




MySQL裏查詢表裏的重複數據記錄:
先查看重複的原始數據:
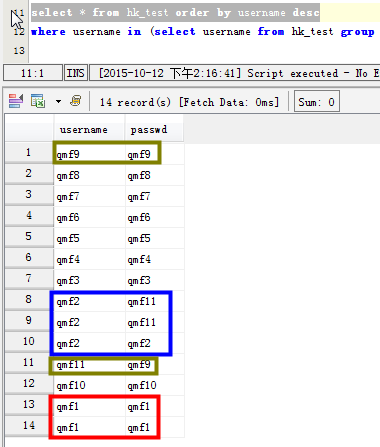
場景一:列出username字段有重讀的數據
1 2 3 | select username,count(*) as count from hk_test group by username having count>1;SELECT username,count(username) as count FROM hk_test GROUP BY username HAVING count(username) >1 ORDER BY count DESC; |
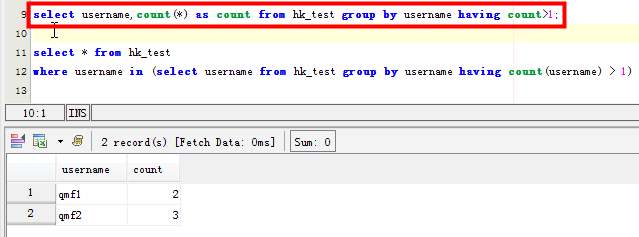
這種方法只是統計了該字段重複對應的具體的個數
場景二:列出username字段重複記錄的具體指:
1 2 3 4 5 | select * from hk_test where username in (select username from hk_test group by username having count(username) > 1)SELECT username,passwd FROM hk_test WHERE username in ( SELECT username FROM hk_test GROUP BY username HAVING count(username)>1)但是這條語句在mysql中效率太差,感覺mysql並沒有爲子查詢生成臨時表。在數據量大的時候,耗時很長時間 |
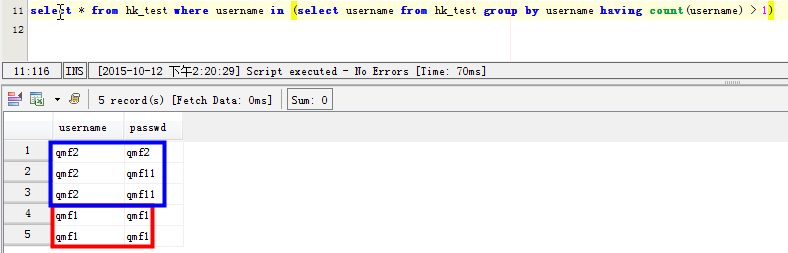
解決方法:

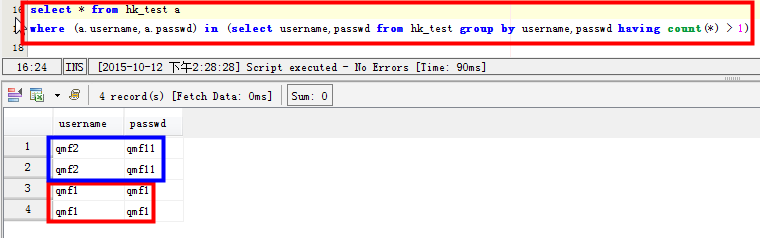
場景三:查看兩個字段都重複的記錄:比如username和passwd兩個字段都有重複的記錄:
1 2 | select * from hk_test awhere (a.username,a.passwd) in (select username,passwd from hk_test group by username,passwd having count(*) > 1) |
場景四:查詢表中多個字段同時重複的記錄:
1 | select username,passwd,count(*) from hk_test group by username,passwd having count(*) > 1 |
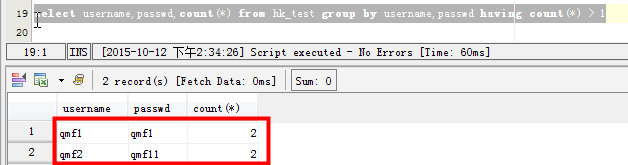
參數說明:
user_name爲要查找的重複字段.
count用來判斷大於一的纔是重複的.
user_table爲要查找的表名.
group by用來分組
having用來過濾.