




掌握高併發、高可用架構
第三章 分佈式
本章介紹分佈式架構的底層技術。主要說明面試過程中可能被問到的技術點。
第二節 Zookeeper
Zookeeper 分佈式
1. Zookeeper是什麼
Zookeeper是一個分佈式的、開源的分佈式應用程序協調服務。它是集羣的管理者,監視着集羣中各個節點的狀態,並根據節點提交的反饋進行下一步合理的操作。
對於客戶端的讀操作,可以被集羣中任意一臺機器處理。如果讀請求在節點上註冊了監聽器,這個監聽器也是由所連接的機器來執行
對於客戶端的寫操作,這些請求會同時發給其他的zookeeper機器並達成一致後,請求才會返回成功
因此,隨着集羣機器的增多,讀請求的吞吐會提高,而寫請求的吞吐會下降
有序性是Zookeeper的另一個特點,所有的更新操作都是全局有序的;每個更新都有唯一的時間戳,稱爲zxid(Zookeeper Transaction Id);而讀請求只會相對於更新有序,也就是讀請求的返回結果中會帶有這個zookeeper的最新zxid
2. Zookeeper提供了什麼
文件系統 和 通知機制
3. Zookeeper文件系統
Zookeeper提供了一個多層級的節點命名空間(節點稱爲znode)
與文件系統不同的是,它的每個節點都可以設置關聯數據,而文件系統只有文件節點可以存放數據而目錄節點不行
Zookeeper爲了保證高吞吐和低延遲,在內存中維護了這個樹狀的目錄結構,所以它不能存放大量的數據,每個節點的存放數據上限是1M
4. 四種類型的znode
PERSISTENT,持久化目錄節點:客戶端與Zookeeper斷開連接後,該節點依舊存在PERSISTENT_SEQUENTIAL,持久化順序編號目錄節點:客戶端與Zookeeper斷開連接後,該節點依舊存在,只是Zookeeper給該節點名稱進行順序編號EPHEMERAL,臨時目錄節點:客戶端與Zookeeper斷開連接後,該節點被刪除EPHEMERAL_SEQUENTIAL,臨時順序編號目錄節點:客戶端與Zookeeper斷開連接後,該節點被刪除,只是Zookeeper給該節點名稱進行順序編號
5. Zookeeper通知機制
客戶端註冊監聽它關心的目錄節點,會對該znode建立一個watcher事件,當該znode發生變化(數據刪除、被刪除、子目錄節點增加刪除等)時,Zookeeper會通知客戶端
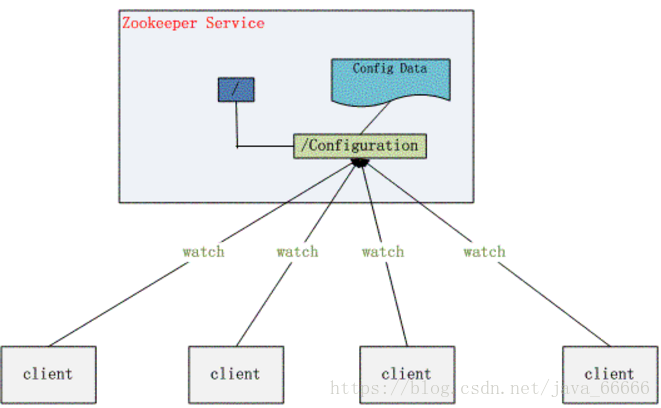
6. Zookeeper可以做什麼
- 命名服務(利用文件系統的功能):
命名服務是指通過指定的名字來獲取資源或服務的地址,即利用Zookeeper創建一個全局的路徑,也就是唯一的路徑,這個路徑可以作爲一個名字,指向集羣中的機器、提供服務的地址、一個遠程對象等
- 配置管理(利用文件系統、通知機制):
程序分佈式的部署在不同的機器上,將程序的配置信息放在zookeeper的znode下,當配置發生變化時,也就是znode發生變化時,利用watcher通知各個客戶端,從而更改配置
- 集羣管理(文件系統、通知機制):
所謂集羣管理無非兩點,是否有機器退出或加入、選舉master
第一點,所有機器約定在父目錄下創建臨時目錄節點,然後監聽父目錄節點的子節點變化信息;如果有機器掛了,該機器就會與Zookeeper斷開連接,其創建的臨時目錄就會刪除,此時就會通知所有機器,有個兄弟機器掛了;同理,機器加入也是一樣
第二點,所有機器創建臨時順序編號目錄節點,每次都選取編號最小的機器作爲master
- 分佈式鎖(文件系統、通知機制):
有了Zookeeper的一致性文件系統,鎖變得簡單。鎖服務可以分爲兩類:保持獨佔,控制時序
對於保持獨佔,我們將znode看作一把鎖,通過createznode的方式來實現;所有客戶端都去創建/distribute_lock節點,最終成功創建的那個客戶端也就獲取了這把鎖,用完刪掉/distribute_lock節點,即可釋放鎖
對於控制時序,/distribute_lock已經預先存在,所有客戶端在它下面創建臨時順序編號目錄節點,和選舉master一樣,編號最小的獲得鎖,用完刪除自己的臨時順序編號目錄節點
- 隊列管理(文件系統、通知機制):
- 同步隊列,只有隊列成員都聚齊時纔可用,否則一直等待:在約定目錄下創建臨時目錄節點,查看監聽節點的數量是否是我們要求的數量
- 隊列按照FIFO方式進行入隊和出隊操作:和分佈式鎖的控制時序的基本原理一致,在特定目錄下創建持久順序編號目錄節點,創建成功則Watcher通知等待的隊列,刪除最小號的節點用於消費
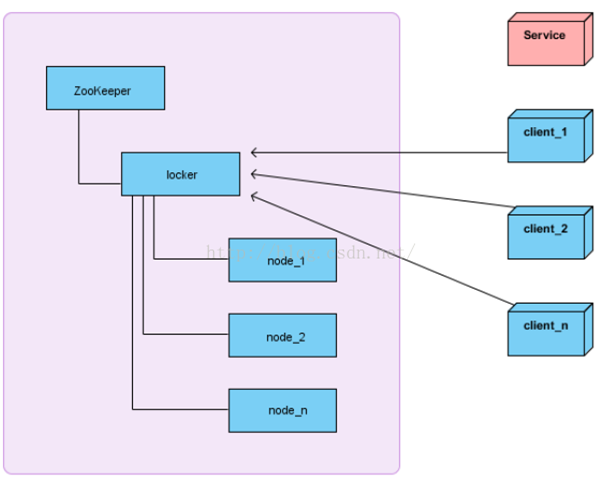
7. 獲取分佈式鎖的過程
在分佈式鎖的場景下,會提前在Zookeeper中創建一個持久節點ParentLocker(名字叫什麼都可以)
當客戶端要獲取鎖時,需要在ParentLocker下創建一個臨時順序編號節點Locker-n,首先,查找ParentLocker下的所有臨時子節點並排序,並且判斷自己創建的Locker-n是不是順序編號最小的,如果是,則臨時節點Locker-n創建成功,也就是獲取鎖成功;如果不是最小的,此時找到排序僅比自己靠前的節點,向其註冊監聽Watcher,監聽其是否存在(exist),也就是該客戶端獲取鎖失敗,進入等待;當前一個節點被刪除時,客戶端會收到通知,然後再次判斷自己是不是最小的,如果是則獲取鎖成功,如果不是,則再重複以上步驟

8. Zookeeper的工作原理
Zookeeper的核心是原子廣播,保證了各個Server之間的同步;實現這個機制的協議叫做Zab協議。Zab協議有兩種模式,恢復模式(選主)和廣播模式(同步)。當服務啓動或者領導者崩潰後,Zab進入恢復模式;當選舉了新的領導者,並且大多數Server和leader的狀態同步完成之後,恢復模式就結束了。狀態同步保證了leader和server之間有相同的系統狀態
9. Zookeeper如何保證事務的一致性
採用遞增的事務ID:zxid來標識,所有的proposal(提議)都會加上zxid。zxid是64位的數字,高32位是epoch,用來標識leader是否發生變化,如果是新選舉的leader,則epoch會遞增;低32位是遞增計數的。當有新的proposal提出時,首先向其他server發出事務執行請求,如果有超過半數的機器都能執行且能夠執行成功,然後纔會開始執行
10. Zookeeper的Server工作狀態
- LOOKING,當前server不知道leader是誰,正在搜索
- LEADING,當前server爲leader
- FOLLOWING,普通server,與leader進行同步
11. Zookeeper是如何選舉leader的
當leader崩潰或失去大多數follower,這時會進入恢復模式。選舉算法有兩種:一種是基於basic paxos實現的,一種是基於fast paxos實現的,默認是fast paxos。
-
basic paxos算法
a) 每個Server上的選舉線程由當前Server發起選舉的線程擔任,主要職責是對各個投票結果進行統計,選舉 出新的leader
b) 選舉線程向所有Server發起一次詢問(包括自己)
c) 選舉線程收到回覆後,驗證是否是自己發出的詢問(驗證zxid是否一致),然後獲取對方的myid,將之存儲到當前詢問的對象列表中,最後獲取對方提議的leader相關信息(myid,zxid),存儲到當次選舉的投票記錄中
d) 收到所有的Server回覆後,計算出zxid最大的Server,然後統計它的票數,如果它獲得了n/2+1的Server票數,則設置爲新的leader。否則,重新再次選舉
通過該選舉流程可以得出,要使leader獲得多數Server的支持,Server的總數必須是奇數2n+1,且存活的Server數目不得少於n+1
-
fast paxos算法
在選舉時,首先向所有Server提議自己要成爲leader,當其他Server收到提議後,會進行PK(zxid大myid大的獲勝),並回復同意還是拒絕,重複這個流程,就會選擇出一個新的leader

12. 同步流程
選完leader後,進入同步流程
- leader等待server連接
- follower連接leader,將自己最大的zxid發送給leader
- leader根據follower的zxid判斷同步點
- 完成同步後通知follower已成爲uptodate狀態
- follower收到uptodate通知後,就可以接收客戶端的請求了
13. Zookeeper的負載均衡和NGINX的負載均衡
zk的負載均衡可以調控,nginx只能調權重,其他的都要自己寫插件,但是nginx的吞吐量比zk大得多
14. watch機制
一個watch事件是一個一次性的觸發器,當被設置了watch的數據發生了變化時,服務器會將這個變化發送給設置了watch的客戶端
- 數據發生改變時,一個watch event會被髮送給客戶端,但是隻會發送一次
- watch event從server發送到client是異步的,只保證數據的最終一致性
- getData()、exists()設置數據監控,getChildren()設置子節點監控
- 註冊watcher:getData、exists、getChildren
- 觸發watcher:create、delete、setData
- setData()成功的話會觸發當前znode的數據監控;create()成功的話會觸發當前znode的數據監控,以及父節點的子節點監控;delete()成功的話會觸發當前znode的數據監控和子節點監控(因爲子節點也發生了變化),以及其父節點的子節點監控
- 當客戶端與服務器斷開連接後,是無法收到watch事件的,而當客戶端重新連接後,如果有需要的話,之前註冊的watch會被重新註冊的
- Watch是輕量級的,其實就是本地的Callback(客戶端創建連接時,
public Zookeeper(String connStr, int sessionTimeout, Watcher watcher)),服務器端只是存儲了是否設置了watch的布爾變量