




1 業務背景
隨着大數據的快速發展,業務場景越來越複雜,離線式的批處理框架MapReduce已經不能滿足業務,大量的場景需要實時的數據處理結果來進行分析、決策。Spark Streaming是一種分佈式的大數據實時計算框架,他提供了動態的,高吞吐量的,可容錯的流式數據處理,不僅可以實現用戶行爲分析,還能在金融、輿情分析、網絡監控等方面發揮作用。個推開發者服務——消息推送“應景推送”正是應用了Spark Streaming技術,基於大數據分析人羣屬性,同時利用LBS地理圍欄技術,實時觸發精準消息推送,實現用戶的精細化運營。此外,個推在應用Spark Streaming做實時處理kafka數據時, 採用Direct模式代替Receiver模式的手段,實現了資源優化和程序穩定性提升。
本文將從Spark Streaming獲取kafka數據的兩種模式入手,結合個推實踐, 帶你解讀Receiver和Direct模式的原理和特點,以及從Receiver模式到Direct模式的優化對比。
2 兩種模式的原理和區別
Receiver模式
1. Receiver模式下的運行架構
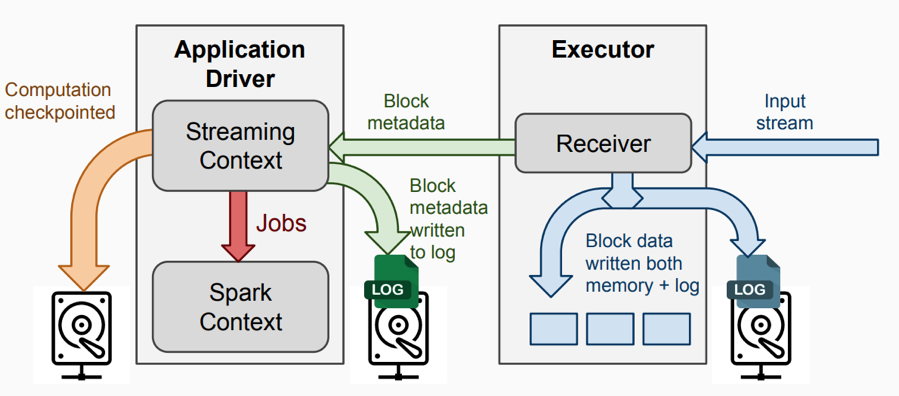
1)InputDStream: 從流數據源接收的輸入數據。
2)Receiver:負責接收數據流,並將數據寫到本地。
3)Streaming Context:代表SparkStreaming,負責Streaming層面的任務調度,生成jobs發送到Spark engine處理。
4)Spark Context: 代表Spark Core,負責批處理層面的任務調度,真正執行job的Spark engine。
2. Receiver從kafka拉取數據的過程
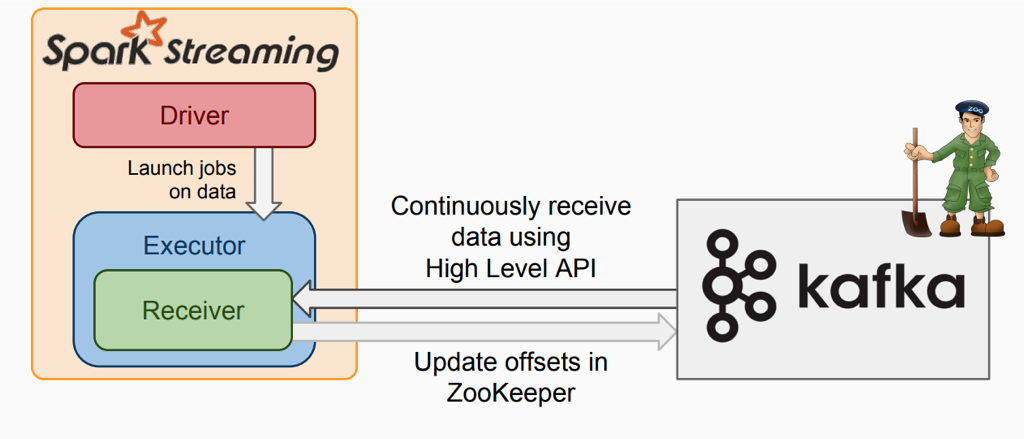
該模式下:
1)在executor上會有receiver從kafka接收數據並存儲在Spark executor中,在到了batch時間後觸發job去處理接收到的數據,1個receiver佔用1個core;
2)爲了不丟數據需要開啓WAL機制,這會將receiver接收到的數據寫一份備份到第三方系統上(如:HDFS);
3)receiver內部使用kafka High Level API去消費數據及自動更新offset。
Direct模式
1. Direct模式下的運行架構
與receiver模式類似,不同在於executor中沒有receiver組件,從kafka拉去數據的方式不同。
2. Direct從kafka拉取數據的過程
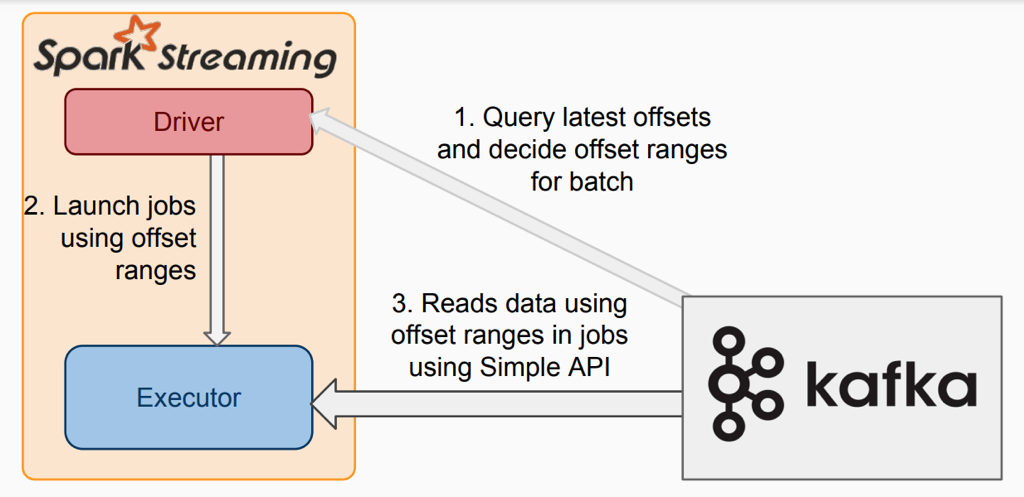
該模式下:
1)沒有receiver,無需額外的core用於不停地接收數據,而是定期查詢kafka中的每個partition的最新的offset,每個批次拉取上次處理的offset和當前查詢的offset的範圍的數據進行處理;
2)爲了不丟數據,無需將數據備份落地,而只需要手動保存offset即可;
3)內部使用kafka simple Level API去消費數據, 需要手動維護offset,kafka zk上不會自動更新offset。
Receiver與Direct模式的區別
1.前者在executor中有Receiver接受數據,並且1個Receiver佔用一個core;而後者無Receiver,所以不會暫用core;
2.前者InputDStream的分區是 num_receiver *batchInterval/blockInteral,後者的分區數是kafka topic partition的數量。Receiver模式下num_receiver的設置不合理會影響性能或造成資源浪費;如果設置太小,並行度不夠,整個鏈路上接收數據將是瓶頸;如果設置太多,則會浪費資源;
3.前者使用zookeeper來維護consumer的偏移量,而後者需要自己維護偏移量;
4.爲了保證不丟失數據,前者需要開啓WAL機制,而後者不需要,只需要在程序中成功消費完數據後再更新偏移量即可。
3 Receiver改造成Direct模式
個推使用Spark Streaming做實時處理kafka數據,先前使用的是receiver模式;
receiver有以下特點 :
1.receiver模式下,每個receiver需要單獨佔用一個core;
2.爲了保證不丟失數據,需要開啓WAL機制,使用checkpoint保存狀態;
3.當receiver接受數據速率大於處理數據速率,導致數據積壓,最終可能會導致程序掛掉。
由於以上特點,receiver模式下會造成一定的資源浪費;使用checkpoint保存狀態, 如果需要升級程序,則會導致checkpoint無法使用;第3點receiver模式下會導致程序不太穩定;並且如果設置receiver數量不合理也會造成性能瓶頸在receiver。爲了優化資源和程序穩定性,應將receiver模式改造成direct模式。
修改方式如下:
1. 修改InputDStream的創建
將receiver的:
val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
改成direct的:
val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
2. 手動維護offset
receiver模式代碼:
(receiver模式不需要手動維護offset,而是內部通過kafka consumer high level API 提交到kafka/zk保存)
kafkaStream.map { ... }.foreachRDD { rdd => // 數據處理 doCompute(rdd) }direct模式代碼:
directKafkaStream.map { ... }.foreachRDD { rdd => // 獲取當前rdd數據對應的offset val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges // 數據處理 doCompute(rdd) // 自己實現保存offset commitOffsets(offsetRanges) }4 其他優化點
1. 在receiver模式下 :
1)拆分InputDStream,增加Receiver,從而增加接收數據的並行度;
2)調整blockInterval,適當減小,增加task數量,從而增加並行度(在core的數量>task數量的情況下);
3)如果開啓了WAL機制,數據的存儲級別設置爲MOMERY_AND_DISK_SER。
2.數據序列化 使用Kryoserializationl ,相比Java serializationl 更快,序列化後的數據更小;
3.建議 使用CMS垃圾回收器 降低GC開銷;
4. 選擇高性能的算子 (mapPartitions, foreachPartitions, aggregateByKey等);
5. repartition的使用: 在streaming程序中因爲batch時間特別短,所以數據量一般較小,所以repartition的時間短,可以解決一些因爲topicpartition中數據分配不均勻導致的數據傾斜問題;
鄭州婦科醫院:http://jbk.39.net/yiyuanzaixian/sysdfkyy/
6.因爲SparkStreaming生產的job最終都是在sparkcore上運行的,所以 sparkCore的優化 也很重要;
7. BackPressure流控
1)爲什麼引入Backpressure?
當batch processing time>batchinterval 這種情況持續過長的時間,會造成數據在內存中堆積,導致Receiver所在Executor內存溢出等問題;
2)Backpressure:根據JobScheduler反饋作業的執行信息來動態調整數據接收率;
3)配置使用:
spark.streaming.backpressure.enabled含義: 是否啓用 SparkStreaming內部的backpressure機制,默認值:false ,表示禁用spark.streaming.backpressure.initialRate含義: receiver 爲第一個batch接收數據時的比率spark.streaming.receiver.maxRate含義: receiver接收數據的最大比率,如果設置值<=0, 則receiver接收數據比率不受限制spark.streaming.kafka.maxRatePerPartition含義: 從每個kafka partition中讀取數據的最大比率
8.speculation機制
spark內置speculation機制,推測job中的運行特別慢的task,將這些task kill,並重新調度這些task執行。
默認speculation機制是關閉的,通過以下配置參數開啓:
spark.speculation=true
注意 :在有些情況下,開啓speculation反而效果不好,比如:streaming程序消費多個topic時,從kafka讀取數據直接處理,沒有重新分區,這時如果多個topic的partition的數據量相差較大那麼可能會導致正常執行更大數據量的task會被認爲執行緩慢,而被中途kill掉,這種情況下可能導致batch的處理時間反而變長;可以通過repartition來解決這個問題,但是要衡量repartition的時間;而在streaming程序中因爲batch時間特別短,所以數據量一般較小,所以repartition的時間短,不像spark_batch一次處理大量數據一旦repartition則會特別久,所以最終還是要根據具體情況測試來決定。
5 總結
將Receiver模式改成Direct模式,實現了資源優化,提升了程序的穩定性,缺點是需要自己管理offset,操作相對複雜。 未來,個推將不斷探索和優化Spark Streaming技術,發揮其強大的數據處理能力,爲建設實時數倉提供保障。