故障前提
ElasticSearch 版本:5.2
集羣節點數:5
索引主分片數:5
索引分片副本數:1
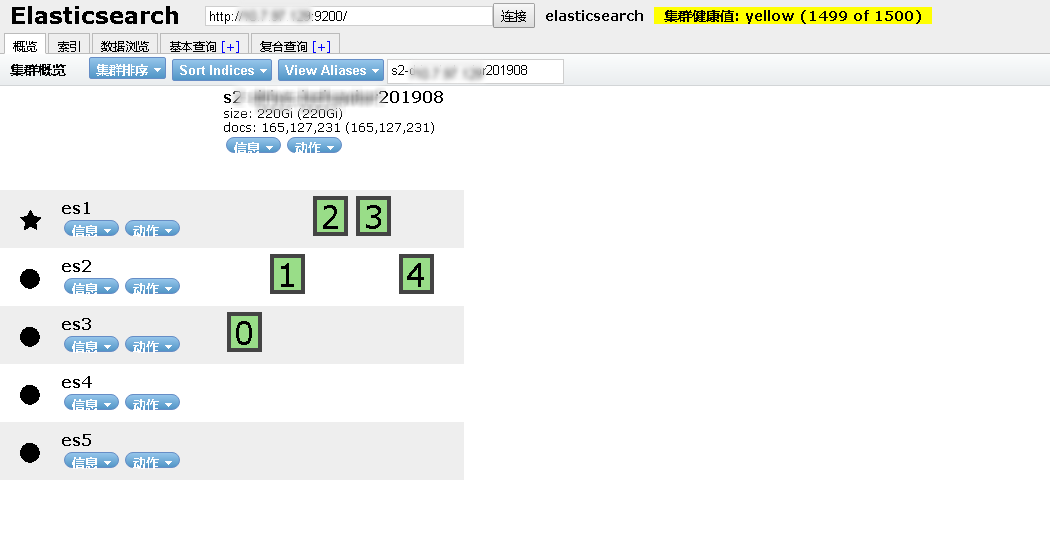
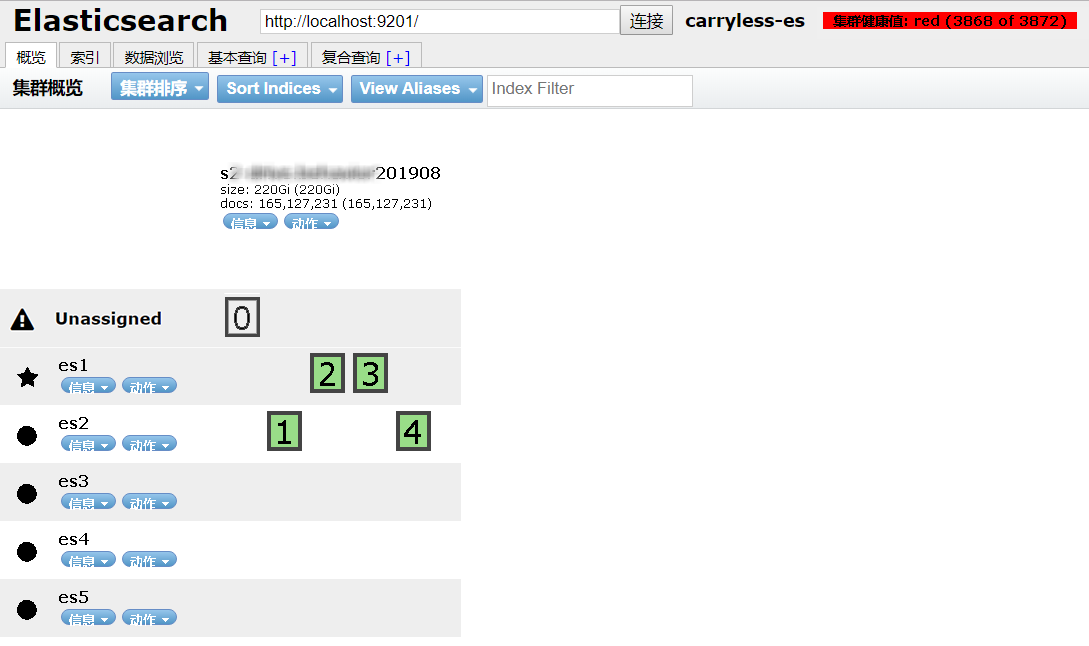
線上環境ES存儲的數據量很大,當天由於存儲故障,導致一時間 5個節點的 ES 集羣,同時有兩個節點離線,一個節點磁盤只讀(機房小哥不會處理,無奈只有清空數據重新安裝系統),一個節點重啓後,ES集羣報個別索引分片分配異常,ES索引出於保證數據一致性的考慮,並沒有把重啓節點上的副本分片提升爲主分片,所以該索引處於 不可寫入 狀態(索引分片 red)。
處理方案
在網上找了找類似的處理方案,分爲以下幾個。
-
利用
_rerouteAPI 進行分片路由。pass: 分片都啓不來,按照網上的操作執行失敗。
-
利用
_reindexAPI 進行現有數據重新複製到新索引,然後把舊索引刪除,新索引建立別名爲老索引名稱。優點:因爲如圖分片 0 出於只讀狀態,所以數據是可以訪問的,所以利用
_reindex可以把副本分片的數據進行復制遷移到新索引,最大保證數據的安全性。
缺點:因爲涉及的數據量比較大,而且_reindex效率很低,220G 的索引數據,大概要3-4天的時間才能寫入完畢。線上環境等不了這麼久。
也找了許多提升_reindex效率的方法,設置新索引的副本數爲 0,禁用刷新 等等。提升效果都很小。 - 線上環境能夠接受該索引部分數據的丟失,但求儘快恢復服務。
找了下官方文檔,找到了如下方法。
[root@***es4 ~]# curl 'http://localhost:9201/s2*******r201908/_shard_stores?pretty'
{
"indices" : {
"s2********201908" : {
"shards" : {
"0" : {
"stores" : [
{
"kgEDY2A4TBKK6lFzqsurnQ" : {
"name" : "es3",
"ephemeral_id" : "72HkjNj5S-qyl6gmVkbWeg",
"transport_address" : "10.2.97.130:9300",
"attributes" : { }
},
"allocation_id" : "B4G1nHTgQieomyy-KME1ug",
"allocation" : "unused"
},
{
"d3WYyXhBQvqYbZieXzfCNw" : {
"name" : "es5",
"ephemeral_id" : "deBE6DjyRJ-kXdj0XU7FzQ",
"transport_address" : "10.2.101.116:9300",
"attributes" : { }
},
"allocation_id" : "svMhSywPSROQa7MnbvKB-g",
"allocation" : "unused",
"store_exception" : {
"type" : "corrupt_index_exception",
"reason" : "failed engine (reason: [corrupt file (source: [index])]) (resource=preexisting_corruption)",
"caused_by" : {
"type" : "i_o_exception",
"reason" : "failed engine (reason: [corrupt file (source: [index])])",
"caused_by" : {
"type" : "corrupt_index_exception",
"reason" : "checksum failed (hardware problem?) : expected=24fb23d3 actual=66004bad (resource=BufferedChecksumIndexInput(MMapIndexInput(path=\"/var/lib/elasticsearch/nodes/0/indices/oC_7CtFfS2-pa3OoBDAlDA/0/index/_1fjsf.cfs\") [slice=_1fjsf_Lucene50_0.pos]))"
}
}
}
}
]
}
}
}
}
}利用 _shard_stores 接口,查看故障索引的分片異常原因。
(es5 節點上,我調用接口設置了副本數從1 變爲 0,所以該只讀索引還保存有原有分片 0 的副本分片節點信息,可忽略)
我們看到該索引的 0 主分片(故障主分片)以前是存在於 es3 節點上的。ES 由於數據安全性保證,在兩個節點都有離線的情況下,鎖住了 0 主分片的寫入,導致索引也出於只讀狀態。
[root@*******es4 ~]# curl -XPOST 'http://localhost:9201/_cluster/reroute?master_timeout=5m&pretty' -d '
{
"commands": [
{
"allocate_stale_primary": {
"index": "s2-********201908",
"shard": 0,
"node": "es3",
"accept_data_loss": true
}
}
]
}'我們可以手動調用集羣的 reroute 接口,在接受部分數據丟失的情況下,我們可以把 es3 節點上的原有副本,強制提升爲索引的主分片。
官方文檔 說明。
此外,/_cluster/reroute 接口還能夠接受手動分配一個空的主分片到已有索引分配之中。謹慎使用
[root@*******es4 ~]# curl -XPOST 'http://localhost:9201/_cluster/reroute?master_timeout=5m&pretty' -d '
{
"commands": [
{
"allocate_empty_primary": {
"index": "s2-********201908",
"shard": 0,
"node": "es3",
"accept_data_loss": true
}
}
]
}'這種更殘暴,直接把分片數據清空,強制拉上線。 但是這也不失爲一種處理方法。
最終,該索引恢復正常。