點,當利用Redux Devtools做調試時,無法重現網頁之間的切換,因爲當前路由作爲應用狀態根本沒有在Store狀態上體現,而Redux Devtools操縱的只有狀態。爲了克服這個缺點,我們可以利用react-router-redux庫來同步瀏覽器URL和Redux的狀態。顯然,這違反了“唯一數據源”的原則,但是隻要兩者絕對保持同步,就不會帶來問題,否則,會出大問題。
三、代碼分片
藉助React-Router,我們可以將需要多頁面的應用構建成“單頁應用”,在服務器端對任何頁面請求都返回同樣一個HTML, 然後由一個打包好的JavaScript處理所有路由等應用邏輯,在create-react-app創造的應用中,由webpack產生的唯一打包JavaScript文件被命名爲bundle.js。
對於小型的應用,按照上面的方式就足夠了,但是,對於大型應用,把所有應用邏輯打包在一個bundle.js文件中,會影響用戶感知的性能。
在大型應用中,因爲功能很多,若把所有頁面的JavaScript打包到一個bundle.js中,那麼用戶訪問任何一個網頁,都需要下載整個網站應用的功能。雖然瀏覽器的緩存機制可以避免下次訪問時下載重複資源,但是給用戶的第一印象卻打了折扣。很明顯,當應用變得較大之後,就不能把所有JavaScript打包到一個bundle.js中。
爲了提高性能,一個簡單有效的方法是對JavaScript分片打包,然後按需加載。也就是把JavaScript轉譯打包到多個文件中,每一個文件的大小可以被控制的比較小。這樣,訪問某個網頁的時候,只需要下載必須的JavaScript代碼就行,不用下載整個應用的邏輯。
1.代碼分片的原則
最自然的方式就是根據頁面來劃分,如果有N個頁面,那就劃分出N個分片,現實中,各個網頁之間肯定有交叉的部分,比如A、B頁面都使用一個共同的組件X,而且對於React應用來說,每個頁面都依賴於React庫,所有至少都有共同的React庫部分代碼,這些共同的代碼沒有必要在各個分片裏重複,需要抽取出來放在一個共享的打包文件中。
最終,理想情況下,當一個網頁被加載時,它會獲取一個應用本身的bundle.js文件,一個包含頁面間共同內容的common.js文件,還有一個就是特定於這個頁面內容的JavaScript文件。
爲了實現代碼分片,可以使用webpack。webpack的工作方式是根據代碼中的import語句和require方法確定模塊之間的依賴關係,所以webpack可以發掘所有模塊文件的依賴圖表,從這個圖表中不難歸結出分片需要的信息。
如圖展示了webpack實現代碼分片的原理: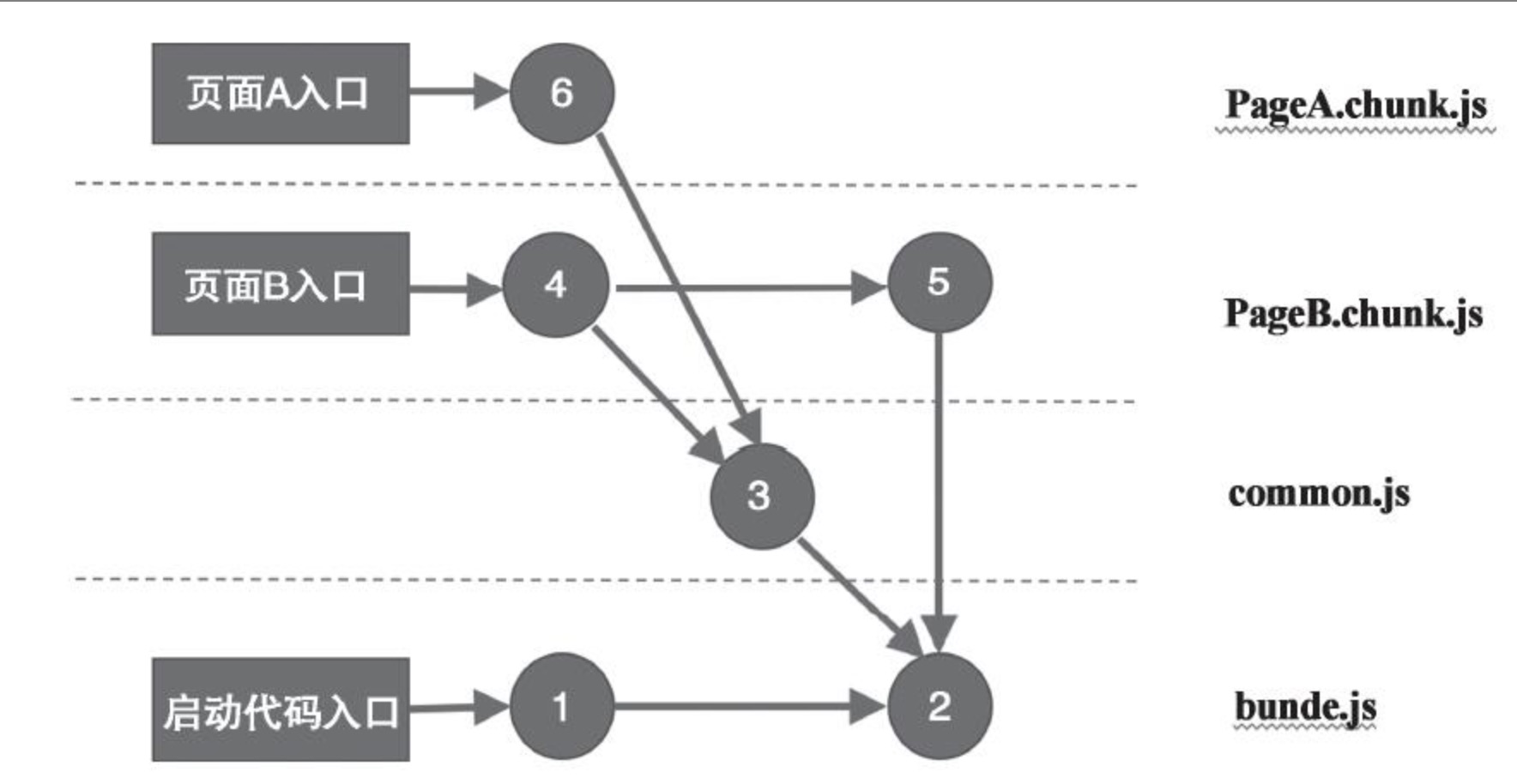
這樣,當瀏覽器訪問頁面A時,只需要加載PageA.chunk.js、commont.js和bundle.js這三個文件,和頁面A無關的4號和5號文件不被加載,節省了代碼下載量。
當然,提高網頁性能的另一個重要原則是減少http請求數,雖然代碼分片減少了每個頁面的代碼下載量,卻也增加了引用的JavaScript資源數,但是這隻影響用戶訪問的第一個頁面。例如,用戶訪問的第一個頁面是A,下載PageA.chunk.js、commont.js和bundle.js這三個文件,隨後當頁面切換到B時,因爲瀏覽器的緩存作用,commont.js和bundle.js不用重新下載,所以新下載的文件只有PageB.chunk.js,當應用中頁面越多,這種優化效果也明顯。
2.彈射和配置webpack
爲了實現代碼分片,需要直接操作webpack的配置文件,不能再使用react-create-app產生的默認配置,首先我們要讓應用從react-create-app製造的“安全艙“裏彈射出來,在命令行執行如下命令:
npm run eject
注意:彈射是不可逆的操作
執行該命令後,應用目錄下多了scripts和config兩個目錄,分別包含腳本和配置文件,同時應用目錄下的packge.json文件發在了變化,包含了更多的內容,至此彈射完成,但是功能和”彈射“之前別無二致,要改進功能還需要手工修改一些文件。
有兩個webpack配置,分別代表開發環境和產品環境。首先處理開發模式也就是npm start命令啓動的模式下的webpack配置。
打開config/webpack.config.dev.js找到給module.exports賦值的語句,在給module.exports賦值的對象中,找到output這個字段,在其中添加上關於chunkFilename的一行,然後找到plugins字段,這是一個數組,在裏面添加一個元素增加Commons-ChunkPlugin, 代碼修改如下:

增加的output配置,是告訴webpack給每個分片都產生一個文件,文件名包括模塊名和後綴”chunk.js“,後綴名可以隨意起。
增加在plugins中的配置是告訴webpack把所有分片中共同的代碼提取出來,放在名爲common.js的文件中。
生成的文件都帶上前綴路徑,是爲了保持和原有的bundle.js文件所在目錄一致,也可以是任意一個位置。
上面的修改只針對開發模式,還要修改產品的webpack配置保持一致。
打開config/webpack.config.prod.js文件,在config/webpack.config.prod.js中的output已經有了正確的chunkFileName,所以只需要在plugins中添加下面一行就行:
new webpack.optmize.CommonsChunkPlugins('common','static/js/common.[chunkhash:8].js'),產品環境多出了[chunkhash:8]的部分,這是爲了讓瀏覽器緩存在文件內容改變時失去效果。因爲產品環境下打包的文件部署出去之後預期會被瀏覽器長期緩存,所以不能使用固定的文件名,否則後續部署的代碼更新無法被瀏覽爲發現。所以每個文件名都會包含一個8位的根據文件內容產生的hash結果,這樣當文件內容發生變化時,文件名也發生了變化,對應文件的URL也就發生了變化,瀏覽器就會去下載最新的JavaScript打包資源。
3.動態加載分片
針對webpack的配置只是告訴webpack分片打包,但是webpack沒有”頁面“的概念,還是需要修改JavaScript代碼來確定怎樣按照頁面分片。
該實例中,我們希望Home、About、Notfound頁面每個都是按需加載的,這三個頁面都應該有自己的分片,它們的內容也就不包含在主體的bundle.js文件中。因爲webpack的工作方式是根據代碼中的import和require函數來找到所有的文件模塊,所以,要讓這三個頁面不出現在bundle.js文件中,就不能再直接使用import命令來導入它們。
完成動態加載分片需要兩個方面:
(1)使用require.ensure讓webpack產生分片打包文件
在src/Stores.js中,註釋掉對Home、About、NotFound的import語句,並利用Route的getComponent屬性異步加載組件,代碼如下:
(2)使用React-Router的getComponent異步加載頁面分片文件
注意:webpack打包過程是對代碼靜態掃描的過程,即webpack工作的時候,縮寫的代碼並沒有運行,webpack看到import和require參數是字符串,那麼webpack就能明確的知道文件模塊位置,如果是變量,那webpack無法在靜態掃描狀態下確定哪些文件應該放在對應分片中。
4.動態更新Store的reducer和狀態
當實現動態加載分片後,功能模塊(React組件、reducer、Store)會被webpack分配到不同的分片文件中,包含在功能模塊中的reducer代碼也會也會被分配到不同的代碼文件。這樣,應用的bundle.js文件中就沒有這些reducer函數的定義,每個應用都有唯一的一個Redux Store,當應用啓動創建Store時,並不知道這個應用中所有的reducer函數如何定義。所以,當切換到某個頁面的時候,除了要加載對用的React組件,還要加載對應的reducer,否則功能模塊無法正常工作。功能模塊依賴Store上的狀態,所以當頁面切換時,除了要更新reducer,Store上的狀態樹也可能需要做對應改變,才能支持新加載的功能組件。