




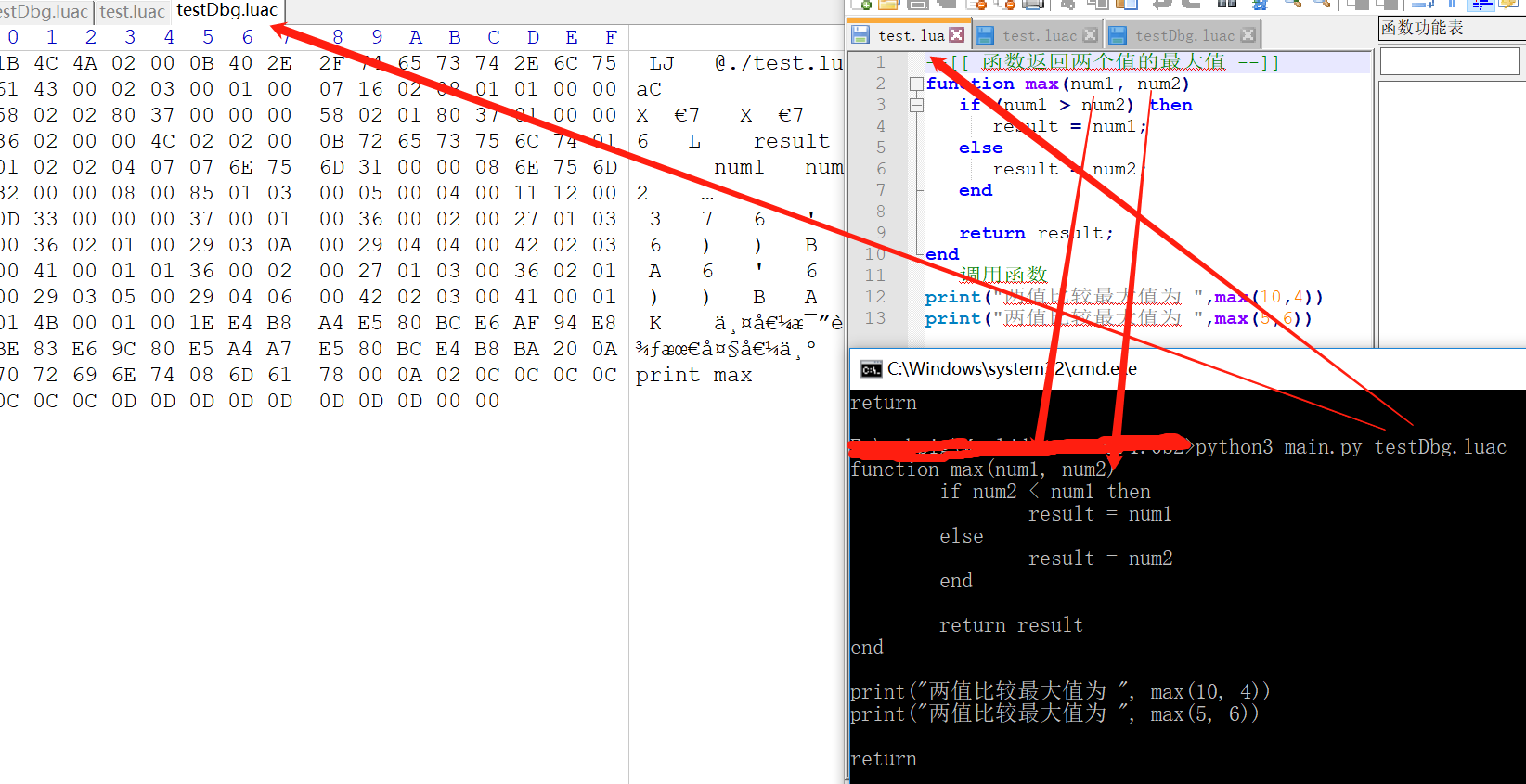
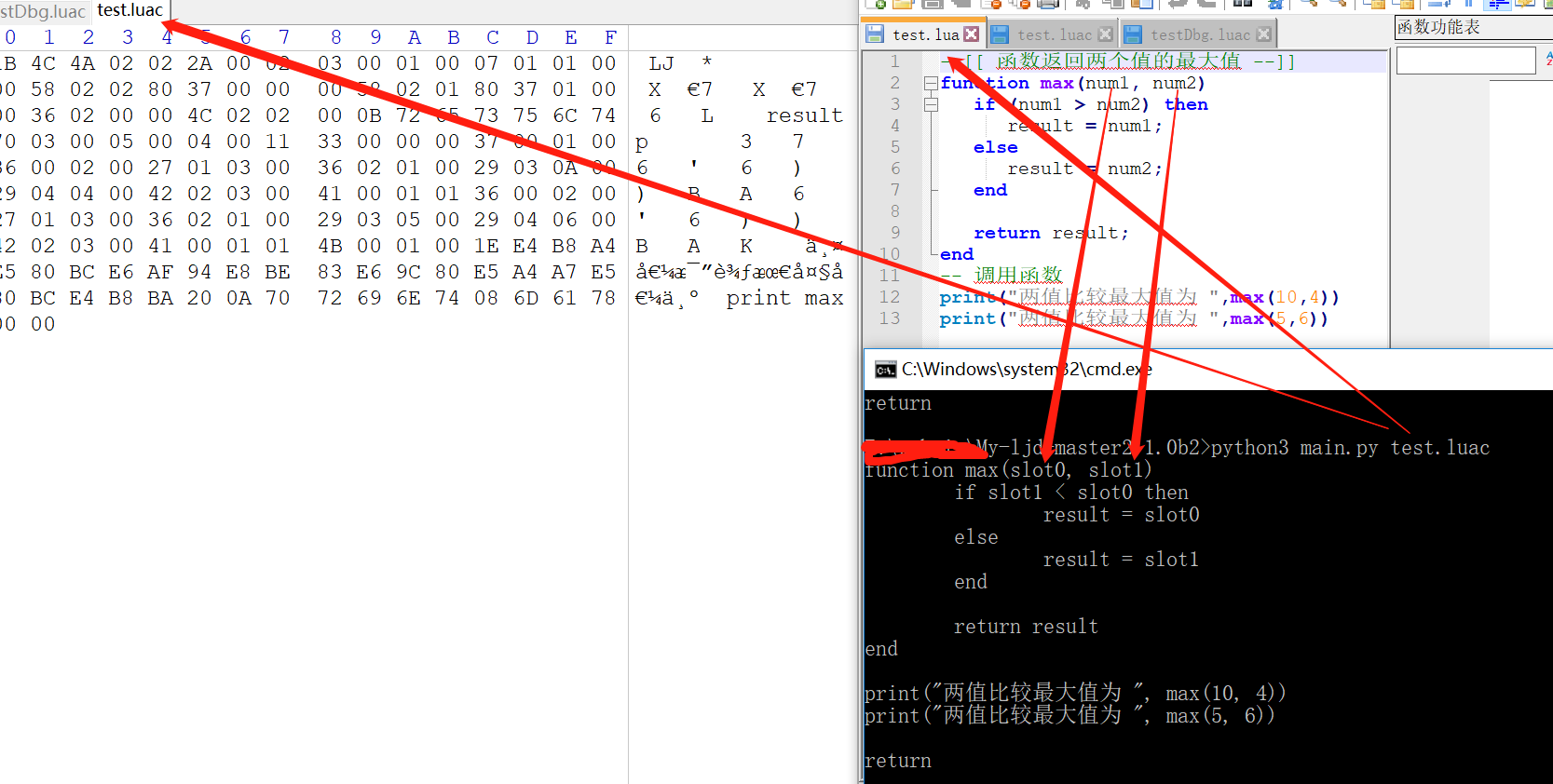
當用LuaJit編譯Lua源碼時,編譯字節碼時如果加-g選項,即字節碼包含調試信息,反編譯時幾乎可以完全還原的,不加-g選項,除本地變量信息不能還原,其它可以還原。
本文所指luajit,皆指luajit2.1.0-beta2版本。
一、背景
逆向apk時,得到luajit字節碼文件,將反編譯luajit的過程記錄如下。
本文主要分析ljd反編譯工具源碼(https://github.com/NightNord/ljd),並參照feicong的luajit字節碼分析一文(https://github.com/feicong/lua_re/blob/master/lua/lua_re3.md),製作Luajit字節碼文件格式結構圖以直觀反映luajit字節碼文件格式,並對ljd中存在的bug進行修正,說明使用過程中遇到的問題。
二、反編譯luajit字節碼前期準備
蒐集資料,找到兩種解決方案。
方案一
將luajit字節碼文件用luajit.exe(luajit -bl luajit-byte-path)反編成操作碼文件,然後再將操作碼文件解析成可讀文件。
工具地址:https://github.com/bobsayshilol/luajit-decomp
用autoit編寫,下載下來的有打包好的exe文件,簡單測試的話可以按如下操作:
1.下載編譯字節碼文件對應版本的luajit,可以自己編譯,編譯好後,將luajit.exe及對應的dll、lib等文件及源碼目錄下的jit文件夾一同拷貝進luajit-decomp目錄。
2.將需要測試的luajit字節碼文件拷貝至luajit-decomp目錄,並重命名爲test.lua
3.雙擊運行,會生成out.lua文件。
反編譯效果如下圖:
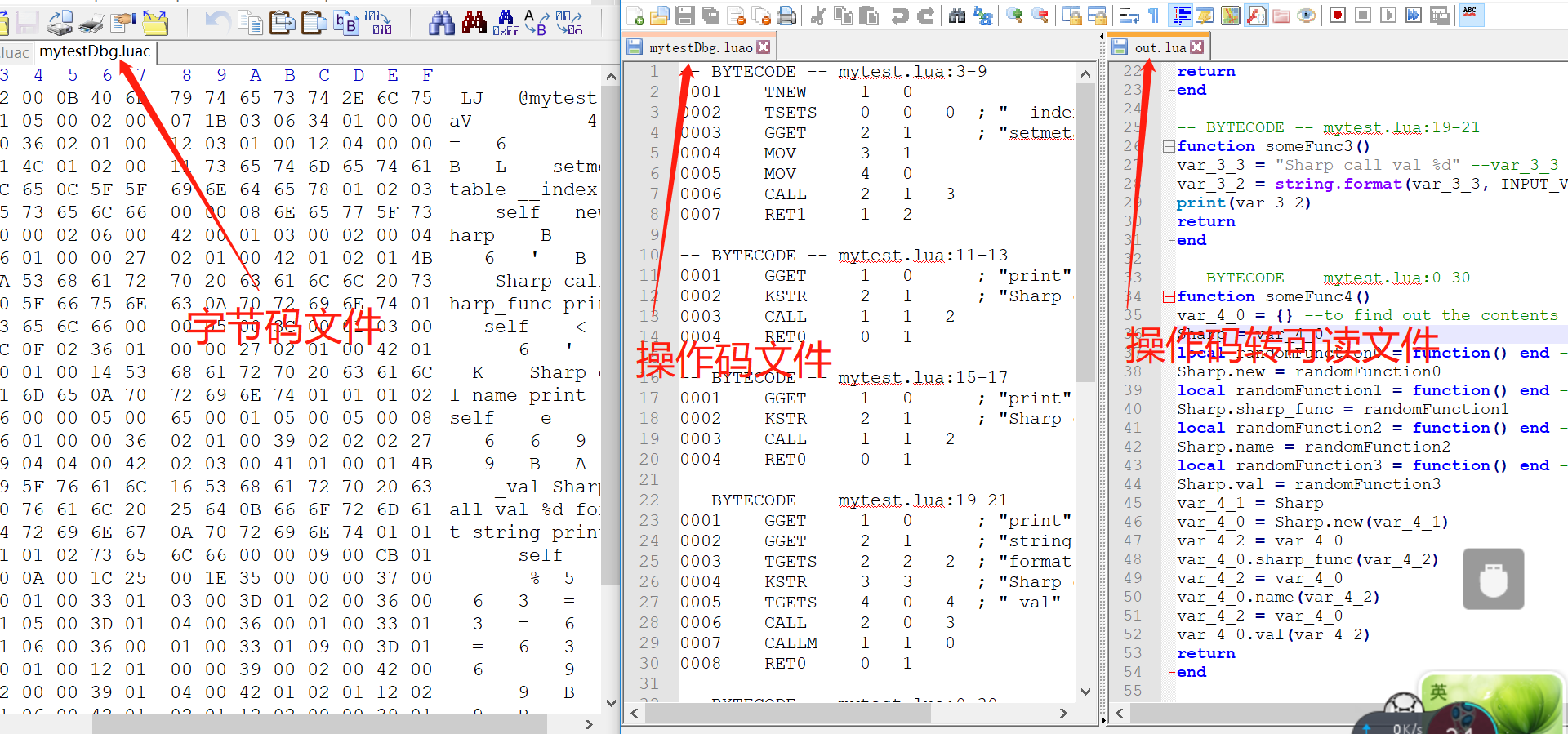
方案二
分析luajit字節碼文件,及對應版本的luajit源碼,寫反編譯工具將字節碼直接反編譯成luajit源碼。我們主要分析這種。
過程中主要參照這三篇文章:
(1)Luajit字節碼分析:https://github.com/feicong/lua_re/blob/master/lua/lua_re3.md
(2)Luajit反編譯工具:https://github.com/NightNord/ljd
(3)對nightnord的luajit反編譯工具ljd的應用經驗總結:
https://bbs.pediy.com/thread-216800.htm
三、Ljd源碼分析
(1)ljd目錄結構說明
![目錄結構.png]() (2)ljd函數調用流程分析
(2)ljd函數調用流程分析

畫了一張解析時調用流程圖:
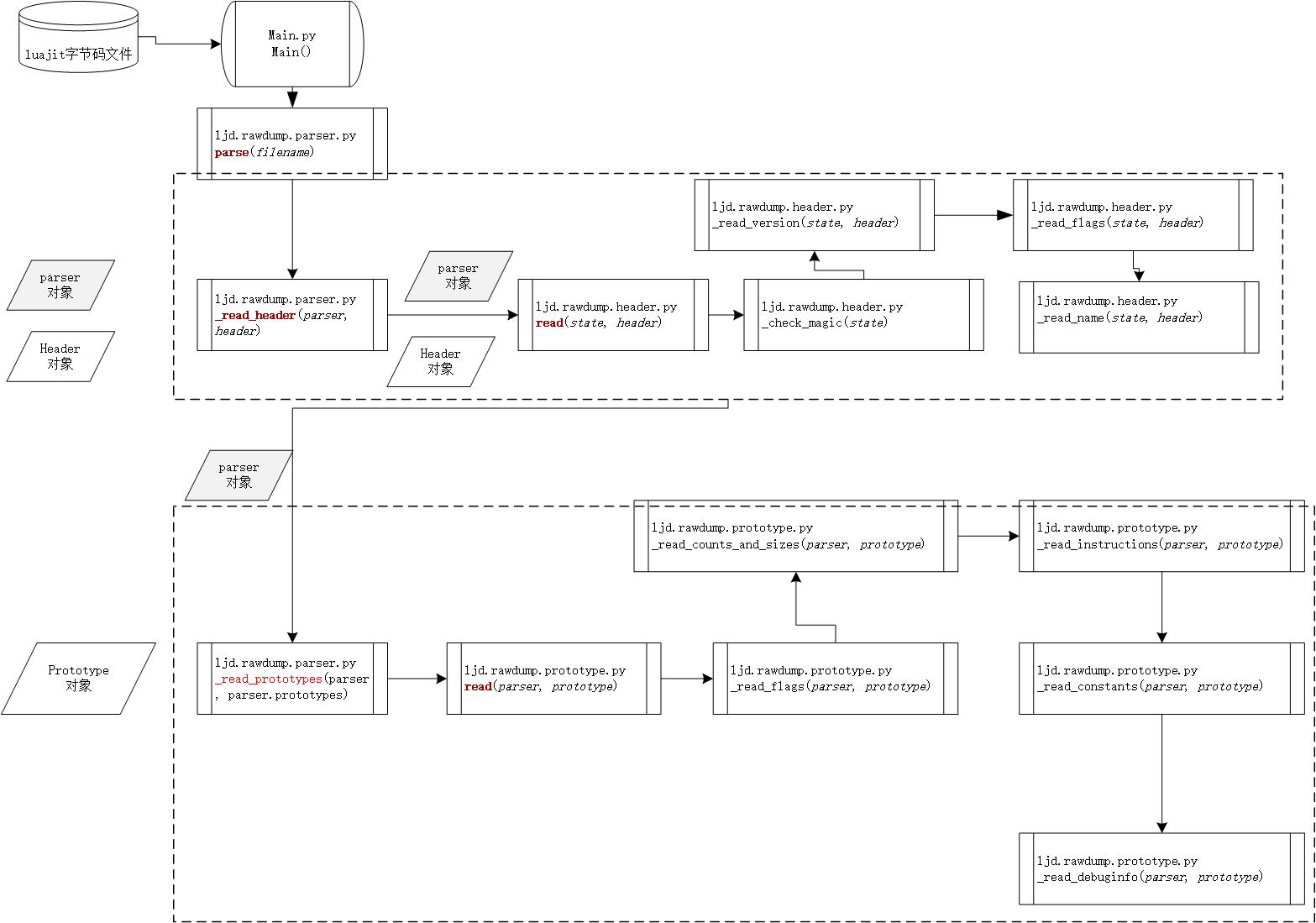
詳細分析如下:
Main函數調用ljd.rawdump.parser.parse函數,如下:

parse會生成state對象實例parser和header對象實例header,然後調用_reader_header方法,並將parser和header傳進去,如下圖:
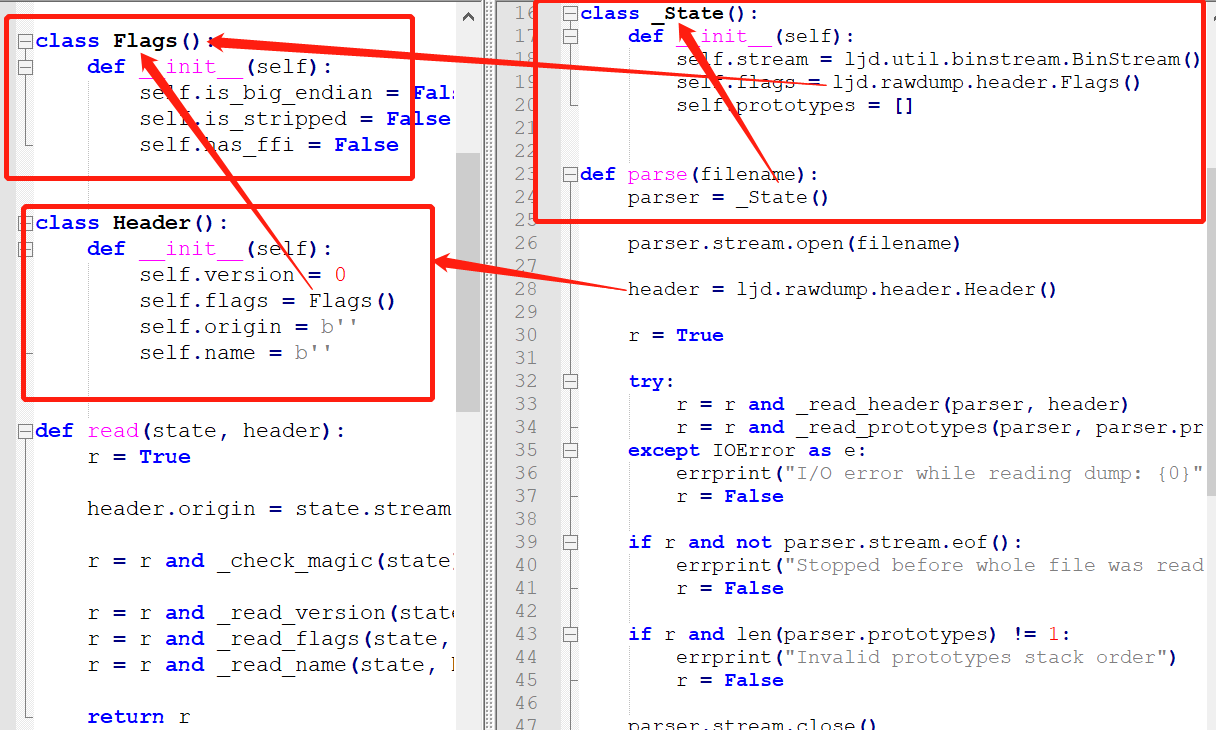
_reader_header調用read函數,如下圖:

進入_check_magic、_read_vesion、_read_flags、_read_name函數查看的話,能得到magic爲3個字節,version爲1個字節,flags大小爲1個uleb128,而接下來的源碼文件名取決於flags裏的is_stripped標誌位,如果這個標誌位是0,代表有字節碼包含調試信息,文件中接下來的字節存放的是源碼名稱,否則不包含調試信息,接下來的字節內容就是prototypes。
_reader_header方法調用完成之後,會調用_read_prototypes函數,如下圖:
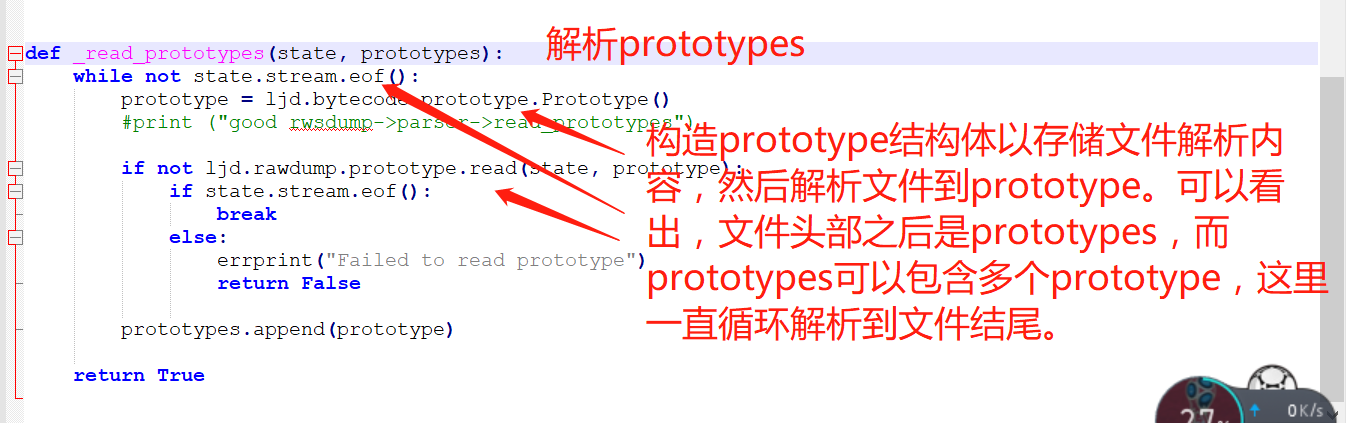
這個函數會循環讀取文件字節到prototype對象,我們來看prototype結構:

可以看到裏面包含標誌、參數數量及操作指令及大小數量、常量、調試信息,但是沒看到整個prototype的大小信息及各個字段的字節大小信息。我們接着往下看ljd.rawdump.prototype.read函數:
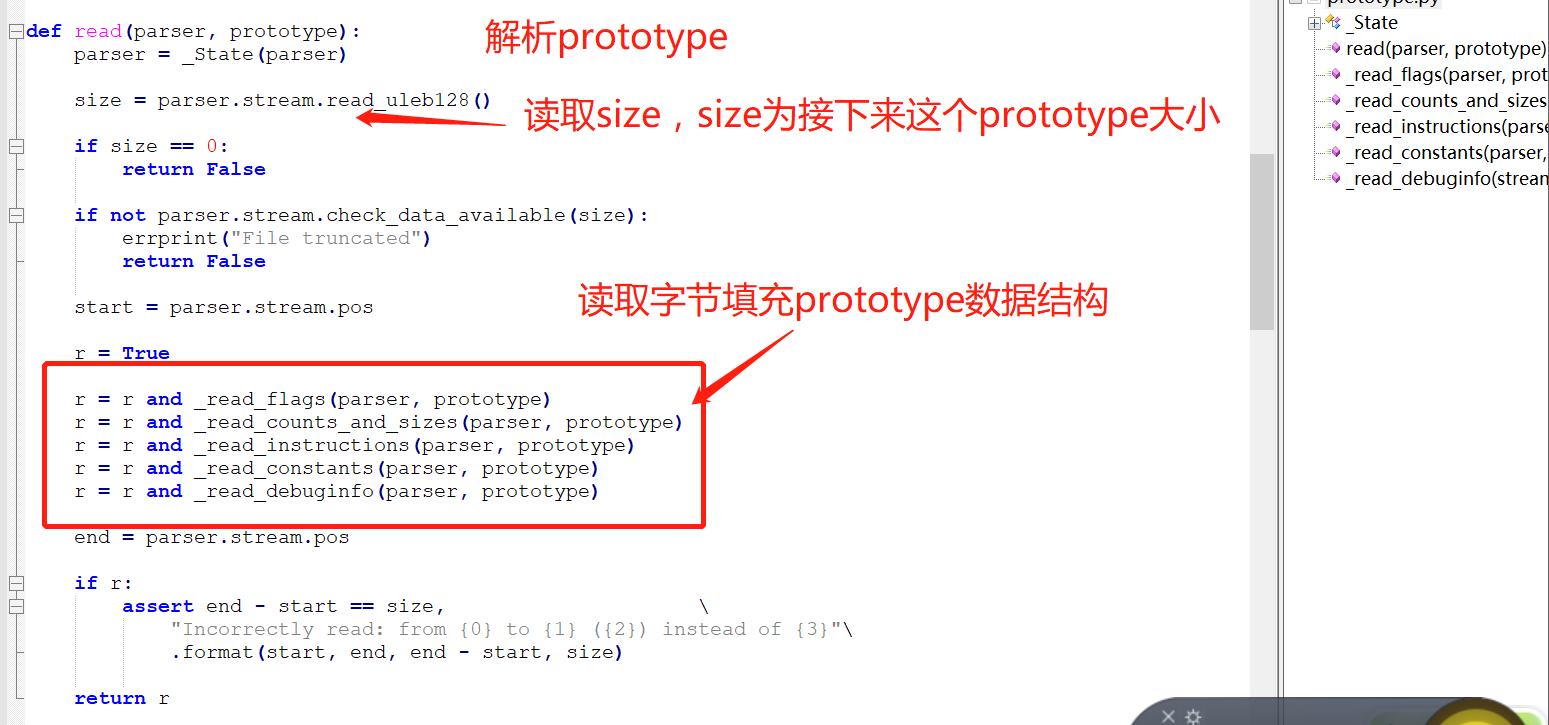
根據上面的分析,製作下圖,以直觀反映luajit字節碼文件結構:
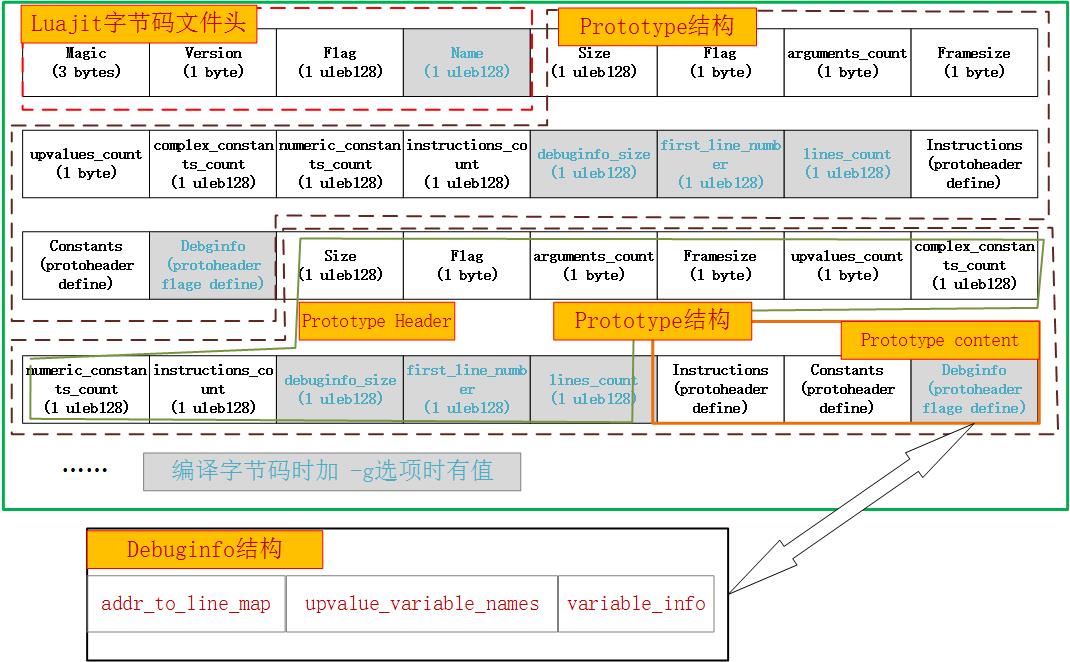
(3)ljd的bug所在
還是需要看一下解析時的調用流程:
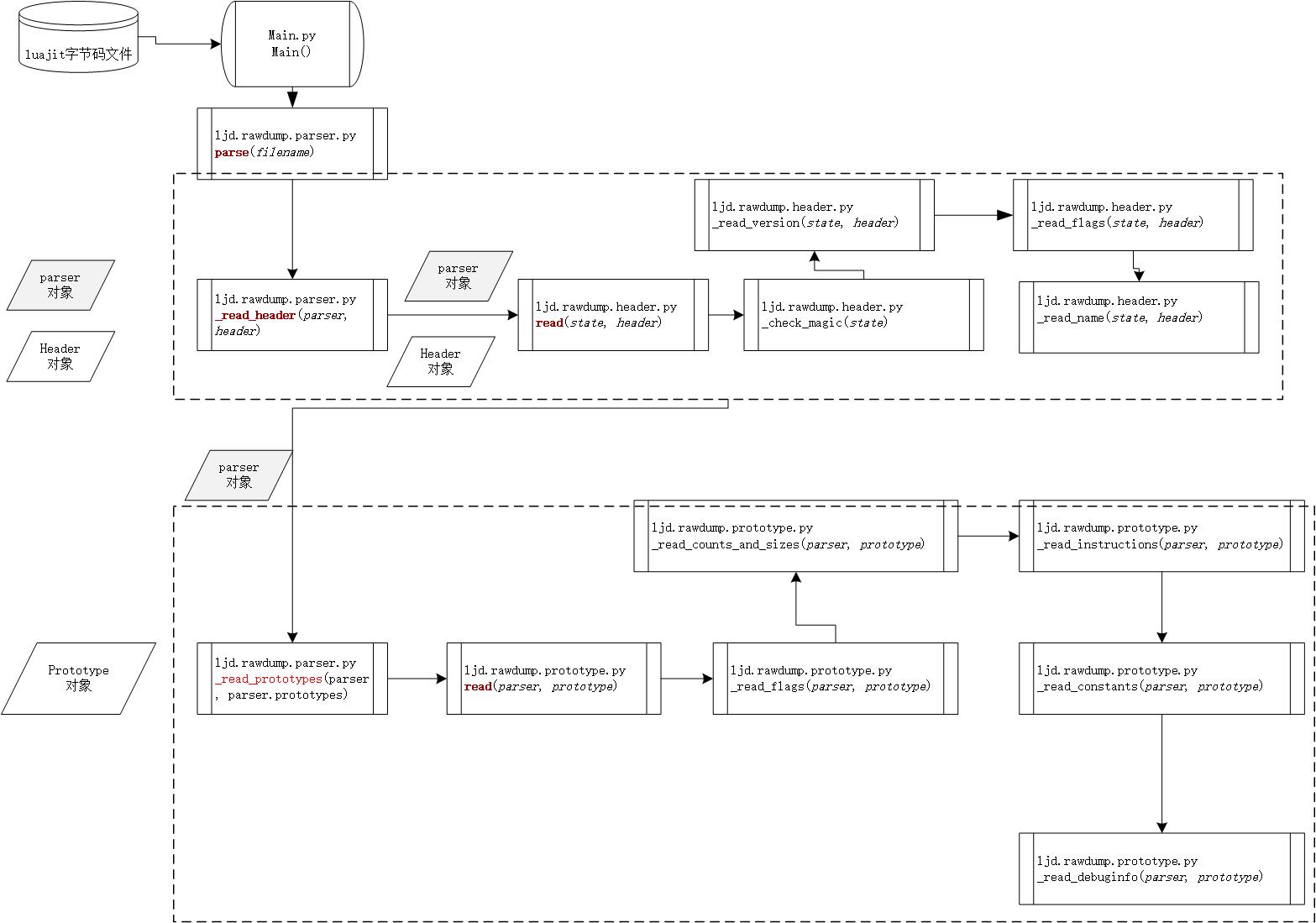
從圖中可以很明顯的看到,在ljd.rawdump.parser.py中的parser函數中,構造了parser和header對象,然後調用_read_header函數,讀取luajit字節碼文件的文件頭到header對象,接下來調用_read_protoypes函數,並傳遞parser對象,由ljd.rawdump.prototype中的read負責解析。這是解析luajit字節碼的一個宏觀過程,我貼一張調試過程中的圖,就能明顯看到問題所在了,調試1:
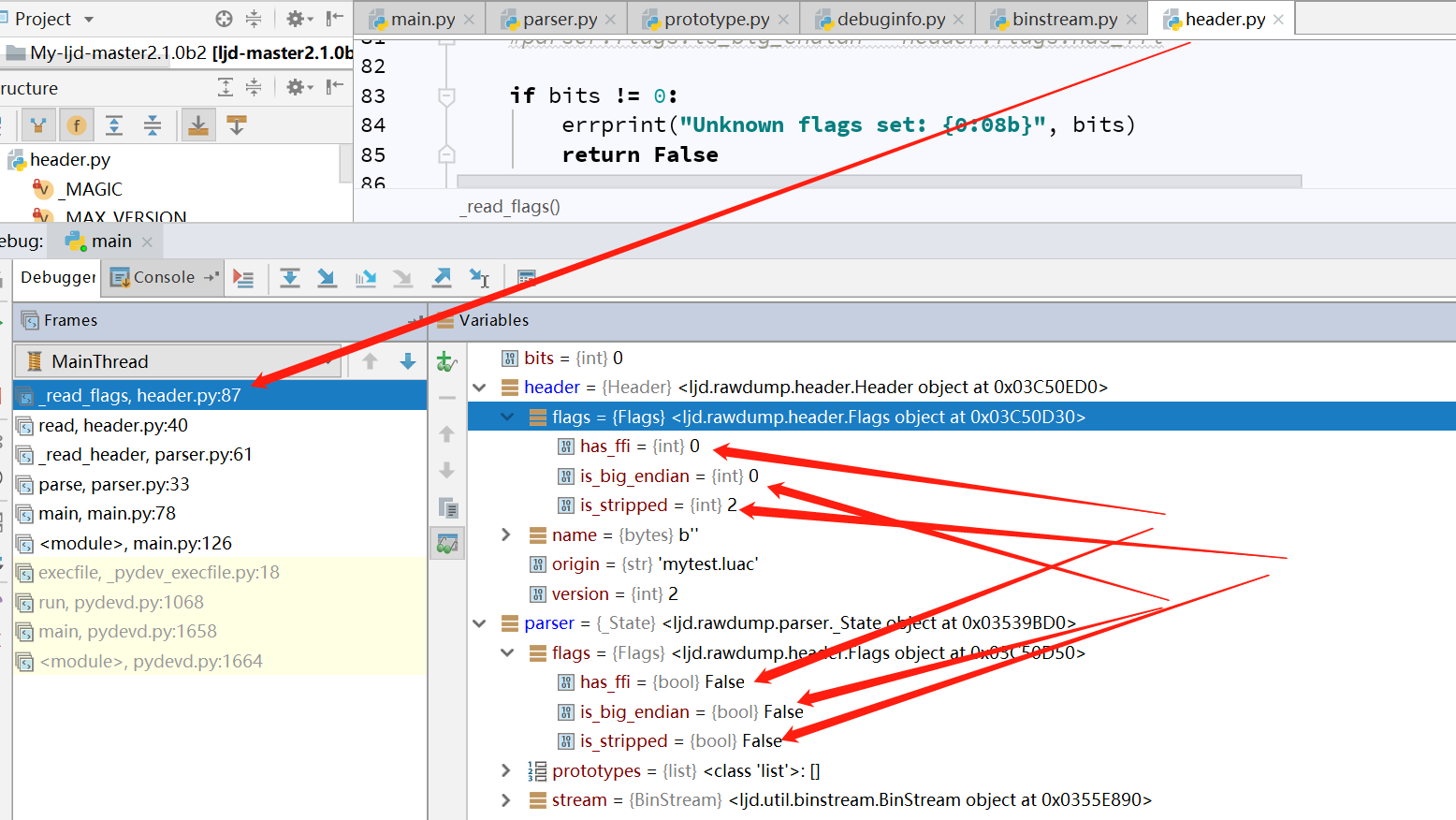
調試二:
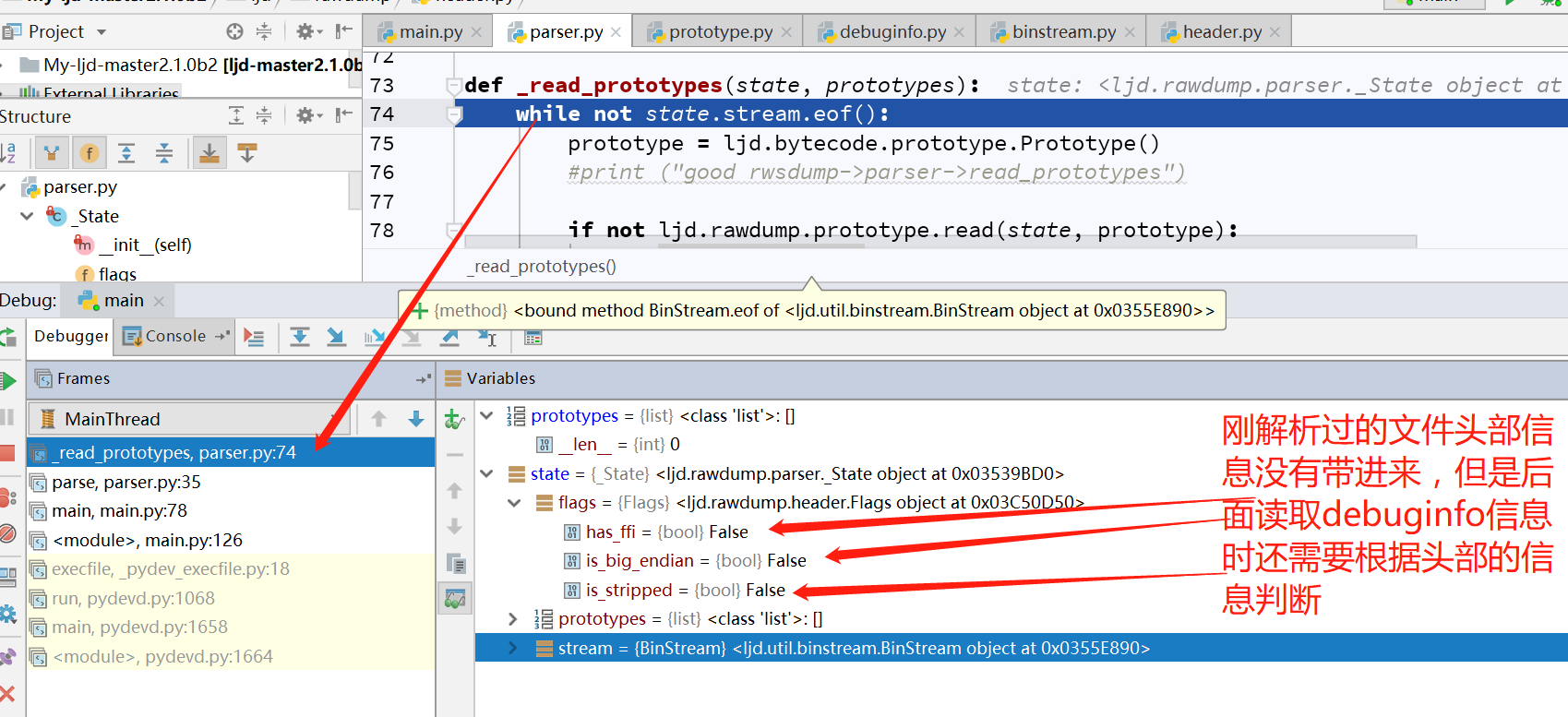
可以明顯看出來_read_header函數解析過的header中的flag值沒有被帶進_read_protoypes函數,而後面讀取debuginfo信息時,是需要根據header中的flag值去判斷,這裏就出現了bug。因爲程序默認是讀取的帶有調試信息的luajit字節碼文件,所以當讀取帶有調試信息的luajit字節碼文件,bug不顯,但是當讀取不帶調試信息的luajit字節碼文件時,程序就會解析錯誤。如下:
錯誤一:
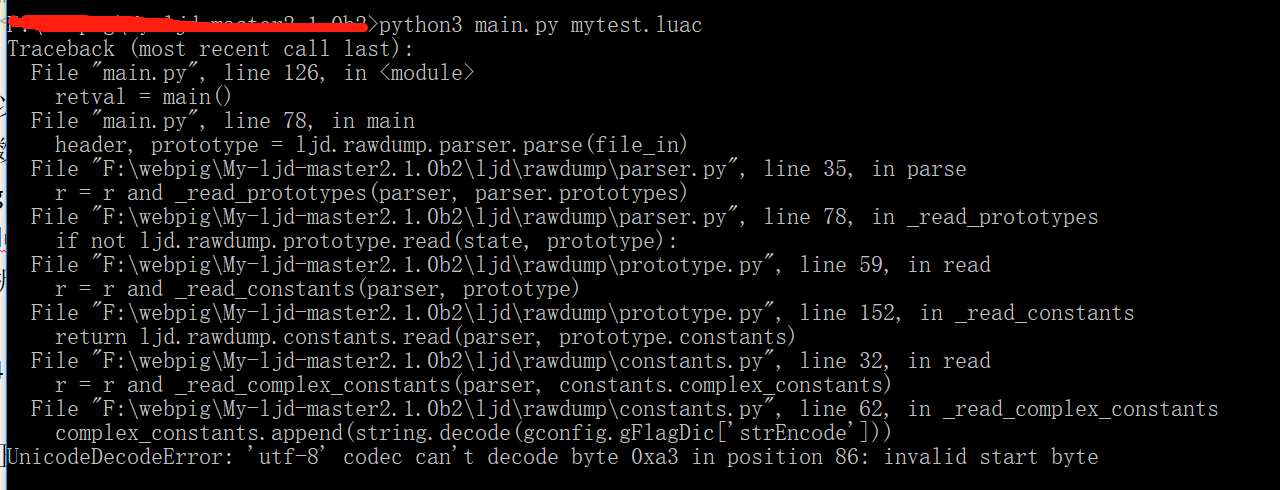
如果此時認爲是編碼問題的話,你可能會將編碼都調成”Unicode-escape”,但是依然會出錯。錯誤二:
![錯誤2.png]() (4)修正ljd的bug
(4)修正ljd的bug

知道bug原因了,就可以直接動手改了。如圖:
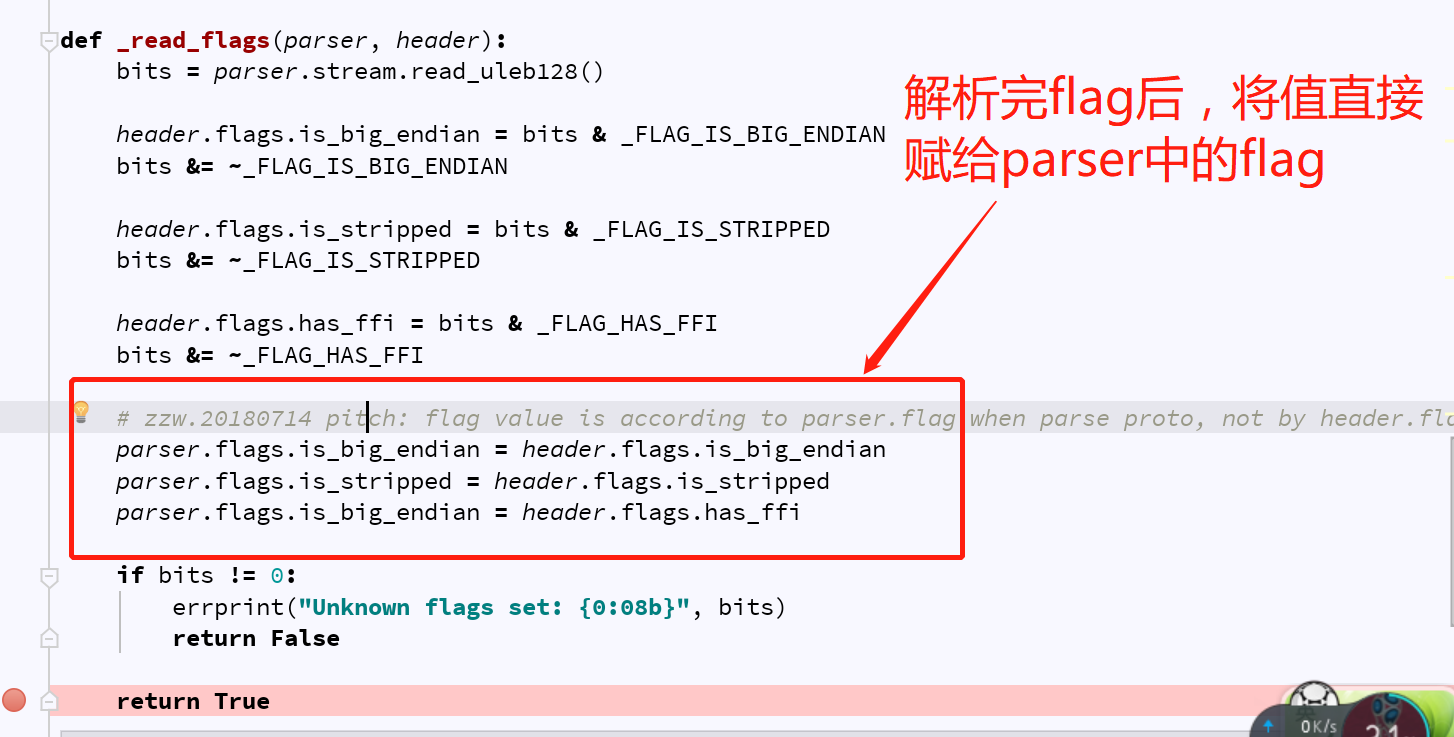
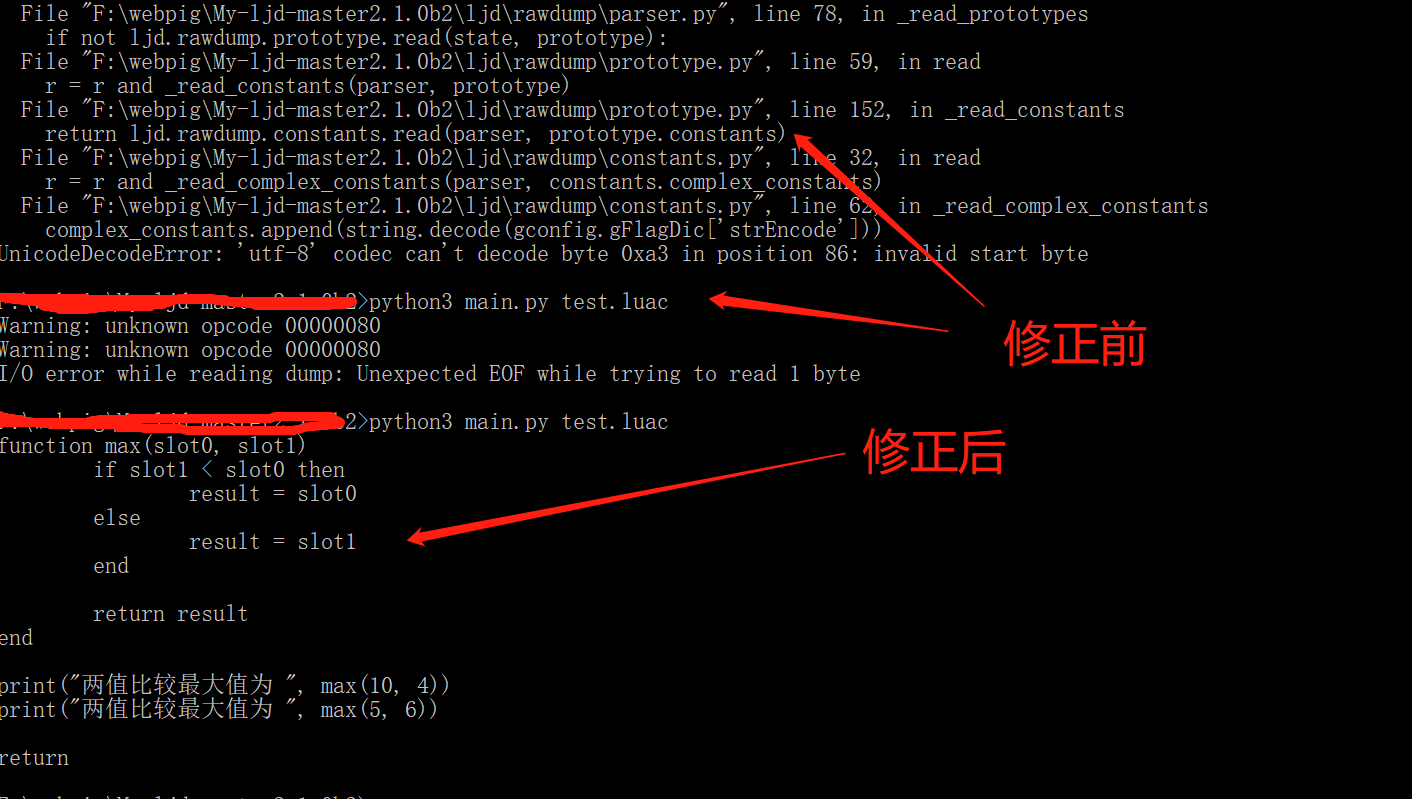
四、結果
(1)當用LuaJit編譯Lua源碼時,編譯字節碼時如果加-g選項,即字節碼包含調試信息,反編譯時幾乎可以完全還原的,還原效果如下圖:
(3)修正後源碼
修正後的工具源碼地址:https://github.com/zzwlpx/ljd
注意事項:工具使用環境python3+,用法:pythonmani.py “path”
Luajit 源碼下載地址:http://luajit.org/download.html windows下需要用vs控制檯編譯。