




pytorch代碼鏈接:https://github.com/amdegroot/ssd.pytorch
總的框架圖如下:
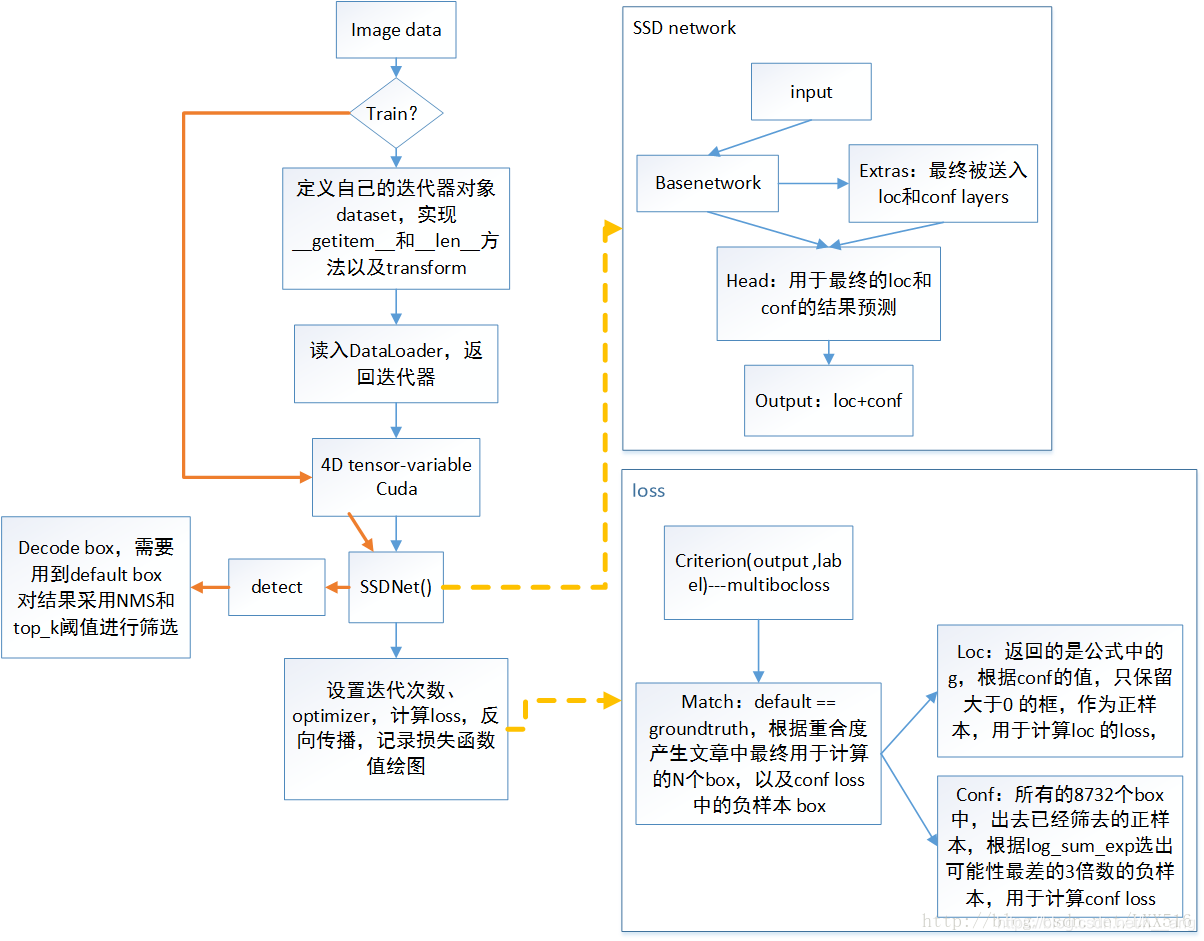
一. ssd.py及其相關函數類
1. VGG
SSD 使用了VGG16(D)卷積部分(5層卷積,一般標記爲Conv5)作爲基礎網絡,後面加了 1024 × 3 × 3、1024 × 1 × 1 兩個卷積層,這兩個卷積層後都有 RELU 層。
對應的網絡結構如下圖,紅線以上部分是VGG16本來就有的卷積層,紅線下面的兩層是新添加的層,紅框框住的兩個層Conv2d-4_3、Conv2d-7_1是要用來做特徵提取的層。
這部分的代碼對應的是ssd.py裏面的vgg函數:
# vgg([64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
# 512, 512, 512], 3)
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers

2. 輔助特徵層
紅框框選的卷積層(Conv2d-2_1、Conv2d-4_1、Conv2d-6_1、Conv2d-8_1)用於多尺度特徵提取。對應的是ssd.py中的add_extras函數:
# add_extras([256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256], 1024)
def add_extras(cfg, i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layers

3. multibox函數
可以看出來,有四個參數,分別是VGG網絡層、新添加的extras層、要做特徵提取的6個層中每個網格單元對應的default box個數、總的類別數(20+背景類=21).
# multibox(vgg, extra_layers, [4, 6, 6, 6, 4, 4], 21)
def multibox(vgg, extra_layers, cfg, num_classes):
#
loc_layers = []
conf_layers = []
vgg_source = [21, -2]
# 對vgg網絡結構中的Conv2d-4_3、Conv2d-7_1層通過卷積提取特徵
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * num_classes, kernel_size=3, padding=1)]
# 對extra_layers中的(Conv2d-2_1、Conv2d-4_1、Conv2d-6_1、Conv2d-8_1)層通過卷積提取特徵
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, cfg[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, cfg[k]
* num_classes, kernel_size=3, padding=1)]
return vgg, extra_layers, (loc_layers, conf_layers)
4. build_ssd函數——外部調用的接口函數
train,py中的調用方式:
ssd_net = build_ssd('train', cfg['min_dim'], cfg['num_classes'])
下面是bulid_ssd函數:
def build_ssd(phase, size=300, num_classes=21):
if phase != "test" and phase != "train":
print("ERROR: Phase: " + phase + " not recognized")
return
if size != 300:
print("ERROR: You specified size " + repr(size) + ". However, " +
"currently only SSD300 (size=300) is supported!")
return
# vgg([64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
# 512, 512, 512], 3)
# add_extras([256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256], 1024)
# mbox['300'] = [4, 6, 6, 6, 4, 4]
# num_classes = 21
base_, extras_, head_ = multibox(vgg(base[str(size)], 3),
add_extras(extras[str(size)], 1024),
mbox[str(size)], num_classes)
return SSD(phase, size, base_, extras_, head_, num_classes)
可以看到,將multibox的三個返回值分別傳入base_、extras_、head_中,然後調用SSD生成網絡結構。
4. PriorBox類
在這個代碼裏,cfg=voc,我們可以config.py裏面對voc的定義:
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
我們注意到有這樣一組參數voc[‘steps’] = [8, 16, 32, 64, 100, 300],它實際上是根據本層特徵圖與輸入圖片之間點得映射關係得到得,不瞭解得可以看這篇鏈接:https://zhuanlan.zhihu.com/p/60919662
PriorBox返回得是所有default box得四個參數歸一化後的值,即得到所有先驗框的位置。
class PriorBox(object):
"""Compute priorbox coordinates in center-offset form for each source
feature map.
"""
def __init__(self, cfg):
super(PriorBox, self).__init__()
self.image_size = cfg['min_dim']
# number of priors for feature map location (either 4 or 6)
self.num_priors = len(cfg['aspect_ratios'])
self.variance = cfg['variance'] or [0.1]
self.feature_maps = cfg['feature_maps']
self.min_sizes = cfg['min_sizes']
self.max_sizes = cfg['max_sizes']
self.steps = cfg['steps']
self.aspect_ratios = cfg['aspect_ratios']
self.clip = cfg['clip']
self.version = cfg['name']
for v in self.variance:
if v <= 0:
raise ValueError('Variances must be greater than 0')
def forward(self):
mean = []
# self.feature_maps = [38, 19, 10, 5, 3, 1]
for k, f in enumerate(self.feature_maps):
# (i,j)爲要提取特徵得層中每個網格得左上角得座標
for i, j in product(range(f), repeat=2):
f_k = self.image_size / self.steps[k]
# unit center x,y
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
# aspect_ratio: 1
# rel size: min_size
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
# aspect_ratio: 1
# rel size: sqrt(s_k * s_(k+1))
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
# rest of aspect ratios
for ar in self.aspect_ratios[k]:
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
# back to torch land
output = torch.Tensor(mean).view(-1, 4)
# 歸一化,將output限制在 [0, 1] 之間
if self.clip:
output.clamp_(max=1, min=0)
return output
5. SSD類
下面是構建整體的網絡結構:
# SSD("train", 300, base_, extras_, head_, num_classes)
class SSD(nn.Module):
"""Single Shot Multibox Architecture
The network is composed of a base VGG network followed by the
added multibox conv layers. Each multibox layer branches into
1) conv2d for class conf scores
2) conv2d for localization predictions
3) associated priorbox layer to produce default bounding
boxes specific to the layer's feature map size.
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
Args:
phase: (string) Can be "test" or "train"
size: input image size
base: VGG16 layers for input, size of either 300 or 500
extras: extra layers that feed to multibox loc and conf layers
head: "multibox head" consists of loc and conf conv layers
"""
def __init__(self, phase, size, base, extras, head, num_classes):
super(SSD, self).__init__()
# phase——"test" or "train"
self.phase = phase
self.num_classes = num_classes
# if num_classes = 21, cfg = voc,else cfg = coco
self.cfg = (coco, voc)[num_classes == 21]
self.priorbox = PriorBox(self.cfg)
self.priors = Variable(self.priorbox.forward(), volatile=True)
self.size = size
# SSD network
self.vgg = nn.ModuleList(base)
# Layer learns to scale the l2 normalized features from conv4_3
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras)
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 0, 200, 0.01, 0.45)
def forward(self, x):
"""Applies network layers and ops on input image(s) x.
Args:
x: input image or batch of images. Shape: [batch,3,300,300].
Return:
Depending on phase:
test:
Variable(tensor) of output class label predictions,
confidence score, and corresponding location predictions for
each object detected. Shape: [batch,topk,7]
train:
list of concat outputs from:
1: confidence layers, Shape: [batch*num_priors,num_classes]
2: localization layers, Shape: [batch,num_priors*4]
3: priorbox layers, Shape: [2,num_priors*4]
"""
sources = list()
loc = list()
conf = list()
# apply vgg up to conv4_3 relu
for k in range(23):
x = self.vgg[k](x)
s = self.L2Norm(x)
sources.append(s)
# apply vgg up to fc7
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
# apply extra layers and cache source layer outputs
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
# apply multibox head to source layers
# [b, C, H, W]——[b, H, W, C],因爲我們最後要在通道這個維度上做softmax
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output
def load_weights(self, base_file):
other, ext = os.path.splitext(base_file)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
self.load_state_dict(torch.load(base_file,
map_location=lambda storage, loc: storage))
print('Finished!')
else:
print('Sorry only .pth and .pkl files supported.')
測試時和訓練時的網絡結構不同,可以看到,在測試時,我們將loc_preds、conf_preds、default boxes的座標作爲三個參數送入Detect函數中,而在訓練時沒有最後的檢測這一步。同時我們注意到測試時的conf_preds是過了softmax函數做了歸一化的。
6. Detection類
6.1 box_utils.py裏面的函數
decode是根據下面着四個公式求得
def encode(matched, priors, variances):
"""Encode the variances from the priorbox layers into the ground truth boxes
we have matched (based on jaccard overlap) with the prior boxes.
Args:
matched: (tensor) Coords of ground truth for each prior in point-form
Shape: [num_priors, 4].
priors: (tensor) Prior boxes in center-offset form
Shape: [num_priors,4].
variances: (list[float]) Variances of priorboxes
Return:
encoded boxes (tensor), Shape: [num_priors, 4]
"""
# dist b/t match center and prior's center
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
# encode variance
g_cxcy /= (variances[0] * priors[:, 2:])
# match wh / prior wh
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
# return target for smooth_l1_loss
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
# Adapted from https://github.com/Hakuyume/chainer-ssd
def decode(loc, priors, variances):
"""Decode locations from predictions using priors to undo
the encoding we did for offset regression at train time.
Args:
loc (tensor): location predictions for loc layers,
Shape: [num_priors,4]
priors (tensor): Prior boxes in center-offset form.
Shape: [num_priors,4].
variances: (list[float]) Variances of priorboxes
Return:
decoded bounding box predictions
"""
# 對應上面的四個解碼公式
boxes = torch.cat((
priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
# 將(x_center, y_center, w, h)轉換爲(xmin, ymin, xmax, ymax)
boxes[:, :2] -= boxes[:, 2:] / 2
boxes[:, 2:] += boxes[:, :2]
return boxes
def nms(boxes, scores, overlap=0.5, top_k=200):
"""Apply non-maximum suppression at test time to avoid detecting too many
overlapping bounding boxes for a given object.
Args:
boxes: (tensor) The location preds for the img, Shape: [num_priors,4].
scores: (tensor) The class predscores for the img, Shape:[num_priors].
overlap: (float) The overlap thresh for suppressing unnecessary boxes.
top_k: (int) The Maximum number of box preds to consider.
Return:
The indices of the kept boxes with respect to num_priors.
"""
keep = scores.new(scores.size(0)).zero_().long()
if boxes.numel() == 0:
return keep
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = torch.mul(x2 - x1, y2 - y1)
v, idx = scores.sort(0) # sort in ascending order
# I = I[v >= 0.01]
idx = idx[-top_k:] # indices of the top-k largest vals
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
# keep = torch.Tensor()
count = 0
while idx.numel() > 0:
i = idx[-1] # index of current largest val
# keep.append(i)
keep[count] = i
count += 1
if idx.size(0) == 1:
break
idx = idx[:-1] # remove kept element from view
# load bboxes of next highest vals
torch.index_select(x1, 0, idx, out=xx1)
torch.index_select(y1, 0, idx, out=yy1)
torch.index_select(x2, 0, idx, out=xx2)
torch.index_select(y2, 0, idx, out=yy2)
# store element-wise max with next highest score
xx1 = torch.clamp(xx1, min=x1[i])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = torch.clamp(w, min=0.0)
h = torch.clamp(h, min=0.0)
inter = w*h
# IoU = i / (area(a) + area(b) - i)
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i]
IoU = inter/union # store result in iou
# keep only elements with an IoU <= overlap
idx = idx[IoU.le(overlap)]
return keep, count
計算IOU的函數如下:
def intersect(box_a, box_b):
""" We resize both tensors to [A,B,2] without new malloc:
[A,2] -> [A,1,2] -> [A,B,2]
[B,2] -> [1,B,2] -> [A,B,2]
Then we compute the area of intersect between box_a and box_b.
Args:
box_a: (tensor) bounding boxes, Shape: [A,4].
box_b: (tensor) bounding boxes, Shape: [B,4].
Return:
(tensor) intersection area, Shape: [A,B].
"""
A = box_a.size(0)
B = box_b.size(0)
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
return inter[:, :, 0] * inter[:, :, 1]
def jaccard(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes. The jaccard overlap
is simply the intersection over union of two boxes. Here we operate on
ground truth boxes and default boxes.
E.g.:
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
Args:
box_a: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
box_b: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
Return:
jaccard overlap: (tensor) Shape: [box_a.size(0), box_b.size(0)]
"""
# 計算 A ∩ B
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2]-box_a[:, 0]) *
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) *
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
# 計算 A ∪ B
union = area_a + area_b - inter
return inter / union # [A,B]
二. 損失函數
損失包括兩個部分,loc損失+conf損失,想通過match函數將default boxes與ground truth匹配,確定正負樣本,然後只對正樣本計算loc損失;然後對負樣本採用hard negative mining挑選出對conf損失貢獻最大的一部分負樣本(數量大概是正樣本的3倍)。
class MultiBoxLoss(nn.Module):
"""SSD Weighted Loss Function
Compute Targets:
1) Produce Confidence Target Indices by matching ground truth boxes
with (default) 'priorboxes' that have jaccard index > threshold parameter
(default threshold: 0.5).
2) Produce localization target by 'encoding' variance into offsets of ground
truth boxes and their matched 'priorboxes'.
3) Hard negative mining to filter the excessive number of negative examples
that comes with using a large number of default bounding boxes.
(default negative:positive ratio 3:1)
Objective Loss:
L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
Where, Lconf is the CrossEntropy Loss and Lloc is the SmoothL1 Loss
weighted by α which is set to 1 by cross val.
Args:
c: class confidences,
l: predicted boxes,
g: ground truth boxes
N: number of matched default boxes
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
"""
# MultiBoxLoss(21, 0.5, True, 0, True, 3, 0.5, False, args.cuda)
def __init__(self, num_classes, overlap_thresh, prior_for_matching,
bkg_label, neg_mining, neg_pos, neg_overlap, encode_target,
use_gpu=True):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh
self.background_label = bkg_label
self.encode_target = encode_target
self.use_prior_for_matching = prior_for_matching
self.do_neg_mining = neg_mining
self.negpos_ratio = neg_pos
self.neg_overlap = neg_overlap
self.variance = cfg['variance']
def forward(self, predictions, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
targets (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
"""
loc_data, conf_data, priors = predictions
num = loc_data.size(0) # batch size
priors = priors[:loc_data.size(1), :] # feel no use
num_priors = (priors.size(0))
num_classes = self.num_classes
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
# 用來記錄每一個default box的類別,0類就是負樣本
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:, :-1].data
labels = targets[idx][:, -1].data
defaults = priors.data # [num_priors, 4]
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
# 經過match之後對default boxes進行了匹配,得到了正負樣本的信息以及偏移量的標籤
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
# wrap targets
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
pos = conf_t > 0
num_pos = pos.sum(dim=1, keepdim=True)
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
# 獲得正樣本的索引,在計算loc損失函數時我們只關注正樣本
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# Hard Negative Mining
loss_c[pos] = 0 # filter out pos boxes for now
loss_c = loss_c.view(num, -1)
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
# 獲得負樣本的default box索引
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = num_pos.data.sum()
loss_l /= N
loss_c /= N
return loss_l, loss_c
match函數主要負責:
- conf_t記錄的是每一個default box匹配的gt的類別,0代表背景類,也即爲負樣本;
- encode(matches,priors,variances)得到loc損失中的,放在loc[idx]裏面;
# match(0.5, truths, defaults, [0.1, 0.2], labels, loc_t, conf_t, idx)
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
"""Match each prior box with the ground truth box of the highest jaccard
overlap, encode the bounding boxes, then return the matched indices
corresponding to both confidence and location preds.
Args:
threshold: (float) The overlap threshold used when mathing boxes.
truths: (tensor) Ground truth boxes, Shape: [num_obj, num_priors].
priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
variances: (tensor) Variances corresponding to each prior coord,
Shape: [num_priors, 4].
labels: (tensor) All the class labels for the image, Shape: [num_obj].
loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
idx: (int) current batch index
Return:
The matched indices corresponding to 1)location and 2)confidence preds.
"""
# jaccard index,計算每一個ground truth和每一個default boxea之間的IOU, [num_objects, num_priors]
overlaps = jaccard(
truths,
point_form(priors) # 將priors由(x_center, y_center, w, h)轉換爲(xmin, ymin, xmax, ymax)
)
# (Bipartite Matching)
# [1,num_objects] best prior for each ground truth
# 爲每一個ground truth匹配到和它IOU最大的default box
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
# [1,num_priors] best ground truth for each prior
# 爲每一個default box匹配到和它IOU最大的gt
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
# 保證了每個ground truth至少有一個default box與之匹配
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
# TODO refactor: index best_prior_idx with long tensor
# ensure every gt matches with its prior of max overlap
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
# Shape: [num_priors,4],在每一個priors的位置記錄下對應的truth的loc信息,以便利用調用encode得到計算損失函數時的標籤
matches = truths[best_truth_idx]
conf = labels[best_truth_idx] + 1 # Shape: [num_priors],+1是因爲0類是背景類
conf[best_truth_overlap < threshold] = 0 # label as background
loc = encode(matches, priors, variances)
loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
conf_t[idx] = conf # [num_priors] top class label for each prior
# Original author: Francisco Massa:
# https://github.com/fmassa/object-detection.torch
# Ported to PyTorch by Max deGroot (02/01/2017)
def nms(boxes, scores, overlap=0.5, top_k=200):
"""Apply non-maximum suppression at test time to avoid detecting too many
overlapping bounding boxes for a given object.
Args:
boxes: (tensor) The location preds for the img, Shape: [num_priors,4].
scores: (tensor) The class predscores for the img, Shape:[num_priors].
overlap: (float) The overlap thresh for suppressing unnecessary boxes.
top_k: (int) The Maximum number of box preds to consider.
Return:
The indices of the kept boxes with respect to num_priors.
"""
keep = scores.new(scores.size(0)).zero_().long()
if boxes.numel() == 0:
return keep
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = torch.mul(x2 - x1, y2 - y1)
v, idx = scores.sort(0) # sort in ascending order
# I = I[v >= 0.01]
idx = idx[-top_k:] # indices of the top-k largest vals
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
# keep = torch.Tensor()
count = 0
while idx.numel() > 0:
i = idx[-1] # index of current largest val
# keep.append(i)
keep[count] = i
count += 1
if idx.size(0) == 1:
break
idx = idx[:-1] # remove kept element from view
# load bboxes of next highest vals
# 從x1, y1, x2, y2將idx對應的bounding boxes的信息賦給xx1, yy1, xx2, yy2
torch.index_select(x1, 0, idx, out=xx1)
torch.index_select(y1, 0, idx, out=yy1)
torch.index_select(x2, 0, idx, out=xx2)
torch.index_select(y2, 0, idx, out=yy2)
# store element-wise max with next highest score
# 用xx1, yy1, xx2, yy2與目前作爲基準的default box的x1, y1, x2, y2比較,目的是下面的IOU計算
xx1 = torch.clamp(xx1, min=x1[i])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = torch.clamp(w, min=0.0)
h = torch.clamp(h, min=0.0)
inter = w*h
# IoU = i / (area(a) + area(b) - i)
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i]
IoU = inter/union # store result in iou
# keep only elements with an IoU <= overlap
idx = idx[IoU.le(overlap)]
return keep, count