




zookeeper集羣搭建
kafka集羣是把狀態保存在zookeeper中的,首先要搭建zookeeper集羣。
1、安裝jdk
wget http://xxxxx.oss-cn-xxxx.aliyuncs.com/xxxx/jdk-8u171-linux-x64.rpm
yum localinstall jdk-8u171-linux-x64.rpm -y2、下載kafka安裝包
wget http://xxx-xx.oss-cn-xxx.aliyuncs.com/xxx/kafka_2.12-1.1.0.tgz
官網下載鏈接:http://kafka.apache.org/downloads解壓kafka
tar -zxvf kafka_2.12-1.1.0.tgz
mv kafka_2.12-1.1.0 kafka
3、配置zk集羣
修改zookeeper.properties文件
直接使用kafka自帶的zookeeper建立zk集羣
cd /data/kafka
vim conf/zookeeper.properties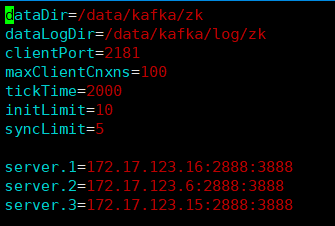
#tickTime:
這個時間是作爲 Zookeeper 服務器之間或客戶端與服務器之間維持心跳的時間間隔,也就是每個 tickTime 時間就會發送一個心跳。
#initLimit:
這個配置項是用來配置 Zookeeper 接受客戶端(這裏所說的客戶端不是用戶連接 Zookeeper 服務器的客戶端,而是 Zookeeper 服務器集羣中連接到 Leader 的 Follower 服務器)初始化連接時最長能忍受多少個心跳時間間隔數。當已經超過 5個心跳的時間(也就是 tickTime)長度後 Zookeeper 服務器還沒有收到客戶端的返回信息,那麼表明這個客戶端連接失敗。總的時間長度就是 5*2000=10 秒
#syncLimit:
這個配置項標識 Leader 與Follower 之間發送消息,請求和應答時間長度,最長不能超過多少個 tickTime 的時間長度,總的時間長度就是5*2000=10秒
#dataDir:
快照日誌的存儲路徑
#dataLogDir:需手動創建
事物日誌的存儲路徑,如果不配置這個那麼事物日誌會默認存儲到dataDir制定的目錄,這樣會嚴重影響zk的性能,當zk吞吐量較大的時候,產生的事物日誌、快照日誌太多
#clientPort:
這個端口就是客戶端連接 Zookeeper 服務器的端口,Zookeeper 會監聽這個端口,接受客戶端的訪問請求。創建myid文件
進入dataDir目錄,將三臺服務器上的myid文件分別寫入1、2、3。
myid是zk集羣用來發現彼此的標識,必須創建,且不能相同。
echo "1" > /data/kafka/zk/myid
echo "2" > /data/kafka/zk/myid
echo "3" > /data/kafka/zk/myid
注意項
zookeeper不會主動的清除舊的快照和日誌文件,需要定期清理。
#!/bin/bash
#snapshot file dir
dataDir=/data/kafka/zk/version-2
#tran log dir
dataLogDir=/data/kafka/log/zk/version-2
#Leave 66 files
count=66
count=$[$count+1]
ls -t $dataLogDir/log.* | tail -n +$count | xargs rm -f
ls -t $dataDir/snapshot.* | tail -n +$count | xargs rm -f
#以上這個腳本定義了刪除對應兩個目錄中的文件,保留最新的66個文件,可以將他寫到crontab中,設置爲每天凌晨2點執行一次就可以了。4、啓動zk服務
進入kafka目錄,執行zookeeper命令
cd /data/kafka
nohup ./bin/zookeeper-server-start.sh config/zookeeper.properties > logs/zookeeper.log 2>&1 &沒有報錯,而且jps查看有zk進程就說明啓動成功了。 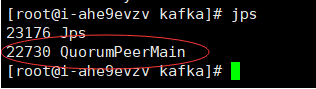
Kafka集羣搭建
1、修改server.properties配置文件
vim conf/server.properties
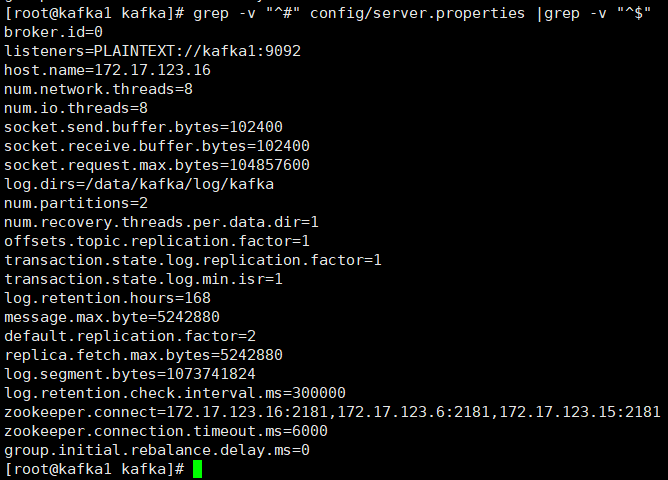
部分參數含義:
先每臺設置host,listeners裏要設置,否則後面消費消息會報錯。
broker.id 每臺都不能相同
num.network.threads 設置爲cpu核數
num.partitions 分區數設置視情況而定,上面有講分區數設置
default.replication.factor kafka保存消息的副本數,如果一個副本失效了,另一個還可以繼續提供服務2、啓動kafka集羣
nohup ./bin/kafka-server-start.sh config/server.properties > logs/kafka.log 2>&1 &執行jps檢查 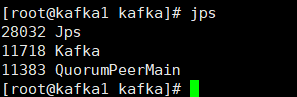
3、創建topic驗證
./bin/kafka-topics.sh --create --zookeeper kafka1:2181,kafka2:2181,kafka3:2181 --replication-factor 2 --partitions 1 --topic test1
--replication-factor 2 #複製兩份
--partitions 1 #創建1個分區
--topic #主題爲test14、創建生產者和消費者
#模擬客戶端去發送消息,生產者
./bin/kafka-console-producer.sh --broker-list kafka1:9092,kafka2:9092,kafka3:9092 --topic test1
#模擬客戶端去接受消息,消費者
./bin/kafka-console-consumer.sh --zookeeper kafka1:2181,kafka2:2181,kafka3:2181 --from-beginning --topic test1
#然後在生產者處輸入任意內容,在消費端查看內容。5、其他命令
./bin/kafka-topics.sh --list --zookeeper xxxx:2181
#顯示創建的所有topic
./bin/kafka-topics.sh --describe --zookeeper xxxx:2181 --topic test1
#Topic:ssports PartitionCount:1 ReplicationFactor:2 Configs:
# Topic: test1 Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1
#分區爲爲1 複製因子爲2 他的 test1的分區爲0
#Replicas: 0,1 複製的爲0,16、刪除topic
修改配置文件server.properties添加如下配置:
delete.topic.enable=true
配置完重啓kafka、zookeeper。
如果不想修改配置文件可刪除topc及相關數據目錄
#刪除kafka topic
./bin/kafka-topics.sh --delete --zookeeper xxxx:2181,xxxx:2181 --topic test1
#刪除kafka相關數據目錄
rm -rf /data/kafka/log/kafka/test*
#刪除zookeeper相關路徑
rm -rf /data/kafka/zk/test*
rm -rf /data/kafka/log/zk/test*