




一 前言
強烈建議:請在電腦的陪同下,閱讀本文。本文以實戰爲主,閱讀過程如稍有不適,還望多加練習。
本文的實戰內容有:
網絡小說下載(靜態網站)
優美壁紙下載(動態網站)
愛奇藝VIP視頻下載
二 網絡爬蟲簡介
網絡爬蟲,也叫網絡蜘蛛(Web Spider)。它根據網頁地址(URL)爬取網頁內容,而網頁地址(URL)就是我們在瀏覽器中輸入的網站鏈接。比如:https://www.baidu.com/,它就是一個URL。
在講解爬蟲內容之前,我們需要先學習一項寫爬蟲的必備技能:審查元素(如果已掌握,可跳過此部分內容)。
1 審查元素
在瀏覽器的地址欄輸入URL地址,在網頁處右鍵單擊,找到檢查。(不同瀏覽器的叫法不同,Chrome瀏覽器叫做檢查,Firefox瀏覽器叫做查看元素,但是功能都是相同的)
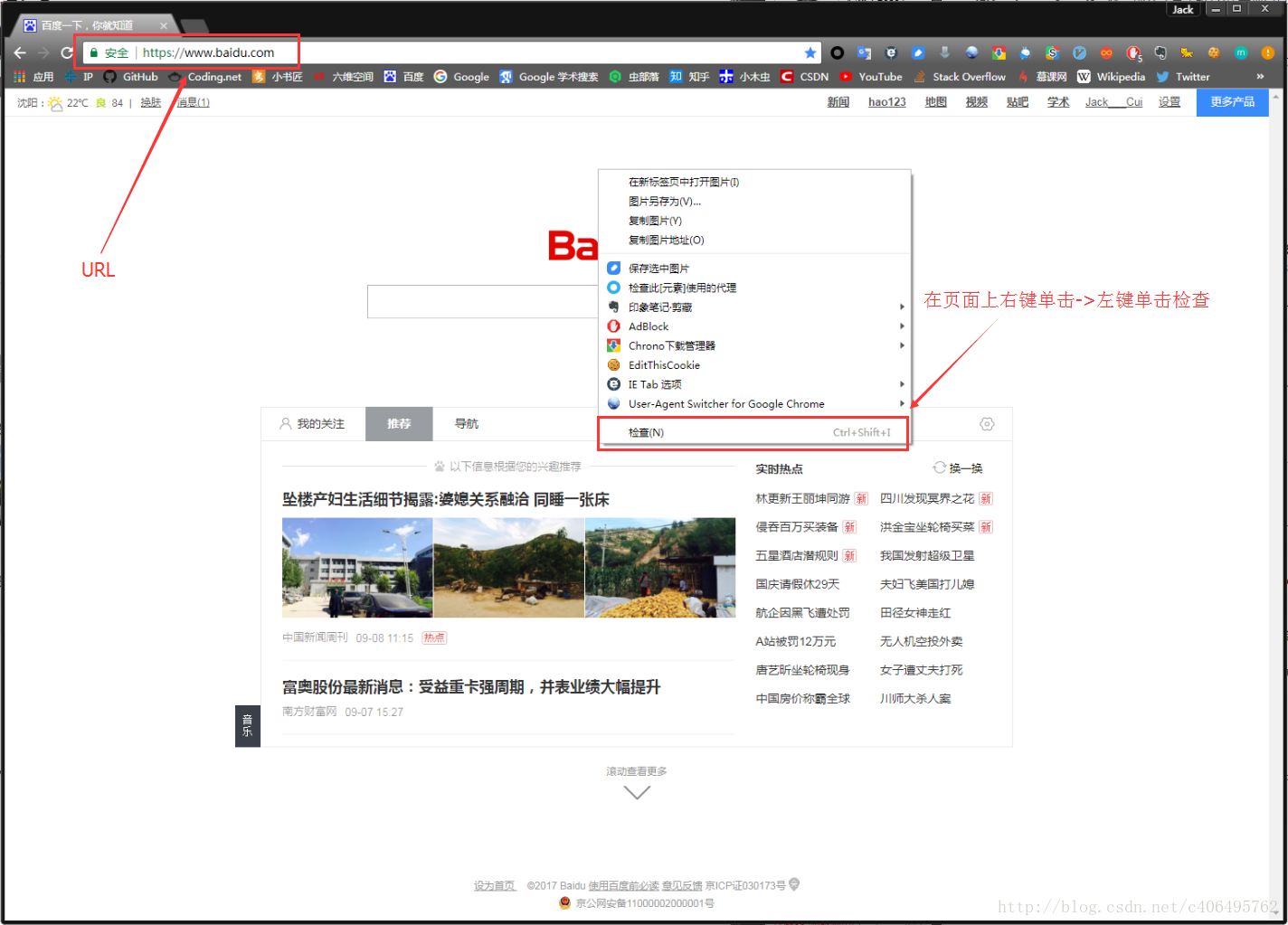
我們可以看到,右側出現了一大推代碼,這些代碼就叫做HTML。什麼是HTML?舉個容易理解的例子:我們的基因決定了我們的原始容貌,服務器返回的HTML決定了網站的原始容貌。
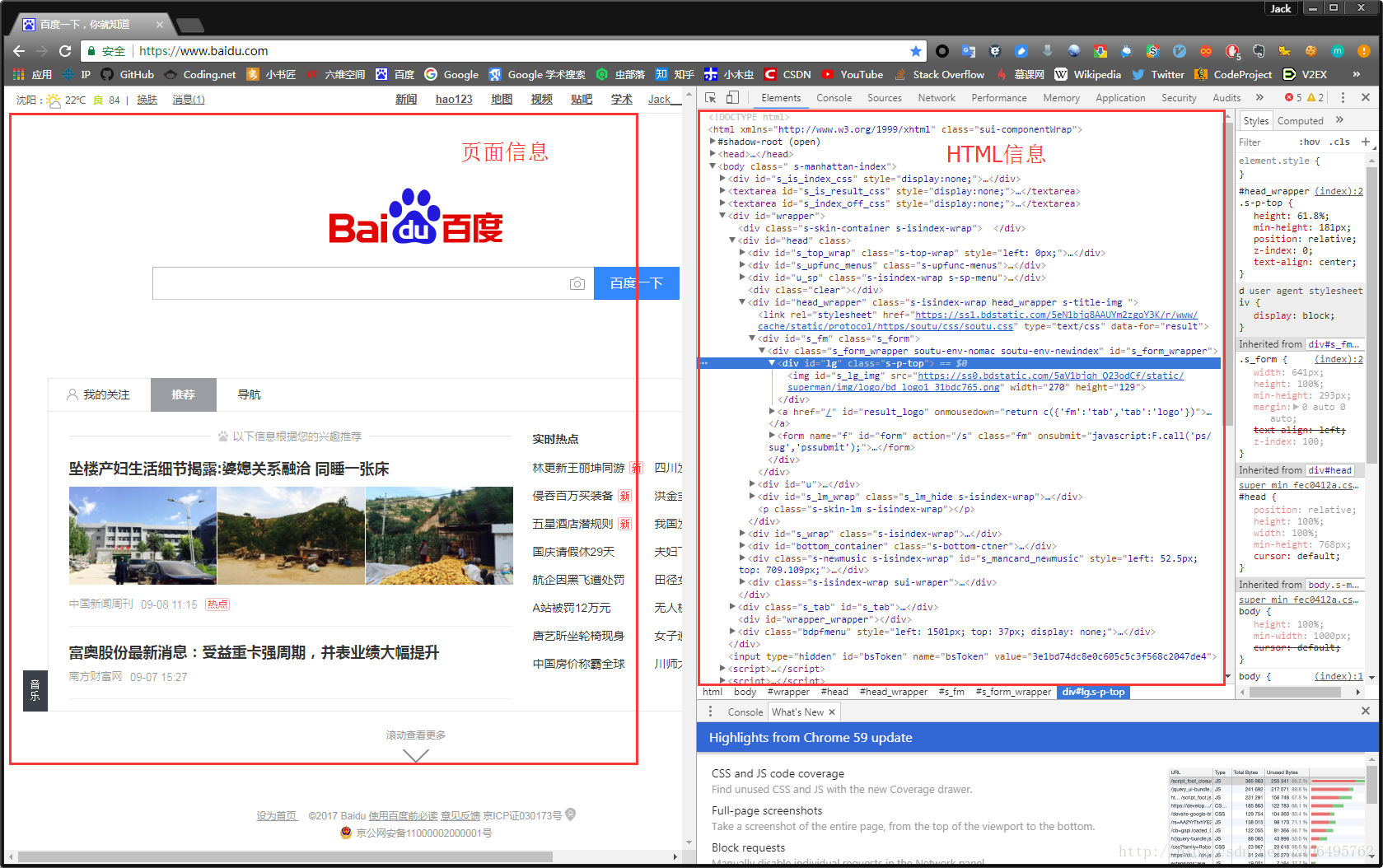
爲啥說是原始容貌呢?因爲人可以整容啊!扎心了,有木有?那網站也可以”整容”嗎?可以!請看下圖:
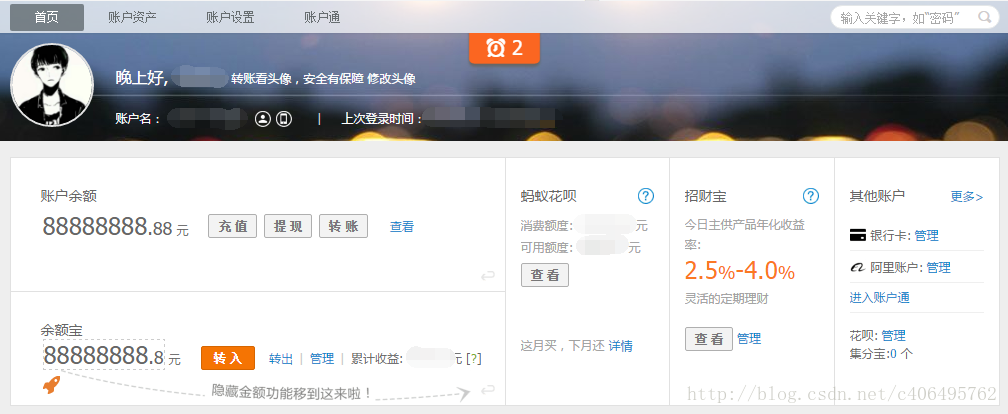
我能有這麼多錢嗎?顯然不可能。我是怎麼給網站”整容”的呢?就是通過修改服務器返回的HTML信息。我們每個人都是”整容大師”,可以修改頁面信息。我們在頁面的哪個位置點擊審查元素,瀏覽器就會爲我們定位到相應的HTML位置,進而就可以在本地更改HTML信息。
再舉個小例子:我們都知道,使用瀏覽器”記住密碼”的功能,密碼會變成一堆小黑點,是不可見的。可以讓密碼顯示出來嗎?可以,只需給頁面”動個小手術”!以淘寶爲例,在輸入密碼框處右鍵,點擊檢查。