




從昨晚的18:50分開始,每隔30分鐘左右進行10G流量的ddos***,實在沒招,只能使用阿里雲的高防IP來防禦。

主要的***是:

趁此機會,全面瞭解DDos***: (以下是總結內容來源:
http://www.secpulse.com/archives/37785.html?utm_source=tuicool&utm_medium=referral
http://www.ijiandao.com/safe/cto/15952.html
DDoS(Distributed Denial of Service,分佈式拒絕服務)***的主要目的是讓指定目標無法提供正常服務,甚至從互聯網上消失,是目前最強大、最難防禦的***之一。這是一個世界級的難題並沒有解決辦法只能緩解.
1、網絡層DDoS分類
SYN-FLOOD
SYN Flood是互聯網上最經典的DDoS***方式之一,最早出現於1999年左右,雅虎是當時最著名的受害者。SYN Flood***利用了TCP三次握手的缺陷,能夠以較小代價使目標服務器無法響應,且難以追查。
利用TCP建立連接時3次握手的“漏洞”,通過原始套接字發送源地址虛假的SYN報文,使目標主機永遠無法完成3次握手,佔滿了系統的協議棧隊列,資源得不到釋放,進而拒絕服務,是互聯網中最主要的DDOS***形式之一.標準的TCP三次握手過程如下:
1、客戶端發送一個包含SYN標誌的TCP報文,SYN即同步(Synchronize),同步報文會指明客戶端使用的端口以及TCP連接的初始序號;
2、服務器在收到客戶端的SYN報文後,將返回一個SYN+ACK(即確認Acknowledgement)的報文,表示客戶端的請求被接受,同時TCP初始序號自動加1;
3、客戶端也返回一個確認報文ACK給服務器端,同樣TCP序列號被加1。
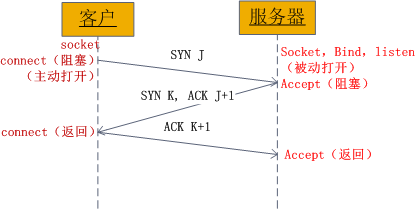
經過這三步,TCP連接就建立完成。TCP協議爲了實現可靠傳輸,在三次握手的過程中設置了一些異常處理機制。第三步中如果服務器沒有收到客戶端的最終ACK確認報文,會一直處於SYN_RECV狀態,將客戶端IP加入等待列表,並重發第二步的SYN+ACK報文。重發一般進行3-5次,大約間隔30秒左右輪詢一次等待列表重試所有客戶端。另一方面,服務器在自己發出了SYN+ACK報文後,會預分配資源爲即將建立的TCP連接儲存信息做準備,這個資源在等待重試期間一直保留。更爲重要的是,服務器資源有限,可以維護的SYN_RECV狀態超過極限後就不再接受新的SYN報文,也就是拒絕新的TCP連接建立。
SYN Flood正是利用了上文中TCP協議的設定,達到***的目的。***者僞裝大量的IP地址給服務器發送SYN報文,由於僞造的IP地址幾乎不可能存在,也就幾乎沒有設備會給服務器返回任何應答了。因此,服務器將會維持一個龐大的等待列表,不停地重試發送SYN+ACK報文,同時佔用着大量的資源無法釋放。更爲關鍵的是,被***服務器的SYN_RECV隊列被惡意的數據包占滿,不再接受新的SYN請求,合法用戶無法完成三次握手建立起TCP連接。也就是說,這個服務器被SYN Flood拒絕服務了。
網上有一些加固的方法,例如調整內核參數的方法,可以減少等待及重試,加速資源釋放,在小流量syn-flood的情況下可以緩解,但流量稍大時完全不抵用。防禦syn-flood的常見方法有:syn proxy、syn cookies、首包(第一次請求的syn包)丟棄等。
AKC-FLOOD
對於虛假的ACK包,目標設備會直接回復RST包丟棄連接,所以傷害值遠不如syn-flood。DDOS的一種原始方式。
UDP-FLOOD
使用原始套接字僞造大量虛假源地址的UDP包,目前以DNS協議爲主。
ICMP-FLOOD
Ping洪水,比較古老的方式。
2、應用層DDoS***
DNS 請求 FLOOD
作爲互聯網最基礎、最核心的服務,DNS自然也是DDoS***的重要目標之一。打垮DNS服務能夠間接打垮一家公司的全部業務,或者打垮一個地區的網絡服務。前些時候風頭正盛的***組織anonymous也曾經宣佈要***全球互聯網的13臺根DNS服務器,不過最終沒有得手。
UDP***是最容易發起海量流量的***手段,而且源IP隨機僞造難以追查。但過濾比較容易,因爲大多數IP並不提供UDP服務,直接丟棄UDP流量即可。所以現在純粹的UDP流量***比較少見了,取而代之的是UDP協議承載的DNS Query Flood***。簡單地說,越上層協議上發動的DDoS***越難以防禦,因爲協議越上層,與業務關聯越大,防禦系統面臨的情況越複雜。
DNS Flood就是***者操縱大量傀儡機器,對目標發起海量的域名查詢請求。爲了防止基於ACL的過濾,必須提高數據包的隨機性。常用的做法是UDP層隨機僞造源IP地址、隨機僞造源端口等參數。在DNS協議層,隨機僞造查詢ID以及待解析域名。隨機僞造待解析域名除了防止過濾外,還可以降低命中DNS緩存的可能性,儘可能多地消耗DNS服務器的CPU資源。
僞造源地址的海量DNS請求,用於是淹沒目標的DNS服務器。對於***特定企業權威DNS的場景,可以將源地址設置爲各大ISP DNS服務器的ip地址以突破白名單限制,將查詢的內容改爲針對目標企業的域名做隨機化處理,當查詢無法命中緩存時,服務器負載會進一步增大。
DNS不只在UDP-53提供服務,同樣在TCP協議提供服務,所以防禦的一種思路就是將UDP的查詢強制轉爲TCP,要求溯源,如果是假的源地址,就不再回應。對於企業自有權威DNS服務器而言,正常請求多來自於ISP的域名遞歸解析,所以將白名單設置爲ISP的DNS server列表。對於源地址僞造成ISP DNS的請求,可以通過TTL值進一步判斷。
Http Flood (cc)
上文描述的SYN Flood、DNS Query Flood在現階段已經能做到有效防禦了,真正令各大廠商以及互聯網企業頭疼的是HTTP Flood***。它的巨大危害性主要表現在三個方面:發起方便、過濾困難、影響深遠。
SYN Flood和DNS Query Flood都需要***者以root權限控制大批量的傀儡機。收集大量root權限的傀儡機很花費時間和精力,而且在***過程中傀儡機會由於流量異常被管理員發現,***者的資源快速損耗而補充緩慢,導致***強度明顯降低而且不可長期持續。HTTP Flood***則不同,***者並不需要控制大批的傀儡機,取而代之的是通過端口掃描程序在互聯網上尋找匿名的HTTP代理或者SOCKS代理,***者通過匿名代理對***目標發起HTTP請求。匿名代理是一種比較豐富的資源,花幾天時間獲取代理並不是難事,因此***容易發起而且可以長期高強度的持續。
另一方面,HTTP Flood***在HTTP層發起,極力模仿正常用戶的網頁請求行爲,與網站業務緊密相關,安全廠商很難提供一套通用的且不影響用戶體驗的方案。在一個地方工作得很好的規則,換一個場景可能帶來大量的誤殺。
最後,HTTP Flood***會引起嚴重的連鎖反應,不僅僅是直接導致被***的Web前端響應緩慢,還間接***到後端的Java等業務層邏輯以及更後端的數據庫服務,增大它們的壓力,甚至對日誌存儲服務器都帶來影響。
有意思的是,HTTP Flood還有個頗有歷史淵源的暱稱叫做CC***。CC是Challenge Collapsar的縮寫,而Collapsar是國內一家著名安全公司的DDoS防禦設備。從目前的情況來看,不僅僅是Collapsar,所有的硬件防禦設備都還在被挑戰着,風險並未解除。
互聯網的架構追求擴展性本質上是爲了提高併發能力,各種SQL性能優化措施:消除慢查詢、分表分庫、索引、優化數據結構、限制搜索頻率等本質都是爲了解決資源消耗,而CC大有反其道而行之的意味,佔滿服務器併發連接數,儘可能使請求避開緩存而直接讀數據庫,讀數據庫要找最消耗資源的查詢,最好無法利用索引,每個查詢都全表掃描,這樣就能用最小的***資源起到最大的拒絕服務效果。
互聯網產品和服務依靠數據分析來驅動改進和持續運營,所以除了前端的APP、中間件和數據庫這類OLTP系統,後面還有OLAP,從日誌收集,存儲到數據處理和分析的大數據平臺,當CC***發生時,不僅OLTP的部分受到了影響,實際上CC會產生大量日誌,直接會對後面的OLAP產生影響,影響包括兩個層面,一個當日的數據統計完全是錯誤的。第二個層面因CC期間訪問日誌劇增也會加大後端數據處理的負擔。
CC是目前應用層***的主要手段之一,在防禦上有一些方法,但不能完美解決這個問題。
慢速連接***
針對http協議,以知名的slowloris***爲起源:先建立http連接,設置一個較大的content-length,每次只發送很少的字節,讓服務器一直以爲http頭部沒有傳輸完成,這樣的連接一多很快就會出現連接耗盡。慢速連接***,最具代表性的是rsnake發明的Slowloris。
HTTP協議規定,HTTP Request以\r\n\r\n結尾表示客戶端發送結束,服務端開始處理。那麼,如果永遠不發送\r\n\r\n會如何?Slowloris就是利用這一點來做DDoS***的。***者在HTTP請求頭中將Connection設置爲Keep-Alive,要求Web Server保持TCP連接不要斷開,隨後緩慢地每隔幾分鐘發送一個key-value格式的數據到服務端,如a:b\r\n,導致服務端認爲HTTP頭部沒有接收完成而一直等待。如果***者使用多線程或者傀儡機來做同樣的操作,服務器的Web容器很快就被***者佔滿了TCP連接而不再接受新的請求。
目前出現了一些變種,http慢速的post請求和慢速的read請求都是基於相同的原理,比如POST方法向Web Server提交數據、填充一大大Content-Length但緩慢的一個字節一個字節的POST真正數據內容等等。
DOS***
有些服務器程序存在bug、安全漏洞,或架構性缺陷,***者可以通過構造的畸形請求發送給服務器,服務器因不能正確處理惡意請求而陷入僵死狀態,導致拒絕服務。例如某些版本的app服務器程序存在緩衝區溢出,漏洞可以觸發但無法得到shell,***者可以改變程序執行流程使其跳轉到空指針或無法處理的地址,用戶態的錯誤會導致進程掛起,如果錯誤不能被內核回收則可能使系統當掉。
這類問題效果也表現爲拒絕服務,但本質上屬於漏洞,可以通過patch程序的最新版本解決,筆者認爲不屬於DDOS的範疇。
3、***方式
混合型方式
以上介紹了幾種基礎的***手段,其中任意一種都可以用來***網絡,甚至擊垮阿里、百度、騰訊這種巨型網站。但這些並不是全部,不同層次的***者能夠發起完全不同的DDoS***,運用之妙,存乎一心。
在實際大流量的***中,通常並不是以上述一種數據類型來***,往往是混雜了TCP和UDP流量,網絡層和應用層***同時進行。
高級***者從來不會使用單一的手段進行***,而是根據目標環境靈活組合。普通的SYN Flood容易被流量清洗設備通過反向探測、SYN Cookie等技術手段過濾掉,但如果在SYN Flood中混入SYN+ACK數據包,使每一個僞造的SYN數據包都有一個與之對應的僞造的客戶端確認報文,這裏的對應是指源IP地址、源端口、目的IP、目的端口、TCP窗口大小、TTL等都符合同一個主機同一個TCP Flow的特徵,流量清洗設備的反向探測和SYN Cookie性能壓力將會顯著增大。其實SYN數據報文配合其他各種標誌位,都有特殊的***效果,這裏不一一介紹。對DNS Query Flood而言,也有獨特的技巧。
首先,DNS可以分爲普通DNS和授權域DNS,***普通DNS,IP地址需要隨機僞造,並且指明服務器要求做遞歸解析;但***授權域DNS,僞造的源IP地址則不應該是純隨機的,而應該是事先收集的全球各地ISP的DNS地址,這樣才能達到最大***效果,使流量清洗設備處於添加IP黑名單還是不添加IP黑名單的尷尬處境。添加會導致大量誤殺,不添加黑名單則每個報文都需要反向探測從而加大性能壓力。
另一方面,前面提到,爲了加大清洗設備的壓力不命中緩存而需要隨機化請求的域名,但需要注意的是,待解析域名必須在僞造中帶有一定的規律性,比如說只僞造域名的某一部分而固化一部分,用來突破清洗設備設置的白名單。道理很簡單,騰訊的服務器可以只解析騰訊的域名,完全隨機的域名可能會直接被丟棄,需要固化。但如果完全固定,也很容易直接被丟棄,因此又需要僞造一部分。
其次,對DNS的***不應該只着重於UDP端口,根據DNS協議,TCP端口也是標準服務。在***時,可以UDP和TCP***同時進行。
HTTP Flood的着重點,在於突破前端的cache,通過HTTP頭中的字段設置直接到達Web Server本身。另外,HTTP Flood對目標的選取也非常關鍵,一般的***者會選擇搜索之類需要做大量數據查詢的頁面作爲***目標,這是非常正確的,可以消耗服務器儘可能多的資源。但這種***容易被清洗設備通過人機識別的方式識別出來,那麼如何解決這個問題?很簡單,儘量選擇正常用戶也通過APP訪問的頁面,一般來說就是各種Web API。正常用戶和惡意流量都是來源於APP,人機差別很小,基本融爲一體難以區分。
之類的慢速***,是通過巧妙的手段佔住連接不釋放達到***的目的,但這也是雙刃劍,每一個TCP連接既存在於服務端也存在於自身,自身也需要消耗資源維持TCP狀態,因此連接不能保持太多。如果可以解決這一點,***性會得到極大增強,也就是說Slowloris可以通過stateless的方式發動***,在客戶端通過嗅探捕獲TCP的序列號和確認維護TCP連接,系統內核無需關注TCP的各種狀態變遷,一臺筆記本即可產生多達65535個TCP連接。
前面描述的,都是技術層面的***增強。在人的方面,還可以有一些別的手段。如果SYN Flood發出大量數據包正面強攻,再輔之以Slowloris慢速連接,多少人能夠發現其中的祕密?即使服務器宕機了也許還只發現了SYN***想去加強TCP層清洗而忽視了應用層的行爲。種種***都可以互相配合,達到最大的效果。***時間的選擇,也是一大關鍵,比如說選擇維護人員吃午飯時、維護人員下班堵在路上或者在地鐵裏無線上網卡都沒有信號時、目標企業在舉行大規模活動流量飆升時等。
反射型
2004年時DRDOS第一次披露,通過將SYN包的源地址設置爲目標地址,然後向大量的

真實TCP服務器發送TCP的SYN包,而這些收到SYN包的TCP server爲了完成3次握手把SYN|ACK包“應答”給目標地址,完成了一次“反射”***,***者隱藏了自身,但有個問題是***者製造的流量和目標收到的***流量是1:1,且SYN|ACK包到達目標後馬上被回以RST包,整個***的投資回報率不高。
反射型***的本質是利用“質詢-應答”式協議,將質詢包的源地址通過原始套接字僞造設置爲目標地址,則應答的“回包”都被髮送至目標,如果回包體積比較大或協議支持遞歸效果,***流量會被放大,成爲一種高性價比的流量型***。
反射型***利用的協議目前包括NTP、Chargen、SSDP、DNS、RPC portmap等等。
流量放大型
以上面提到的DRDOS中常見的SSDP協議爲例,***者將Search type設置爲ALL,搜索所有可用的設備和服務,這種遞歸效果產生的放大倍數是非常大的,***者只需要以較小的僞造源地址的查詢流量就可以製造出幾十甚至上百倍的應答流量發送至目標。
脈衝型
很多***持續的時間非常短,通常5分鐘以內,流量圖上表現爲突刺狀的脈衝。

之所以這樣的***流行是因爲“打-打-停-停”的效果最好,剛觸發防禦閾值,防禦機制開始生效***就停了,周而復始。蚊子不叮你,卻在耳邊飛,剛開燈想打它就跑沒影了,當你剛關燈它又來了,你就沒法睡覺。
自動化的防禦機制大部分都是依靠設置閾值來觸發。儘管很多廠商宣稱自己的防禦措施都是秒級響應,但實際上比較難。
網絡層的***檢測通常分爲逐流和逐包,前者根據netflow以一定的抽樣比例(例如1000:1)檢測網絡是否存在ddos***,這種方式因爲是抽樣比例,所以精確度較低,做不到秒級響應。第二種逐包檢測,檢測精度和響應時間較短,但成本比較高,一般廠商都不會無視TCO全部部署這類方案。即便是逐包檢測,其防禦清洗策略的啓動也依賴於閾值,加上清洗設備一般情況下不會串聯部署,觸發清洗後需要引流,因此大部分場景可以做秒級檢測但做不到秒級防禦,近源清洗尚且如此,雲清洗的觸發和轉換過程就更慢了。所以利用防禦規則的生效灰度期,在觸發防禦前完成***會有不錯的效果,在結果上就表現爲脈衝。
(我們受到的***就是這樣。)
脈衝型
隨着DDOS***技術的發展,又出現了一種新型的***方式link-flooding attack,這種方式不直接***目標而是以堵塞目標網絡的上一級鏈路爲目的。對於使用了ip anycast的企業網絡來說,常規的DDOS***流量會被“分攤”到不同地址的基礎設施,這樣能有效緩解大流量***,所以***者發明了一種新方法,***至目標網絡traceroute的倒數第二跳,即上聯路由,致使鏈路擁塞。國內ISP目前未開放anycast,所以這種***方式的必要性有待觀望。

對一級ISP和IXP的***都可以使鏈路擁塞。