




#####################################################
#本文內容來自《老男孩linux運維實戰培訓》學生—鄭東旭
#如有轉載,請務必保留本文鏈接及本版權信息。
#歡迎廣大運維同仁一起交流linux/unix網站運維技術!
#QQ:919953500
#E-mail:[email protected]
=====================================================
老男孩linux運維實戰培訓中心
諮詢 QQ: 70271111 357851641
諮詢電話:18911718229
諮詢電話:18911718229
網站地址: http://www.etiantian.org
老男孩博客: http://oldboy.blog.51cto.com
老男孩的QQ: 31333741
#####################################################
老男孩的QQ: 31333741
#####################################################
本文說明:
綠色爲重點 紅色爲警告或注意 藍色爲提示或說明 黑色爲正常輸出
===============================================================================
面試經驗談架構
面試經驗談架構
把以前的知識複習一遍,並連串起來
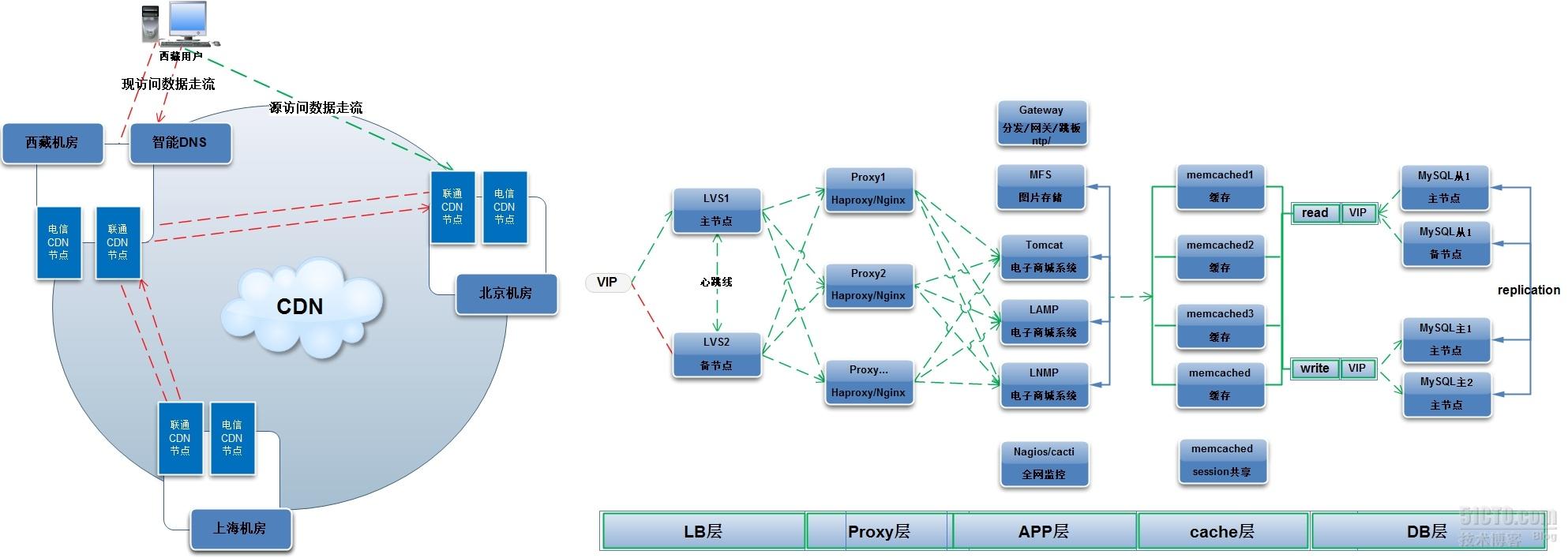
綠色線條爲正常數據走流,紅色線條爲備用線路數據走流,藍色線爲掛載存儲,CDN網絡中紅色爲同步數據走流
用戶請求到達VIP地址(公網地址,與域名綁定),由四層負載均衡LVS根據自身的算法將用戶請求轉發到七層負載均衡Proxy代理服務器,代理服務器根據用戶的請求(可判斷head頭部信息)判斷用戶請求的資源(如:如果用戶使用手機訪問,代理服務器將請求wap業務機,如果用戶使用電腦訪問,代理服務器將請求web業務機),
有些公司會有如下的需求,是四層負載均衡做不到的
(1)、代理服務器根據用戶的請求(可判斷head頭部信息)判斷用戶請求的資源(如:如果用戶使用手機訪問,代理服務器將請求wap業務機,如果用戶使用電腦訪問,代理服務器將請求web業務機)
(2)、如果內網服務器跑多個應用,比如啓動多個基於IP地址的虛擬主機,代理服務器可將用戶訪問一個地址,轉發到不同的應用服務器
(3)、四層和七層負載均衡在中小企業首選七層負載均衡,等以後架構擴展在前端添加四層負載均衡(原因:七層負載均衡配置簡單,不像lvs需要對後端服務器配置操作,並且七層負載均衡可以抵擋千萬PV)
當有西藏的用戶訪問電子商城,如果直接訪問北京機房的電子商城,速度會非常緩慢,,大大減少用戶訪問速度
各地機房放兩臺CDN節點服務器(電信和聯通)
(1)、無CDN節點訪問流程
西藏聯通用戶直接訪問北京服務器(綠色線),延遲非常大,有可能頁面顯示"無法顯示該頁面"
(2)、CND節點訪問流程
1)、西藏聯通用戶請求到智能DNS解析域名
2)、通過智能DNS解析最近西藏機房域名後返回給用戶,用戶請求到西藏機房
3)、如果西藏機房CDN中無用戶請求資源,CDN代替用戶從上海或北京CDN節點請求用戶資源,應答給用戶
4)、請求後的資源緩存到本地CDN節點
2、LB層
lvs+keepalived四層負載均衡高可用
(1)、LVS原理
通過網絡地址轉換,用戶發送請求包到調度器(負載均衡器)的VIP地址,調度器重寫請求報文的目標地址,根據預設的算法,將請求分發給後端的真實服務器,真實服務器響應報文通過調度器時,調度器重寫報文的源地址,再返回給用戶,完成整個負載調度過程
應用範圍:由於LVS/NAT模式入站和出站的流量都經過LB,大於處理的後端真實服務器是10-20臺
採用NAT模式時,由於請求和響應報文都經過負載均衡器地址重寫,當客戶端請求越來越來越多時,調度器的處理能力將成爲瓶頸,爲了解決這個問題,調度器通過算法把請求的報文通過IP隧道(加密的相當於ipip,或ipsec)分發至後端真實服務器,後端真是服務器將響應直接發送給客戶端,這樣調度器只處理請求的報文,由於一般網絡服務應答數據比請求報文大很多,採用VS/TUN技術後,集羣系統的最大吞吐量可以提高10倍
說明:LVS/TUN不改IP地址,是通過隧道轉發,開啓隧道會有系統開銷,並且響應報文不經過負載均衡器,由真實服務器直接響應給用戶
應用範圍:LVS/TUN在互聯網中用的不多,它可以處理局域網的請求也可處理廣域網的請求
LVS/DR模式通過修改請求報文的MAC地址,將請發送發給後端真是服務器,後端真是服務器將響應直接返回給用戶,和VS/TUN模式一樣,VS/DR模式可極大提高集羣系統的伸縮性,它沒有IP隧道的開銷,集羣系統對後端真是服務器也沒有必須支持IP隧道協議的要求,但是要求調度器和所有後端真是服務器都有一塊網卡連在同一物理網段上(都在一個網段上)(最後一段話重要,加顏色),因爲他是通過數據鏈路層ARP協議實現的
1、客戶端計算機CIP請求被髮送到LVS調度器VIP
2、LVS調度器收到目標地址爲VIP的請求包後,將該數據包的目的MAC地址通過算法改成某一臺RS的MAC地址,並通過交換機發送個這臺RS服務器,(因爲目的MAC地址是RS服務,所以RS服務器可以接受該數據包)注意:此時數據包的目標IP地址和源IP地址沒有發生任何改變
3、RS服務器收到發來的數據報文請求後,會從鏈路層上傳到IP層,此時IP層需要驗證請求的目標IP地址,因爲包的目標IP地址(Director的VIP地址)並不像常規數據包那樣爲RS的本地IP,而僅僅目的MAC地址是RS的
這個時候RS的IP層是驗證不過的,因爲數據包的目的MAC地址是自己的,數據包目的的IP地址卻不是自己的,那麼這個時候,網絡層就不會把包上傳到傳輸層來處理這個數據包
所以在RS上需要配置一個VIP的loopback device,因爲loopback device是服務器本地使用的網絡接口,對外是不可見的,與LVS的VIP不會衝突,(會有一個ARP抑制問題)(RS收到的數據包在自己的網絡層驗證不過,所以要配置一個loopback device上綁定一個IP地址)
4、RS處理數據包完成後,將應答包直接返回給客戶端CIP,(此時數據包報文的源地址爲客戶端請求的目的地址VIP,而目的地址爲客戶端的CIP),應答數據包不會在經過LVS調度器。因此,如果是對外提供LVS負載均衡服務,則RS需要連上互聯網(公網IP或網關)才能將應答包返回給客戶端,生產環境中RS最好有帶公網IP的服務器,這樣可以不經過網關直接回應客戶端,如果多個RS使用了同一個出口網關,網關可能會成爲LVS架構的瓶頸,會大大降低LVS的性能
說明:爲什麼RS能直接回應給客戶端,因爲客戶端的請求包報文的源地址和目的地址都沒有被調度器在網絡層改動,所以根據以太網的協議,迴應數據包可以將請求的數據包的源IP當前目的IP,把目標IP當前源IP
應用範圍:互聯網公司常用的模式
1、可以跨VLAN通信,支持更多的後端RS
2、有防DDOS模塊
應用範圍:淘寶新出的一種模式,佔未廣泛使用
(2)、DR模式的問題
過程原理:當客戶端的請求包到達路由器,路由器會發出廣播誰是VIP,負載均衡器會響應,負載均衡器收到請求包通過自身的算法選擇一臺RS,(比如RS1)修改客戶端請求包的目的MAC地址爲RS1的MAC地址併發送給RS1,這個時候RS1的數據鏈路層把請求包給網絡層,網絡層需要驗證請求包的目標IP地址不是自己就會丟掉此包(此時的數據包源IP是CIP,目的IP是VIP),這個時候需要在RS節點上綁定VIP
過程原理:當客戶端的請求包到達路由器,路由器會發出廣播誰是VIP,這個時候,擁有VIP的負載均衡器和RS真實服務器都會響應這個包,導致無法正常工作,所以還有對RS做ARP抑制
RS綁定VIP地址,一般情況下是綁定到lo網卡上,但我們也可以綁定到其他虛擬網卡,比如eth0:10,設置改網卡的ARP功能即可
思考:RS沒有公網地址(dr模式)出站流量怎麼走(這個問題有待考證)
負載均衡爲DR模式,後端RS沒有公網IP地址,如何將用戶請求直接返回給用戶
答案:
應答請求不走LB,直接從路由器返回
(3)、LVS調度算法
|
算法
|
說明
|
|
rr 輪詢調度(Round-Robin)
|
它將請求一次分配不同的RS,也就是在RS中均攤請求,算法簡單,但是隻適合於RS處理性能相差不大的情況(多個服務器硬件配置差不多)
|
|
wrr加權輪詢調度(Weighted Round-Robin)
|
它根據RS不同的權值分配任務,權值高的RS優先獲得請求,分配到的連接數將比權值低的RS更多,權值相同的RS得到的連接數數目相同
|
|
wlc加權最小連接數調度(Weighted Least-Comnection) (WLC)
|
具有較高權值的服務器將承受較大比例的活動連接負載。調度器可以自動問詢真實服務器的負載情況,並動態地調整其權值。
假設各臺RS的權值一次爲Wi(l = 1..n),當前的TCP連接數依次爲Ti(l=1..n)一次選取Wi/Ti爲最小的RS作爲下一個分配的RS
|
|
dh 目的地址哈希調度(Destination Hashing)
|
以目的地址爲關鍵字查找一個靜態hash表來獲得需要的RS
|
|
sh 源地址哈希調度(Source Hashing)
|
以源地址作爲關鍵字查找一個靜態hash表來獲取需要的RS
|
|
LBLC 基於局部性的最少鏈接(Locality-Based Least Connections)
|
針對目標IP地址的負載均衡,目前主要用於Cache集羣系統。該算法根據請求的目標IP地址找出該目標IP地址最近使用的服務器,若該服務器是可用的且沒有超載,將請求發送到該服務器;若服務器不存在,或者該服務器超載且有服務器處於一半的工作負載,則用“最少鏈接” 的原則選出一個可用的服務器,將請求發送到該服務器。
|
|
LBLCR 帶複製的基於局部性最少鏈接(Locality-Based Least Connections with Replication)
|
也是針對目標IP地址的負載均衡,目前主要用於Cache集羣系統。它與LBLC算法的不同之處是它要維護從一個目標 IP地址到一組服務器的映射,而LBLC算法維護從一個目標IP地址到一臺服務器的映射。該算法根據請求的目標IP地址找出該目標IP地址對應的服務器組,按“最小連接”原則從服務器組中選出一臺服務器,若服務器沒有超載,將請求發送到該服務器;若服務器超載,則按“最小連接”原則從這個集羣中選出一臺服務器,將該服務器加入到服務器組中,將請求發送到該服務器。同時,當該服務器組有一段時間沒有被修改,將最忙的服務器從服務器組中刪除,以降低複製的程度。
|
|
DH 目標地址散列(Destination Hashing)
|
根據請求的目標IP地址,作爲散列鍵(Hash Key)從靜態分配的散列表找出對應的服務器,若該服務器是可用的且未超載,將請求發送到該服務器,否則返回空。
|
|
SH 源地址散列(Source Hashing)
|
根據請求的源IP地址,作爲散列鍵(Hash Key)從靜態分配的散列表找出對應的服務器,若該服務器是可用的且未超載,將請求發送到該服務器,否則返回空。
|
|
SED 最短的期望的延遲(Shortest Expected Delay Scheduling SED)
|
基於wlc算法
ABC三臺機器分別權重123 ,連接數也分別是123。那麼如果使用WLC算法的話一個新請求進入時它可能會分給ABC中的任意一個。使用sed算法後會進行這樣一個運算
A(1+1)/1
B(1+2)/2
C(1+3)/3
根據運算結果,把連接交給C 。
|
|
NQ 最少隊列調度(Never Queue Scheduling NQ)
|
無需隊列。如果有臺 realserver的連接數=0就直接分配過去,不需要在進行sed運算
|
提示:現在大約有12中算法常用的有算法有:rr,wrr,wlc
(4)、keepalived高可用兩大功能
ha failover 功能:實現LB Master主機和LB Backup主機之間故障轉移和自動切換
這是針對有兩個負載均衡器Director同時工作而採取的故障轉移措施,當主負載均衡器(Master)失效或出現故障時,備份負載均衡器(Backup)將自動接管主負載均衡的所有工作,一旦主負載均衡器(Master)的故障恢復,Master又會接管原來處理的工作,而備份負載均衡器(Backup)會釋放Master失效時它接管的工作,此時兩者將恢復到各自最初的角色狀態
rs healthcheck功能:負載均衡定時檢查RS的可用性決定是否給分發請求
當虛擬服務器中的某一個甚至多個真實服務器同時發生故障無法提供服務時,負載均衡器會自動將失效的RS服務器從轉發列隊中清除出去,從而保證用戶的訪問不受影響,當故障的RS服務器修復以後,系統又會自動的將它們加入到轉發列隊中,分發請求提供正常服務
心跳:heartbeat:主節點和備節點相互檢測對方是否存活
腦裂:split-brain:兩端都認爲對端有問題,備節點無法檢測到主節點的心跳(一般是心跳線故障),各自都自動起VIP,這種衝突的問題就叫裂腦
3、Proxy層
haprox/nginx/apache七層負載均衡
前文已經說過了“爲什麼要使用七層負載均衡”
4、App層
(1)、lamp & lnmp
生產環境中web應用程序只用一種,要麼apache要麼nginx,圖中只是作者在做實驗時,將兩者混用了
(2)、Java
有些公司的頁面是由java編寫的,而使用java容器,場景的java容器有:tomcat resin weblogic jboss跑java程序
前兩者是免費的,後兩者是收費的
(3)、MFS
分佈式文件系統,解決nfs單點故障問題
1)、MFS讀進程機制
1、客戶端向元數據服務器發出讀請求
2、元數據服務器吧所需數據存放的位置(Chunk Server的IP地址和chunk編號)告知客戶端
3、客戶端向已知的Chunk Server請求發送數據
4、Chunk Server向客戶端發送數據
特點:數據傳輸並不通過元數據服務器,這樣既減輕了元數據服務器的壓力,同時也增大了整個系統的吞吐能力,在多個客戶端讀取數據時,會被分散到不同的數據服務器請求
2)、MFS寫進程機制
1、客戶端向元數據服務器發送寫請求
2、元數據服務器與Chunk Server進行交互(只有當所需的分塊Chunks存在的時候才進行交互)
(1)、元數據服務器只在某些服務器創建新的分塊chunks
(2)、Chunk Server告知元數據服務器,步驟a已經操作成功
3、元數據服務器告知客戶端,你可以在哪個Chunk Server的哪些chunks寫入數據
4、客戶端向指定的Chunk Server寫入數據
5、Chunk Server與其他的Chunk Server進行數據同步
6、Chunk Server之間同步成功
7、Chunk Server告知客戶端數據寫入成功
8、客戶端告知元數據服務器本次寫入完畢
(4)、Gateway(網關服務器)
有上網需求時:內網服務器通過該網關服務器上網
5、Cache層
memcached應用非常廣泛,如:數據庫的查詢請求、session同步、前端web用戶請求
(2)、memcache原理
1.接到客戶請求後首先查看請求的數據是否在mem中存在,如果存在,直接返回給用戶
2.如果不存在,就去查詢數據庫,把從數據庫中獲得的數據返回給用戶,同時存在mem中一份,以後再有用戶需要這個數據就直接返回給用戶
3.每次更新了數據庫(增刪改查)以後,mem會同時更新數據,保證memcache中的數據和數據庫的數據一致
4.當分配給memcache內存空間用完後,會使用LRU(Least Recently Used最近最少使用)策略加到期失效策略,失效的數據首先被替換掉,然後在替換掉最近未使用的數據
5.服務停止後,緩存中的數據就會丟失
(2)、什麼是Session
說明:該圖片由網友所畫
存放用戶登錄信息
集羣環境
一個用戶訪問請求被分配到服務器A,並且在服務器A登錄了,並且在很短的時間,這個用戶又發出了一個請求,如果沒有會話保持功能的話,這個用戶的請求很有可能會被分配到服務器B去,這個時候用戶在服務器B上是沒有登錄的,所以又要重新登錄,但是用戶並不知道自己的請求被分配到了哪裏,用戶的感覺就是登錄了,怎麼又要登錄,用戶體驗很不好。
session文件
#ls /tmp
sess_4tsn40hhhk4fjpc5nfqd7klla4
sess_eoej5vhddfnqulbjef24dqq926
sess_qjr829a27dhascevs36mg5c855
sess_53kcemteriqguf7q847nnsj4n3
2).基於數據庫的Session共享
3).基於Cookie的Session共享
4).基於Memcache的Session共享(推薦)
6、DB層
面試必問
(1)、當有數據寫入到master,執行的SQL語句會寫入到binlog日誌中(select查詢語句不記錄)
(2)、Slave的IO線程會通過Master上授權的複製用戶請求連接Master服務器,請求從指定Binlog日誌文件的指定位置之後的Binlog日誌內容(日誌文件和位置是在配置主從服務時執行change master命令時指定的)
(3)、Master服務器接收到Slave服務器的IO線程請求後,Master上負責複製的IO線程根據Slave上的IO線程請求的信息讀取指定Binlog日誌文件制定位置之後的Binlog日誌內容,然後返回給Slave端的IO線程,返回的信息中還包括本次返回的binlog日誌內容後在Master服務端的新的Binlog文件名稱以及Binlog的位置點
(4)、Slave的IO線程獲取到來自Master的IO線程發來的日誌內容及日誌文件及位置點後,將新的binlog日誌位置點存放到master-info中,以便下次讀取Master端新Binlog日誌時能夠告訴Master需要從新Binlog日誌的那個文件那個位置開始請求新的Binlog日誌內容。並將Binlog日誌內容一次寫入到Slave端自身的Relay Log(中繼日誌)文件的最末端(MySQL-relay-bin.xxxx)
(5)、Slave端的SQL線程會實時的檢測本地Relay Log新增加的日誌內容,然後及時的把Real Log文件的內容解析成在Master端曾經執行的SQL語句的內容,並在自身Slave上按語句的順序執行應用這些SQL語句
(6)、經過上面的過程,就可以確保在Master端和Slave端執行了同樣的SQL語句,當複製狀態正常情況下,Master端和Slave端的數據完全一致
(2)、MySQL主從同步注意事項
1、主庫和從庫的版本要完全相同
2、主庫和從庫的server-id不能一樣(一般爲IP地址的最後一位)
3、主庫需要開啓binlog日誌功能,從庫無需開啓binlog日誌功能,除非做雙主模式和級聯複製模式
(3)、MySQL主從同步解決方案
方案一:MySQL主從同步
方案二:MySQL一主多從架構
方案三:MySQL多實例主從同步(互爲主從)
方案四:MySQL雙主架構
方案五:MySQL多主(拆庫拆表)
方案六:MySQL級聯複製
由開發人員參與
備份時,從庫停止SQL線程,備份後開啓SQL線程,保證不丟失數據,如果要求比較嚴格可以備份binlog日誌
mysql+heartbeat+drbd
mysql+heartbeat+replication
mysql+heartbeat+存儲
說明:也可以用keepalived做高可用軟件
數據庫腦裂非常危險,會導致數據不一致,
(8)、MySQL高可用腦裂解決方法
R710有四個網口,一般無特殊情況只用其中兩個,剩下兩個在插兩根心跳線