




1. 列出分期貸款明細
題目介紹:loan 表存儲着貸款信息,包括貸款 ID,貸款總額、按月分期數、年利率。數據如下:
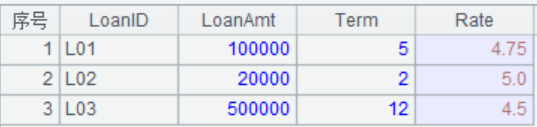
我們的目的是列出各期明細,包括:當期還款額、當期利息、當期本金、剩餘本金。
esproc

A3:T.derive()新增兩列月利率mRate=年利率/12,每期還款數mPayment=總利息/((1+月利率)的期數次冪)-1
A4:A.news(X;xi:Fi,…),根據序表/排列A,計算排列X後把計算後的字段合併到一個新的序表/排列,Fi爲新字段名,xi爲計算結果,Fi省略自動識別。當參數xi使用#i時,表示第i列,此時使用原列名。這裏解釋一下,將t的初始值設置爲A3中的LoanAmt的值作爲初始的本金,然後建立新表,其中利息interest=本金*月利率mRate,當期償還的本金principal等於每期還款數payment-利息,剩餘的本金=本金t-當期償還的本金,然後把剩餘的本金更新到t作爲下一期的本金。
python:
import time
import numpy as np
import pandas as pd
s = time.time()
loan_data = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\loan.csv',sep='\t')
loan_data['mrate'] = loan_data['Rate']/(100*12)
loan_data['mpayment'] = loan_data['LoanAmt']*loan_data['mrate']*np.power(1+loan_data['mrate'],loan_data['Term']) \
/(np.power(1+loan_data['mrate'],loan_data['Term'])-1)
loan_term_list = []
for i in range(len(loan_data)):
loanid = np.tile(loan_data.loc[i]['LoanID'],loan_data.loc[i]['Term'])
loanid = np.tile(loan_data.loc[i]['LoanID'],loan_data.loc[i]['Term'])
loanamt = np.tile(loan_data.loc[i]['LoanAmt'],loan_data.loc[i]['Term'])
term = np.tile(loan_data.loc[i]['Term'],loan_data.loc[i]['Term'])
rate = np.tile(loan_data.loc[i]['Rate'],loan_data.loc[i]['Term'])
payment = np.tile(np.array(loan_data.loc[i]['mpayment']),loan_data.loc[i]['Term'])
interest = np.zeros(len(loanamt))
principal = np.zeros(len(loanamt))
principalbalance = np.zeros(len(loanamt))
loan_amt = loanamt[0]
for j in range(len(loanamt)):
interest[j] = loan_amt*loan_data.loc[i]['mrate']
principal[j] = payment[j] - interest[j]
principalbalance[j] = loan_amt - principal[j]
loan_amt = principalbalance[j]
loan_data_df = pd.DataFrame(np.transpose(np.array([loanid,loanamt,term,rate,payment,interest,principal,principalbalance])),
columns = ['loanid','loanamt','term','rate','payment','interest','principal','principalbalance'])
loan_term_list.append(loan_data_df)
loan_term_pay = pd.concat(loan_term_list,ignore_index=True)
print(loan_term_pay)
e = time.time()
print(e-s)新增兩列mrate和mpayment,mpayment的計算方法和esproc的一樣,大家可以參考。
初始化一個空列表用於存放每一個貸款客戶的數據。
循環數據
Df.loc[i][x]取索引爲i字段名爲x的數據,tile(a,x),x是控制a重複幾次的,結果是一個一維數組。
同樣的方法獲得貸款的'loanid','loanamt','term','rate','payment'的字段值,
初始化一個本金爲loanamt的第一個元素。
for循環就是計算['interest','principal','principalbalance']這三個字段值的方法,思路和esproc的思路一樣,只不過esproc支持動態計算而python只能通過構造這個for循環來完成。
Np.array()將list格式的列表轉換成數組。由於這裏的行表示的是每一個字段的值,np.transpose(a)是將數組a轉置。pd.DataFrame()轉成dataframe結構。
pd.concat()將每個貸款的分期信息合併成一個dataframe。
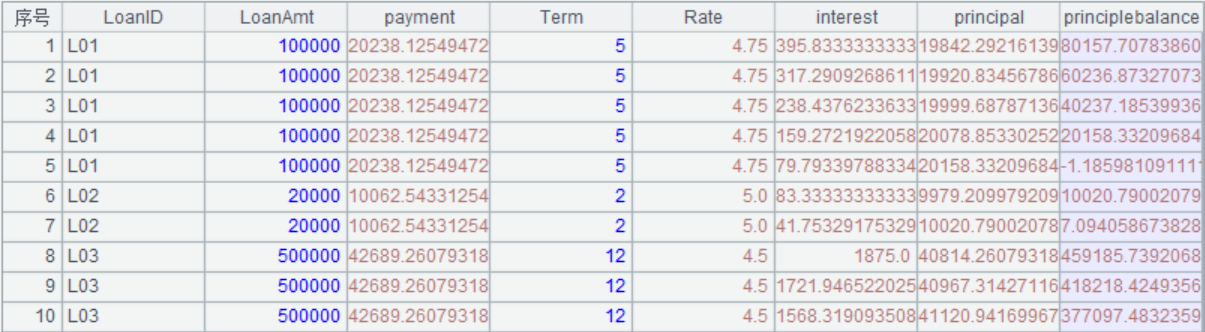
結果:
esproc
python


2.不規則月份統計
題目介紹:如果起始時間是 2014-01-10,則將 2014-01-10 到 2014-02-09 作爲一組,將 2014-02-10 到 2014-03-9 作爲一組。如果起始時間是 2014-01-31,則將 2014-02-27 作爲一組,將 2014-02-28 到 2014-03-30 作爲一組。數據如下:

我們的目的是統計出不規則月份的銷售額AMOUNT。
esproc
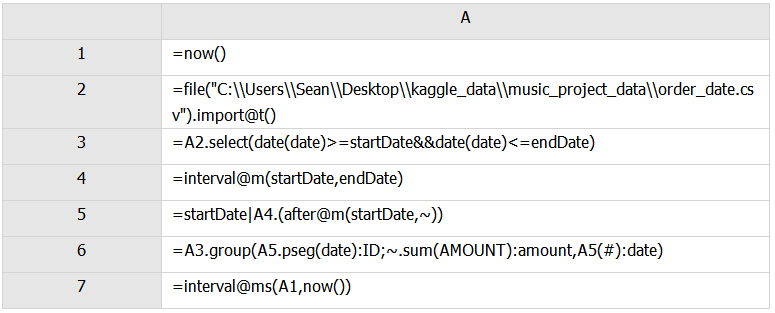
我們首先需要設置網格參數startDate,endDate(程序——網格參數)
A3:篩選出指定時間的時間段
A4:按月計算開始時間和起始時間的間隔
A5:after(start,n)計算從開始時間以後的n天,@m選項表示按月計算,即開始時間以後的n個月。根據起始時間和日期間隔算出不規則月份的開始日期,並將起始時間插入第1位。
A6: A.pseg(x),返回x在A中的哪一段,缺省序列成員組成左閉右開的區間,A必須爲有序序列。 x非A成員時,如果序列升序時x小於序列成員最小值(或序列降序時x大於序列成員最大值)則返回0;如果序列升序時x大於等於序列成員最大值(或序列降序時x小於等於序列成員最小值)則返回序列長度。將日期所在分組作爲ID,銷售額之和作爲amount字段,當前日期作爲date字段,形成序表。
python:
import time
import pandas as pd
import numpy as np
import datetime
s = time.time()
starttime_s = '2012-11-29'
endtime_s = '2013-11-11'
starttime = datetime.datetime.strptime(starttime_s, '%Y-%m-%d')
endtime = datetime.datetime.strptime(endtime_s, '%Y-%m-%d')
orders = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\order_date.csv',sep='\t')
orders['date'] = pd.to_datetime(orders['date'])
orders=orders[orders['date']>=starttime]
orders=orders[orders['date']<=endtime]
date_index = pd.date_range(start = starttime,end=endtime,freq='M')
interv = date_index.day
date_list = []
date_amount = []
for i in range(len(interv)):
if starttime>=date_index[i]:
date_list.append(date_index[i])
else:
date_list.append(starttime)
starttime = starttime + datetime.timedelta(days=int(interv[i]))
if len(date_list)>1:
by = orders['date'].apply(lambda x:date_list[i]>x>=date_list[i-1])
date_amount.append([orders[by]['AMOUNT'].sum(),date_list[i-1]])
by = orders['date'].apply(lambda x:x>=date_list[i])
date_amount.append([orders[by]['AMOUNT'].sum(),date_list[i]])
date_amount_df = pd.DataFrame(date_amount,columns=['amount','date'])
print(date_amount_df)
date_df = pd.Series(date_list)
e = time.time()
print(e-s)小編沒有找到pandas中自動生成不規則月份的方法,所以是自己寫的,如果各位誰知道這種方法,還請不吝賜教。
指定起始時間和終止時間
datetime.datetime.strptime(str, '%Y-%m-%d')將字符串的日期格式轉換爲日期格式
pd.to_datetime()將date列轉換成日期格式
篩選出指定時間段的數據
pd.date_range(start,end,freq)從開始時間到結束時間以freq的間隔生成時間序列,這裏是按月生成。(這裏作出說明,生成的序列成員是每個月的最後一天的日期)
date_index.day生成了這個序列中所有月份的天數
初始化兩個list,date_list用來存放不規則日期的起始時間,date_amount用來存放各個時間段內的銷售額和時間
循環月份總成的天數,如果起始時間晚於這個月的最後一天,則把這個月的最後一天放入date_list,否則把起始時間放入,然後更新起始時間爲起始時間推遲該月的天數後的日期。
如果date_list中的日期數量大於1了,生成一個數組(判斷數據中每個日期是否在該段時間段內,在爲True,否則爲False)。
篩選出在該時間段內數據中的銷售額AMOUNT字段,求其和,並將其和日期放入初始化的date_amount列表中。
pd.DataFrame()生成結果
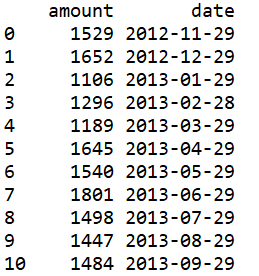
結果:
esproc

python

3.字段分段
題目介紹:庫表data有兩個字段,ID和ANOMOALIES,數據如下:
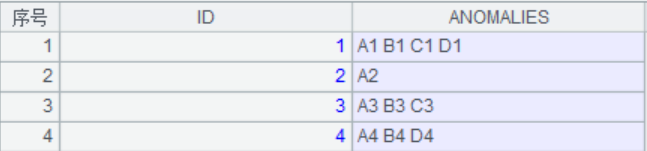
我們的目的是將ANOMOALIES字段按空格拆分爲多個字符串,每個字符串和原ID字段形成新的記錄。
esproc
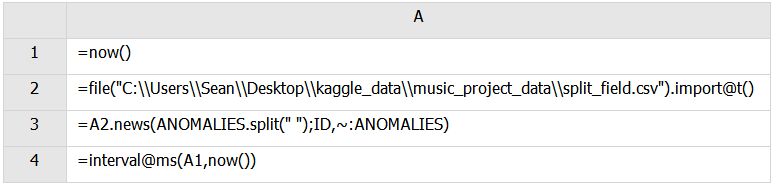
A4:news函數的用法在第一例中已經解釋過,這裏不再贅述。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
split_field = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\split_field.csv',sep='\t')
split_dict = split_field.set_index('ID').T.to_dict('list')
split_list = []
for key,value in split_dict.items():
anomalies = value[0].split(' ')
key_array = np.tile(key,len(anomalies))
split_df = pd.DataFrame(np.array([key_array,anomalies]).T,columns=['ID','ANOMALIES'])
#split_df = pd.DataFrame(np.transpose(np.array([key_array,anomalies])),columns=['ID','ANOMALIES'])
split_list.append(split_df)
split_field = pd.concat(split_list,ignore_index=True)
print(split_field)
e = time.time()
print(e-s)df.set_index(F)設置索引爲F,df.T,將df的行列轉置,df.to_dict(‘list’)將dataframe轉換成字典,字段的key爲df的字段名,value爲df的字段值形成的list。
初始化一個空list,用於存放每個ANOMALIES字段拆分以後的dataframe
循環字典
將value的第一個元素按照空格切分,形成一個列表anomalies
根據這個列表長度複製key的值,形成數組key_array
將np.array([key_array,anomalies])將他們轉換成數組,array.T,將數組轉置(轉置也可以用註釋掉的那行代碼np.traspose()函數),然後由pd.DataFrame()轉成dataframe。
最後連接dataframe,得到結果。
結果:
esproc
python


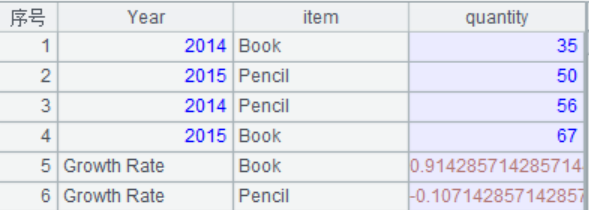
4.增加增長率記錄
esproc
A4:T.sort(x),按照x表達式排序,T.group(x)按照x表達式分組。A.run(x),針對序列/排列A中每個成員計算表達式x。T.record(A,k) 從T中指定位置k的記錄開始,用A的成員依次修改T序表中記錄的每個字段值,k省略時從最後一條開始增加記錄。~表示當前分組,~(2)表示第二條記錄即2015年的記錄,~(1)表示2014年的記錄。這裏的過程是先按照Year字段排序,然後按照item分組,然後新增兩條記錄,分別是各種物品的增長率。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
store_q = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\store_quantity.csv',sep='\t')
store_q.sort_values(by='Year',inplace = True)
store_q_g = store_q.groupby(by='item',as_index=False)
growth_rate_list=[]
for index,group in store_q_g:
growth_rate = group['quantity']/group['quantity'].shift(1)-1
growth_rate_list.append(['growth_rate',index,growth_rate.values[1]])
store_rate = pd.concat([store_q,pd.DataFrame(growth_rate_list,columns=['Year','item','quantity'])])
print(store_rate)
e = time.time()
print(e-s)df.sort_values(by,inplace),按照Year字段排序,更新到元數據中
df.groupby(by, as_index),按照item分組,不把item作爲索引
初始化一個list用來存放各組的結果
循環分組,df.shift(1)是將df下移一行,(當前行/上一行)-1得到增長率。
由於只有兩年的記錄所以增長率的第二個元素即爲需要的增長率。將growth_rate,index,增長率放入初始化的list中
pd.Dataframe()和pd.concat()大家應該很熟了,這裏不再贅述了。
結果:
esproc
python
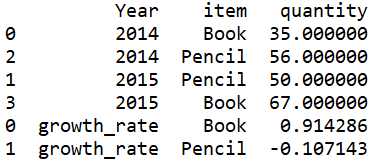

5.合併重複記錄
題目介紹:該數據沒有字段,第一行就是數據,數據如下:

我們的目的是過濾掉重複的記錄,取出前6列,並重整第7,8兩列,具體要求是:將wrok phone作爲新文件第7列,將work email作爲新文件第8列,如果有多個work phone或work email,則只取第一個。
esproc

A2:這裏解釋下f.import(),導入數據,@t是要把第一列作爲字段名,@c是按照逗號分隔。
A3:按照_1,_2,_3,_4,_5,_6分組,每組選擇一條記錄select@1()是取序列中第一條符合條件的成員,如果第7個字段是work phone則取第八個字段的值作爲work_phone字段,如果分組中第7個字段是work email則取第八個字段作爲work_email字段。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
merge_dup = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\merge_duplicate.csv',header=None)
merge_dup_g = merge_dup.groupby(by=[0,1,2,3,4,5],as_index=False)
work_arr = np.zeros(len(merge_dup.columns))
work_list = []
for index,group in merge_dup_g:
work_arr = group.iloc[0].values
work_arr[6] = work_arr[7]
work_arr[7] = group[group[6]=='work email'].iloc[0].values[7]
work_list.append(work_arr)
merge_dup = pd.DataFrame(work_list,columns=merge_dup.columns)
merge_dup.rename(columns={6:'work_phone',7:'work_email'},inplace=True)
print(merge_dup)
e = time.time()
print(e-s)按照前6個字段進行分組
因爲題目要求我們把work phone 和work email拿出來作爲字段,所以源數據的字段數沒變,df.columns得到df的字段名,np.zeros()初始化一個數組。
循環分組
取分組中第6個字段等於work phone的第一行的值,賦值給初始化的數組
修改數組第7個元素(索引是6)爲數組的第8個元素(索引是7)
取分組中第6個字段等於work email的第一行的值的第8個元素(索引是7),賦值給數組的第8個元素(索引是7)。
將結果放入初始化的list中
轉換成dataframe。
df.rename(columns,inplace)修改字段名,更新到源數據上。
結果:
esproc

python


6. 準備測試數據
esproc

A2: 定義一個數字,用來確定創建多少員工信息,這裏準備的數據比較少,感興趣的同學可以多準備些,這裏是男員工名字45,女員工名字47,姓47,所以最多可以創建(45+47)*47=4324條員工信息,因此這個數字不能大於4324。
A8:男員工名字新增一個字段GENDER,賦值M
A10:合併男女員工的姓名
A11:根據STATEID爲city表增加state表中的ABBR字段並設置成city表的ABBR字段
A12:按照A10表合併姓名和姓。A.conj()將序列和列。得到(45+47)*47個姓名和GENDER,sort(rand())將表隨機排列,這是相對於news()的另一種寫法,感興趣的同學可以嘗試改寫成news()的寫法。
A13:新建表,定義兩個變量,birthday:18+rand(18),表示年齡在18至35週歲,用今年的年份減去年齡,得到出生的年份的一月一日。city:從city表中隨機選取一條記錄。定義變量是可以在計算的時候定義的,計算完成後賦值給變量,後續的計算可以直接使用這個變量,這使表達式顯得簡潔。最終的BIRTHDAY字段爲從那年的1月1日,隨機推遲那年的天數的時間,得到生日。city去city表的NAME字段,STATE去city表的ABBR字段。
python:
import time
import pandas as pd
import numpy as np
import datetime
import random
s = time.time()
data_quantity = 1000
m_name = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\M_name.txt',sep='\t')
f_name = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\F_name.txt',sep='\t')
s_name = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\S_name.txt',sep='\t')
cities = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\cities.txt',sep='\t')
states = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\states.txt',sep='\t')
m_name['GENDER'] = 'M'
f_name['GENDER'] = 'F'
name = pd.concat([m_name,f_name])
name['FULL_NAME']=1
s_name['FULL_NAME']=1
name = pd.merge(name,s_name,on='FULL_NAME')
name['FULL_NAME']=name['NAME']+' '+name['S_name']
city_state = pd.merge(cities[['NAME','STATEID']],states[['ABBR','STATEID']],on='STATEID')
birth_list = []
city_list = []
state_list = []
for i in range(data_quantity):
age = random.randint(18,35)
birth_y = datetime.datetime.today().year-age
birthday = datetime.datetime(birth_y,1,1).date()
year_days = int(datetime.date(birth_y,12,31).strftime('%j'))
birthday = birthday + datetime.timedelta(days=random.randint(0,year_days))
birth_list.append(birthday)
rand_index = random.randint(0,len(city_state)-1)
city_list.append(city_state['NAME'].loc[rand_index])
state_list.append(city_state['ABBR'].loc[rand_index])
rand_arr = np.random.randint(0,len(name),data_quantity)
person = name[['FULL_NAME','GENDER']].loc[rand_arr]
person['ID']=np.arange(data_quantity)
person['BIRTHDAY'] = birth_list
person['CITY'] = city_list
person['STATE'] = state_list
person = person.rename(columns={'FULL_NAME':'NAME'}).reset_index(drop=True)
print(person[['ID','NAME','GENDER','BIRTHDAY','CITY','STATE']])
e = time.time()
print(e-s)新增字段,縱向和橫向合併dataframe,我們在前邊的例子已經多次用到了,這裏不再贅述
簡單解釋一下姓名合併的問題,由於兩個dataframe沒有共同的字段作爲key,所以我們造了一個字段FULL_NAME,賦值爲1,只爲進行merge。
定義三個list,分別用來生成BIRTHDAY,CITY,STATE列
把年齡定義在18-35之間,由年齡生成隨機的生日,然後放入定義好的list中
CITY和STATE字段的值是利用loc[]函數,隨機取,並放入定義好的list中
定義一個數組,隨機生成name數據的索引
通過loc[rand_arr]函數,取隨機的1000個,生成FULL_NAME和GENDER字段。
np.arange(n)生成n個元素的一維數組,作爲ID字段。
然後把剛纔的三個list賦值給BIRTHDAY,CITY,STATE。
rename()將FULL_NAME字段名改爲NAME,重新設置索引並將原來的索引丟棄。
生成最終結果。
結果:
esproc
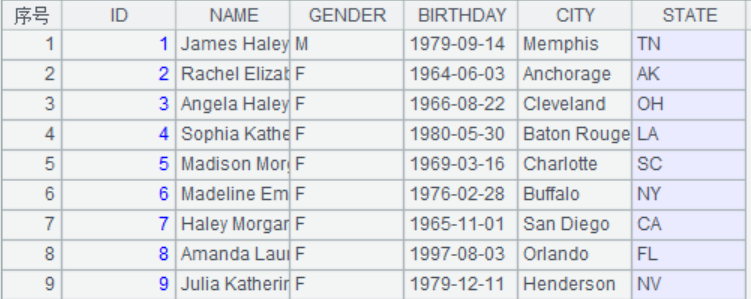
python


小結:本節我們繼續計算一些網上常見的題目,由於pandas依賴於另一個第三方庫numpy,而numpy的數組元素只能通過循環一步一步進行更新,esproc的循環函數如new()、select()等都可以動態更新字段值,使得代碼簡單。在第二例中,日期處理時,esproc可以很輕鬆的劃分出不規則的月份,並根據不規則月份進行計算。而python劃分不規則月份時需要額外依賴datetime庫,還要自行根據月份天數劃分,實在是有些麻煩。