




本文轉自 https://www.cnblogs.com/kukri/p/9109639.html
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫裏查看
喜歡的話麻煩點下Star哈
文章同步發於我的個人博客:
www.how2playlife.com
本文是微信公衆號【Java技術江湖】的《Java併發指南》其中一篇,本文大部分內容來源於網絡,爲了把本文主題講得清晰透徹,也整合了很多我認爲不錯的技術博客內容,引用其中了一些比較好的博客文章,如有侵權,請聯繫作者。
該系列博文會告訴你如何全面深入地學習Java併發技術,從Java多線程基礎,再到併發編程的基礎知識,從Java併發包的入門和實戰,再到JUC的源碼剖析,一步步地學習Java併發編程,並上手進行實戰,以便讓你更完整地瞭解整個Java併發編程知識體系,形成自己的知識框架。
爲了更好地總結和檢驗你的學習成果,本系列文章也會提供一些對應的面試題以及參考答案。
如果對本系列文章有什麼建議,或者是有什麼疑問的話,也可以關注公衆號【Java技術江湖】聯繫作者,歡迎你參與本系列博文的創作和修訂。
<!--more -->
簡介
首先介紹兩個名詞:1)可見性:一個線程對共享變量值的修改,能夠及時地被其他線程看到。2)共享變量:如果一個變量在多個線程的工作內存中都存在副本,那麼這個變量就是這幾個線程的共享變量
Java線程之間的通信對程序員完全透明,在併發編程中,需要處理兩個關鍵問題:線程之間如何通信及線程之間如何同步。
通信:通信是指線程之間以何種機制來交換信息。在命令式編程中,線程之間的通信機制有兩種:共享內存和消息傳遞。在共享內存的併發模型裏,線程之間共享程序的公共狀態,通過寫-讀內存中的公共狀態來進行隱式通信。在消息傳遞的併發模型裏,線程之間沒有公共狀態,線程之間必須通過發送消息來進行顯示通信。
同步:同步是指程序中用於控制不同線程間操作發生相對順序的機制。在共享內存併發模型裏,同步是顯示進行的,程序員必須顯示指定某個方法或某段代碼需要在線程之間互斥執行。在消息傳遞的併發模型裏,由於消息的發送必須在消息的接收之前,因此同步是隱式進行的。
Java併發採用的是共享內存模型。
一、Java內存區域(JVM內存區域)
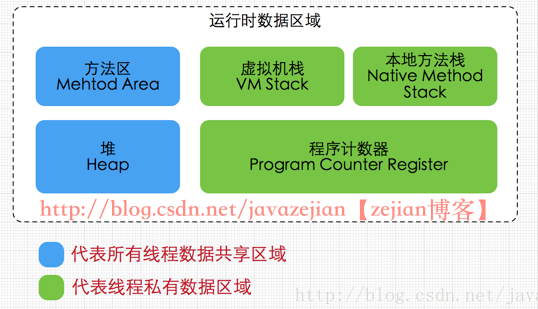
Java虛擬機在運行程序時會把其自動管理的內存劃分爲以上幾個區域,每個區域都有的用途以及創建銷燬的時機,其中藍色部分代表的是所有線程共享的數據區域,而綠色部分代表的是每個線程的私有數據區域。
-
方法區(Method Area):
方法區屬於線程共享的內存區域,又稱Non-Heap(非堆),主要用於存儲已被虛擬機加載的類信息、常量、靜態變量、即時編譯器編譯後的代碼等數據,根據Java 虛擬機規範的規定,當方法區無法滿足內存分配需求時,將拋出OutOfMemoryError 異常。值得注意的是在方法區中存在一個叫運行時常量池(Runtime Constant Pool)的區域,它主要用於存放編譯器生成的各種字面量和符號引用,這些內容將在類加載後存放到運行時常量池中,以便後續使用。
-
JVM堆(Java Heap):
Java 堆也是屬於線程共享的內存區域,它在虛擬機啓動時創建,是Java 虛擬機所管理的內存中最大的一塊,主要用於存放對象實例,幾乎所有的對象實例都在這裏分配內存,注意Java 堆是垃圾收集器管理的主要區域,因此很多時候也被稱做GC 堆,如果在堆中沒有內存完成實例分配,並且堆也無法再擴展時,將會拋出OutOfMemoryError 異常。
-
程序計數器(Program Counter Register):
屬於線程私有的數據區域,是一小塊內存空間,主要代表當前線程所執行的字節碼行號指示器。字節碼解釋器工作時,通過改變這個計數器的值來選取下一條需要執行的字節碼指令,分支、循環、跳轉、異常處理、線程恢復等基礎功能都需要依賴這個計數器來完成。
-
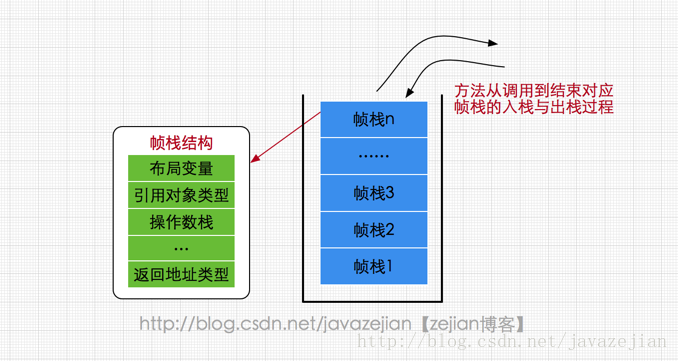
虛擬機棧(Java Virtual Machine Stacks):
屬於線程私有的數據區域,與線程同時創建,總數與線程關聯,代表Java方法執行的內存模型。棧中只保存基礎數據類型和自定義對象的引用(不是對象),對象都存放在堆區中。每個方法執行時都會創建一個棧楨來存儲方法的的變量表、操作數棧、動態鏈接方法、返回值、返回地址等信息。每個方法從調用直結束就對於一個棧楨在虛擬機棧中的入棧和出棧過程,如下(圖有誤,應該爲棧楨):
-
本地方法棧(Native Method Stacks):
本地方法棧屬於線程私有的數據區域,這部分主要與虛擬機用到的 Native 方法相關,一般情況下,我們無需關心此區域。
二、Java內存模型
Java內存模型(即Java Memory Model,簡稱JMM)本身是一種抽象的概念,並不真實存在。Java線程之間的通信由JMM控制,JMM決定一個線程對共享變量的寫入何時對另一個線程可見。從抽象的角度來看,JMM定義了線程和主內存之間的抽象關係。
由於JVM運行程序的實體是線程,而每個線程創建時JVM都會爲其創建一個工作內存(有些地方稱爲棧空間),用於存儲線程私有的數據,而Java內存模型中規定所有變量都存儲在主內存,主內存是共享內存區域,所有線程都可以訪問,但線程對變量的操作(讀取賦值等)必須在工作內存中進行。
首先要將變量從主內存拷貝的自己的工作內存空間,然後對變量進行操作,操作完成後再將變量寫回主內存,不能直接操作主內存中的變量,工作內存中存儲着主內存中的變量副本拷貝,前面說過,工作內存是每個線程的私有數據區域,因此不同的線程間無法訪問對方的工作內存,線程間的通信(傳值)必須通過主內存來完成,其簡要訪問過程如下圖
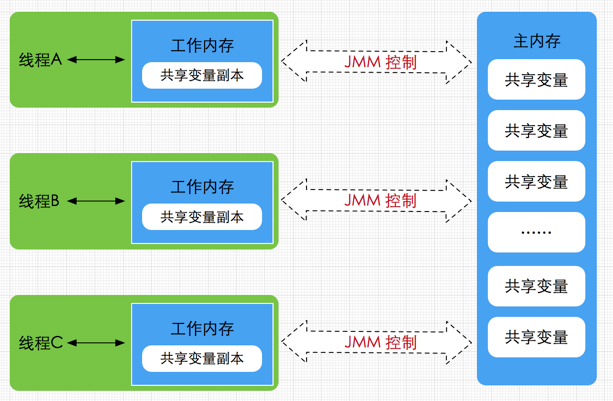
圖3
需要注意的是,JMM與Java內存區域的劃分是不同的概念層次,更恰當說JMM描述的是一組規則,通過這組規則控制程序中各個變量在共享數據區域和私有數據區域的訪問方式,JMM是圍繞原子性,有序性、可見性展開的(稍後會分析)。
JMM與Java內存區域唯一相似點,都存在共享數據區域和私有數據區域,在JMM中主內存屬於共享數據區域,從某個程度上講應該包括了堆和方法區,而工作內存數據線程私有數據區域,從某個程度上講則應該包括程序計數器、虛擬機棧以及本地方法棧。或許在某些地方,我們可能會看見主內存被描述爲堆內存,工作內存被稱爲線程棧,實際上他們表達的都是同一個含義。關於JMM中的主內存和工作內存說明如下
-
主內存
主要存儲的是Java實例對象以及線程之間的共享變量,所有線程創建的實例對象都存放在主內存中,不管該實例對象是成員變量還是方法中的本地變量(也稱局部變量),當然也包括了共享的類信息、常量、靜態變量。由於是共享數據區域,多條線程對同一個變量進行訪問可能會發現線程安全問題。
-
工作內存
有的書籍中也稱爲本地內存,主要存儲當前方法的所有本地變量信息(工作內存中存儲着主內存中的變量副本拷貝),每個線程只能訪問自己的工作內存,即線程中的本地變量對其它線程是不可見的,就算是兩個線程執行的是同一段代碼,它們也會各自在自己的工作內存中創建屬於當前線程的本地變量,當然也包括了字節碼行號指示器、相關Native方法的信息。
注意由於工作內存是每個線程的私有數據,線程間無法相互訪問工作內存,因此存儲在工作內存的數據不存在線程安全問題。注意,工作內存是JMM的一個抽象概念,並不真實存在。
弄清楚主內存和工作內存後,接瞭解一下主內存與工作內存的數據存儲類型以及操作方式,根據虛擬機規範,對於一個實例對象中的成員方法而言,如果方法中包含本地變量是基本數據類型(boolean,byte,short,char,int,long,float,double),將直接存儲在工作內存的幀棧結構中,但倘若本地變量是引用類型,那麼該變量的引用會存儲在功能內存的幀棧中,而對象實例將存儲在主內存(共享數據區域,堆)中。
但對於實例對象的成員變量,不管它是基本數據類型或者包裝類型(Integer、Double等)還是引用類型,都會被存儲到堆區。至於static變量以及類本身相關信息將會存儲在主內存中。需要注意的是,在主內存中的實例對象可以被多線程共享,倘若兩個線程同時調用了同一個對象的同一個方法,那麼兩條線程會將要操作的數據拷貝一份到自己的工作內存中,執行完成操作後才刷新到主內存,簡單示意圖如下所示:
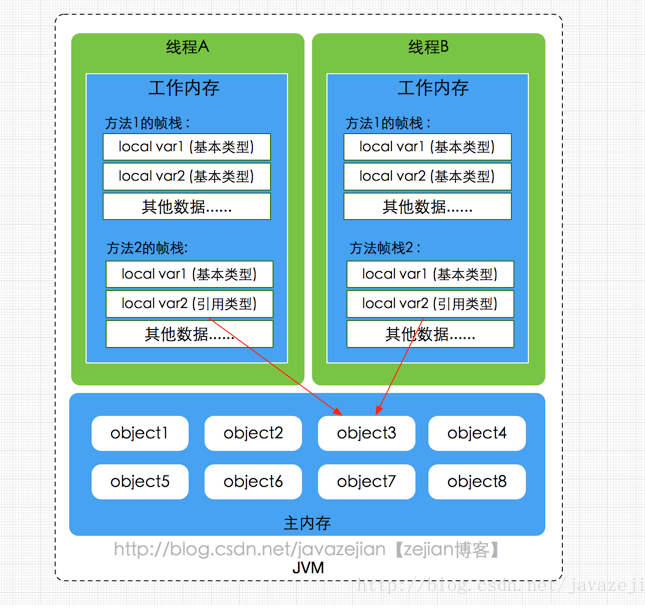
圖4
從圖3來看,如果線程A與線程B之間要通信的話,必須經歷下面兩個步驟:
1)線程A把本地內存A中更新過的共享變量刷新到主內存中去
2)線程B到主內存中去讀取線程A之前已更新過的共享變量
從以上兩個步驟來看,共享內存模型完成了“隱式通信”的過程。
JMM也主要是通過控制主內存與每個線程的工作內存之間的交互,來爲Java程序員提供內存可見性的保證。
三、as-if-serial語義、happens-before原則
3.1 as-if-serial語義
重排序是指編譯器和處理器爲了優化程序性能而對指令序列進行重新排序的一種手段。as-if-serial語義的意思是:不管怎麼重排序(編譯器和處理器爲了提高並行度),(單線程)程序的執行結果不能被改變。編譯器、runtime和處理器都必須遵守as-if-serial語義。爲了遵守as-if-serial語義,編譯器和處理器不會對存在數據依賴關係的操作做重排序,因爲這種重排序會改變執行結果。
但是,如果操作之間不存在數據依賴關係,這些操作就可能被編譯器和處理器重排序。
3.2 happens-before原則
happens-before是JMM最核心的概念。對應Java程序來說,理解happens-before是理解JMM的關鍵。
設計JMM時,需要考慮兩個關鍵因素:
-
- 程序員對內存模型的使用。程序員希望內存模型易於理解、易於編程。程序員希望基於一個強內存模型來編寫代碼。
- 編譯器和處理器對內存模型的實現。編譯器和處理器希望內存模型對它們的束縛越少越好,這樣它們就可以做儘可能多的優化來提高性能。編譯器和處理器希望實現弱內存模型。
但以上兩點相互矛盾,所以JSR-133專家組在設計JMM時的核心膜表就是找到一個好的平衡點:一方面,爲程序員提高足夠強的內存可見性保證;另一方面,對編譯器和處理器的限制儘可能地放鬆。
另外還要一個特別有意思的事情就是關於重排序問題,更簡單的說,重排序可以分爲兩類:1)會改變程序執行結果的重排序。 2) 不會改變程序執行結果的重排序。
JMM對這兩種不同性質的重排序,採取了不同的策略,如下:
- 對於會改變程序執行結果的重排序,JMM要求編譯器和處理器必須禁止這種重排序。
- 對於不會改變程序執行結果的重排序,JMM對編譯器和處理器不做要求(JMM允許這種 重排序)
JMM的設計圖爲:

JMM設計示意圖 從圖可以看出:
- JMM向程序員提供的happens-before規則能滿足程序員的需求。JMM的happens-before規則不但簡單易懂,而且也向程序員提供了足夠強的內存可見性保證(有些內存可見性保證其實並不一定真實存在,比如上面的A happens-before B)。
- JMM對編譯器和處理器的束縛已經儘可能少。從上面的分析可以看出,JMM其實是在遵循一個基本原則:只要不改變程序的執行結果(指的是單線程程序和正確同步的多線程程序),編譯器和處理器怎麼優化都行。例如,如果編譯器經過細緻的分析後,認定一個鎖只會被單個線程訪問,那麼這個鎖可以被消除。再如,如果編譯器經過細緻的分析後,認定一個volatile變量只會被單個線程訪問,那麼編譯器可以把這個volatile變量當作一個普通變量來對待。這些優化既不會改變程序的執行結果,又能提高程序的執行效率。
3.3 happens-before定義
happens-before的概念最初由Leslie Lamport在其一篇影響深遠的論文(《Time,Clocks and the Ordering of Events in a Distributed System》)中提出。JSR-133使用happens-before的概念來指定兩個操作之間的執行順序。由於這兩個操作可以在一個線程之內,也可以是在不同線程之間。因此,JMM可以通過happens-before關係向程序員提供跨線程的內存可見性保證(如果A線程的寫操作a與B線程的讀操作b之間存在happens-before關係,儘管a操作和b操作在不同的線程中執行,但JMM向程序員保證a操作將對b操作可見)。具體的定義爲:
1)如果一個操作happens-before另一個操作,那麼第一個操作的執行結果將對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前。
2)兩個操作之間存在happens-before關係,並不意味着Java平臺的具體實現必須要按照happens-before關係指定的順序來執行。如果重排序之後的執行結果,與按happens-before關係來執行的結果一致,那麼這種重排序並不非法(也就是說,JMM允許這種重排序)。
上面的1)是JMM對程序員的承諾。從程序員的角度來說,可以這樣理解happens-before關係:如果A happens-before B,那麼Java內存模型將向程序員保證——A操作的結果將對B可見,且A的執行順序排在B之前。注意,這只是Java內存模型向程序員做出的保證!
上面的2)是JMM對編譯器和處理器重排序的約束原則。正如前面所言,JMM其實是在遵循一個基本原則:只要不改變程序的執行結果(指的是單線程程序和正確同步的多線程程序),編譯器和處理器怎麼優化都行。JMM這麼做的原因是:程序員對於這兩個操作是否真的被重排序並不關心,程序員關心的是程序執行時的語義不能被改變(即執行結果不能被改變)。因此,happens-before關係本質上和as-if-serial語義是一回事。
3.3 happens-before對比as-if-serial
- as-if-serial語義保證單線程內程序的執行結果不被改變,happens-before關係保證正確同步的多線程程序的執行結果不被改變。
- as-if-serial語義給編寫單線程程序的程序員創造了一個幻境:單線程程序是按程序的順序來執行的。happens-before關係給編寫正確同步的多線程程序的程序員創造了一個幻境:正確同步的多線程程序是按happens-before指定的順序來執行的。
- as-if-serial語義和happens-before這麼做的目的,都是爲了在不改變程序執行結果的前提下,儘可能地提高程序執行的並行度。
3.4 happens-before具體規則
- 程序順序規則:一個線程中的每個操作,happens-before於該線程中的任意後續操作。
- 監視器鎖規則:對一個鎖的解鎖,happens-before於隨後對這個鎖的加鎖。
- volatile變量規則:對一個volatile域的寫,happens-before於任意後續對這個volatile域的讀。
- 傳遞性:如果A happens-before B,且B happens-before C,那麼A happens-before C。
- start()規則:如果線程A執行操作ThreadB.start()(啓動線程B),那麼A線程的ThreadB.start()操作happens-before於線程B中的任意操作。
- join()規則:如果線程A執行操作ThreadB.join()併成功返回,那麼線程B中的任意操作happens-before於線程A從ThreadB.join()操作成功返回。
3.5 happens-before與JMM的關係圖
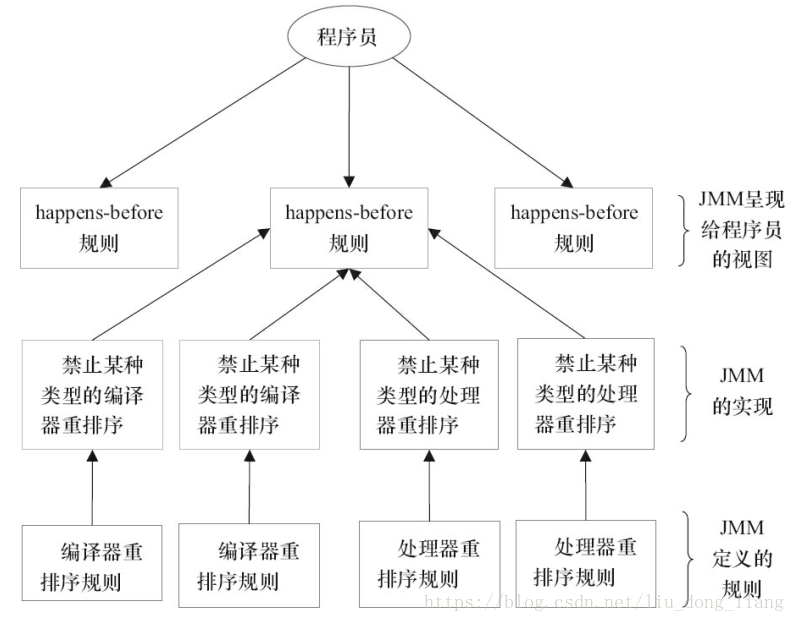
一個happens-before規則對應於一個或多個編譯器和處理器重排序規則。對於Java程序員來說,happens-before規則簡單易懂,它避免Java程序員爲了理解JMM提供的內存可見性保證而去學習複雜的重排序規則以及這些規則的具體實現方法
四、volatile、鎖的內存語義
4.1 volatile的內存語義
當聲明共享變量爲volatile後,對這個變量的讀/寫會很特別。一個volatile變量的單個讀/寫操作,與一個普通變量的讀/寫操作都是使用同一個鎖來同步,它們之間的執行效果相同。
鎖的happens-before規則保證釋放鎖和獲取鎖的兩個線程之間的內存可見性,這意味着對一個volatile變量的讀,總是能看到(任意線程)對這個volatile變量最後的寫入。
鎖的語義決定了臨界區代碼的執行具有原子性。這意味着,即使是64位的long型和double型變量,只要是volatile變量,對該變量的讀/寫就具有原子性。如果是多個volatile操作或類似於volatile++這種複合操作,這些操作整體上不具有原子性。
簡而言之,一旦一個共享變量(類的成員變量、類的靜態成員變量)被volatile修飾之後,那麼就具備了兩層語義:
1)保證了不同線程對這個變量進行操作時的可見性,即一個線程修改了某個變量的值,這新值對其他線程來說是立即可見的。
2)禁止進行指令重排序。
- 可見性。對一個volatiole變量的讀,總是能看到(任意線程)對這個volatile變量最後的寫入。
-
有序性。volatile關鍵字能禁止指令重排序,所以volatile能在一定程度上保證有序性。
volatile關鍵字禁止指令重排序有兩層意思:
1)當程序執行到volatile變量的讀操作或者寫操作時,在其前面的操作的更改肯定全部已經進行,且結果已經對後面的操作可見;在其後面的操作肯定還沒有進行;
2)在進行指令優化時,不能將在對volatile變量訪問的語句放在其後面執行,也不能把volatile變量後面的語句放到其前面執行。
可能上面說的比較繞,舉個簡單的例子:
<pre>//x、y爲非volatile變量 //flag爲volatile變量
x = 2; //語句1
y = 0; //語句2
flag = true; //語句3
x = 4; //語句4
y = -1; //語句5</pre>
由於flag變量爲volatile變量,那麼在進行指令重排序的過程的時候,不會將語句3放到語句1、語句2前面,也不會講語句3放到語句4、語句5後面。但是要注意語句1和語句2的順序、語句4和語句5的順序是不作任何保證的。
- 原子性。對任意單個volatile變量的讀、寫具有原子性,但類似於volatile++這種複合操作不具有原子性。
volatile寫的內存語義:當寫一個volatile變量時,JMM會把該線程對應的本地內存中的共享變量值刷新到主內存。
volatile讀的內存語義:當讀一個volatile變量時,JMM會把該線程對應的本地內存置位無效。線程接下來將從主內存中讀取共享變量。(強制從主內存讀取共享變量,把本地內存與主內存的共享變量的值變成一致)。
volatile寫和讀的內存語義總結總結:
- 線程A寫一個volatile變量,實質上是線程A向接下來將要讀這個volatile變量的某個線程發出了(其對變量所做修改的)消息。
- 線程B讀一個volatile變量,實質上是線程B接收了之前某個線程發出的消息。
- 線程A寫一個volatile變量,隨後線程B讀這個volatile變量,這個過程實質上是線程A通過主內存向線程B發送消息。(隱式通信)
4.2 volatile內存語義的實現
前面提到過編譯器重排序和處理器重排序。爲了實現volatile內存語義,JMM分別限制了這兩種類型的重排序類型。
- 當第二個操作是volatile寫時,不管第一個操作是什麼,都不能重排序。這個規則確保volatile寫之前的操作不會被編譯器重排序到volatile寫之後。
- 當第一個操作是volatile讀時,不管第二個操作是什麼,都不能重排序。這個規則確保volatile讀之後的操作不會被編譯器重排序到volatile讀之前。
- 當第一個操作是volatile寫時,第二個操作是volatile讀時,不能重排序。
爲了實現volatile的內存語義,編譯器在生成字節碼時,會在指令序列中插入內存屏障來禁止特定類型的處理器重排序。對於編譯器來說,發現一個最優佈置來最小化插入屏障的總數幾乎不可能。爲此,JMM採取保守策略。下面是基於保守策略的JMM內存屏障插入策略:
- 在每個volatile寫操作的前面插入一個StoreStore屏障。
- 在每個volatile寫操作的後面插入一個StoreLoad屏障。
- 在每個volatile讀操作的後面插入一個LoadLoad屏障。
- 在每個volatile讀操作的後面插入一個LoadStore屏障。
上述內存屏障插入策略非常保守,但它可以保證在任意處理器平臺,任意的程序中都能得到正確的volatile內存語義。
下面是保守策略下,volatile寫插入內存屏障後生成的指令序列示意圖:
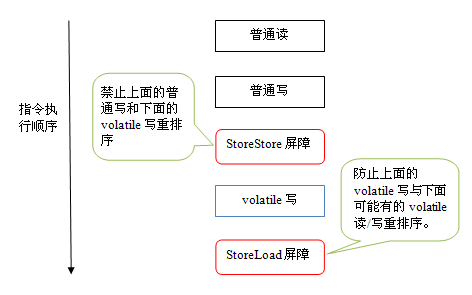
上圖中的StoreStore屏障可以保證在volatile寫之前,其前面的所有普通寫操作已經對任意處理器可見了。這是因爲StoreStore屏障將保障上面所有的普通寫在volatile寫之前刷新到主內存。
這裏比較有意思的是volatile寫後面的StoreLoad屏障。這個屏障的作用是避免volatile寫與後面可能有的volatile讀/寫操作重排序。因爲編譯器常常無法準確判斷在一個volatile寫的後面,是否需要插入一個StoreLoad屏障(比如,一個volatile寫之後方法立即return)。爲了保證能正確實現volatile的內存語義,JMM在這裏採取了保守策略:在每個volatile寫的後面或在每個volatile讀的前面插入一個StoreLoad屏障。從整體執行效率的角度考慮,JMM選擇了在每個volatile寫的後面插入一個StoreLoad屏障。因爲volatile寫-讀內存語義的常見使用模式是:一個寫線程寫volatile變量,多個讀線程讀同一個volatile變量。當讀線程的數量大大超過寫線程時,選擇在volatile寫之後插入StoreLoad屏障將帶來可觀的執行效率的提升。從這裏我們可以看到JMM在實現上的一個特點:首先確保正確性,然後再去追求執行效率。下面是在保守策略下,volatile讀插入內存屏障後生成的指令序列示意圖:

上圖中的LoadLoad屏障用來禁止處理器把上面的volatile讀與下面的普通讀重排序。LoadStore屏障用來禁止處理器把上面的volatile讀與下面的普通寫重排序。
上述volatile寫和volatile讀的內存屏障插入策略非常保守。在實際執行時,只要不改變volatile寫-讀的內存語義,編譯器可以根據具體情況省略不必要的屏障。下面我們通過具體的示例代碼來說明:
<pre>class VolatileBarrierExample { int a; volatile int v1 = 1; volatile int v2 = 2; void readAndWrite() { int i = v1; //第一個volatile讀
int j = v2; // 第二個volatile讀
a = i + j; //普通寫
v1 = i + 1; // 第一個volatile寫
v2 = j * 2; //第二個 volatile寫
}
… //其他方法
}</pre>
針對readAndWrite()方法,編譯器在生成字節碼時可以做如下的優化:

注意,最後的StoreLoad屏障不能省略。因爲第二個volatile寫之後,方法立即return。此時編譯器可能無法準確斷定後面是否會有volatile讀或寫,爲了安全起見,編譯器常常會在這裏插入一個StoreLoad屏障。
上面的優化是針對任意處理器平臺,由於不同的處理器有不同“鬆緊度”的處理器內存模型,內存屏障的插入還可以根據具體的處理器內存模型繼續優化。以x86處理器爲例,上圖中除最後的StoreLoad屏障外,其它的屏障都會被省略。
爲了提供一種比鎖更輕量級的線程之間通信的機制,JSR-133專家組決定增強volatile的內存語義:嚴格限制編譯器和處理器對volatile變量與普通變量的重排序,確保volatile的寫-讀和鎖的釋放-獲取具有相同的內存語義。
由於volatile僅僅保證對單個volatile變量的讀/寫具有原子性,而鎖的互斥執行的特性可以確保對整個臨界區代碼的執行具有原子性。在功能上,鎖比volatile更強大;在可伸縮性和執行性能上,volatile更有優勢。
當一個變量被定義爲volatile之後,就可以保證此變量對所有線程的可見性,即當一個線程修改了此變量的值的時候,變量新的值對於其他線程來說是可以立即得知的。可以理解成:對volatile變量所有的寫操作都能立刻被其他線程得知。但是這並不代表基於volatile變量的運算在併發下是安全的,因爲volatile只能保證內存可見性,卻沒有保證對變量操作的原子性。比如下面的代碼:
<pre>/ *
- 發起20個線程,每個線程對race變量進行10000次自增操作,如果代碼能夠正確併發,
- 則最終race的結果應爲200000,但實際的運行結果卻小於200000。
- @author Colin Wang */
public class Test { public static volatile int race = 0; public static void increase() {
race++;
} private static final int THREADS_COUNT = 20; public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_COUNT]; for (int i = 0; i < THREADS_COUNT; i++) {
threads[i] = new Thread(new Runnable() {
@Override public void run() { for (int i = 0; i < 10000; i++) {
increase();
}
}
});
threads[i].start();
} while (Thread.activeCount() > 1)
Thread.yield();
System.out.println(race);
}}</pre>
按道理來說結果是10000,但是運行下很可能是個小於10000的值。有人可能會說volatile不是保證了可見性啊,一個線程對race的修改,另外一個線程應該立刻看到啊!可是這裏的操作race++是個複合操作啊,包括讀取race的值,對其自增,然後再寫回主存。
假設線程A,讀取了race的值爲10,這時候被阻塞了,因爲沒有對變量進行修改,觸發不了volatile規則。
線程B此時也讀讀race的值,主存裏race的值依舊爲10,做自增,然後立刻就被寫回主存了,爲11。
此時又輪到線程A執行,由於工作內存裏保存的是10,所以繼續做自增,再寫回主存,11又被寫了一遍。所以雖然兩個線程執行了兩次increase(),結果卻只加了一次。
有人說,volatile不是會使緩存行無效的嗎?但是這裏線程A讀取到線程B也進行操作之前,並沒有修改inc值,所以線程B讀取的時候,還是讀的10。
又有人說,線程B將11寫回主存,不會把線程A的緩存行設爲無效嗎?但是線程A的讀取操作已經做過了啊,只有在做讀取操作時,發現自己緩存行無效,纔會去讀主存的值,所以這裏線程A只能繼續做自增了。
綜上所述,在這種複合操作的情景下,原子性的功能是維持不了了。但是volatile在上面那種設置flag值的例子裏,由於對flag的讀/寫操作都是單步的,所以還是能保證原子性的。
要想保證原子性,只能藉助於synchronized,Lock以及併發包下的atomic的原子操作類了,即對基本數據類型的 自增(加1操作),自減(減1操作)、以及加法操作(加一個數),減法操作(減一個數)進行了封裝,保證這些操作是原子性操作。
Java 理論與實踐: 正確使用 Volatile 變量 總結了volatile關鍵的使用場景,
只能在有限的一些情形下使用 volatile 變量替代鎖。要使 volatile 變量提供理想的線程安全,必須同時滿足下面兩個條件:
- 對變量的寫操作不依賴於當前值。
- 該變量沒有包含在具有其他變量的不變式中。
實際上,這些條件表明,可以被寫入 volatile 變量的這些有效值獨立於任何程序的狀態,包括變量的當前狀態。
第一個條件的限制使 volatile 變量不能用作線程安全計數器。雖然增量操作(x++)看上去類似一個單獨操作,實際上它是一個由讀取-修改-寫入操作序列組成的組合操作,必須以原子方式執行,而 volatile 不能提供必須的原子特性。實現正確的操作需要使x 的值在操作期間保持不變,而 volatile 變量無法實現這點。(然而,如果將值調整爲只從單個線程寫入,那麼可以忽略第一個條件。)
volatile一個使用場景是狀態位;還有隻有一個線程寫,其餘線程讀的場景
4.3 鎖的內存語義
鎖可以讓臨界區互斥執行。鎖的釋放-獲取的內存語義與volatile變量寫-讀的內存語義很像。
當線程釋放鎖時,JMM會把該線程對應的本地內存中的共享變量刷新到主內存中。
當線程獲取鎖時,JMM會把該線程對應的本地內存置位無效,從而使得被監視器保護的臨界區代碼必須從主內存中讀取共享變量。
不難發現:鎖釋放與volatile寫有相同的內存語音;鎖獲取與volatile讀有相同的內存語義。
下面對鎖釋放和鎖獲取的內存語義做個總結。
- 線程A釋放一個鎖,實質上是線程A向接下來將要獲取這個鎖的某個線程發出了(線程A對共享變量所做修改的)消息。
- 線程B獲取一個鎖,實質上是線程B接收了之前某個線程發出的(在釋放這個鎖之前對共享變量所做修改)的消息。
- 線程A釋放鎖,隨後線程B獲取這個鎖,這個過程實質上是線程A通過主內存向線程B發送消息。
4.4 final域的內存語義
與前面介紹的鎖和volatile想比,對final域的讀和寫更像是普通的變量訪問。
對於final域,編譯器和處理器要遵循兩個重排序規則:
1.在構造函數內對一個final域的寫入,與隨後把這個被構造對象的引用賦值給一個引用變量,這兩個操作之間不能重排序。
2.初次讀一個包含final域的對象的應用,與隨後初次讀這個final域,這兩個操作之間不能重排序
下面通過一個示例來分別說明這兩個規則:
<pre>public class FinalTest { int i;//普通變量
final int j; static FinalExample obj; public FinalExample(){
i = 1;
j = 2;
} public static void writer(){
obj = new FinalExample();
} public static void reader(){
FinalExample object = obj;//讀對象引用
int a = object.i; int b = object.j;
}
}</pre>
這裏假設一個線程A執行writer()方法,隨後另一個線程B執行reader()方法。下面我們通過這兩個線程的交互來說明這兩個規則。
寫final域的重排序規則禁止把final域的寫重排序到構造函數之外。這個規則的實現包含下面兩個方面。
1)JMM禁止編譯器把final域的寫重排序到構造函數之外。
2)編譯器會在final域的寫之後,構造函數return之前,插入一個StoreStore屏障。這個屏障禁止處理器把final域的寫重排序到構造函數之外。
現在讓我們分析writer方法,writer方法只包含一行代碼obj = new FinalTest();這行代碼包含兩個步驟:
1)構造一個FinalTest類型的對象
2)把這個對象的引用賦值給obj
假設線程B的讀對象引用與讀對象的成員域之間沒有重排序,下圖是一種可能的執行時序
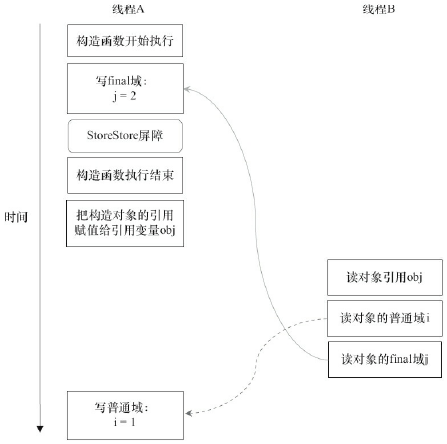
在上圖中,寫普通域的操作被編譯器重排序到了構造函數之外,讀線程B錯誤的讀取到了普通變量i初始化之前的值。而寫final域的操作被寫final域重排序的規則限定在了構造函數之內,讀線程B正確的讀取到了final變量初始化之後的值。
寫final域的重排序規則可以確保:在對象引用爲任意線程可見之前,對象的final域已經被初始化了,而普通變量不具有這個保證。以上圖爲例,讀線程B看到對象obj的時候,很可能obj對象還沒有構造完成(對普通域i的寫操作被重排序到構造函數外,此時初始值1還沒有寫入普通域i)
讀final域的重排序規則是:在一個線程中,初次讀對象的引用與初次讀這個對象包含的final域,JMM禁止重排序這兩個操作(該規則僅僅針對處理器)。編譯器會在讀final域的操作前面加一個LoadLoad屏障。
初次讀對象引用與初次讀該對象包含的final域,這兩個操作之間存在間接依賴關係。由於編譯器遵守間接依賴關係,因此編譯器不會重排序這兩個操作。大多數處理器也會遵守間接依賴,也不會重排序這兩個操作。但有少數處理器允許對存在間接依賴關係的操作做重排序(比如alpha處理器),這個規則就是專門用來針對這種處理器的。
上面的例子中,reader方法包含三個操作
1)初次讀引用變量obj
2)初次讀引用變量指向對象的普通域
3)初次讀引用變量指向對象的final域
現在假設寫線程A沒有發生任何重排序,同時程序在不遵守間接依賴的處理器上執行,下圖是一種可能的執行時序:
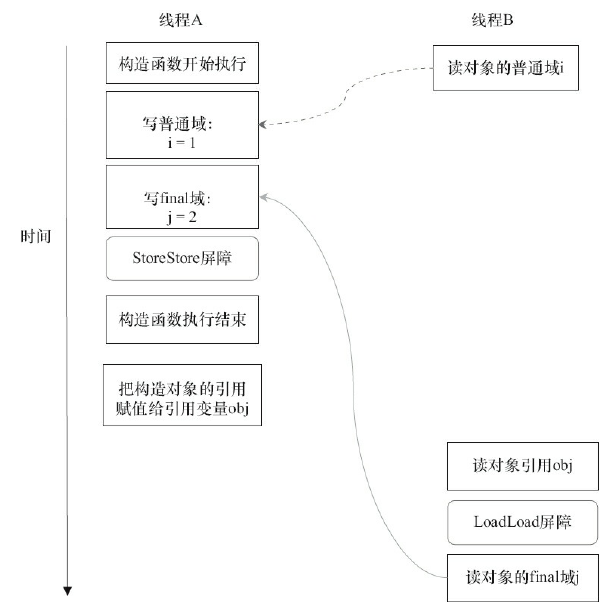
在上圖中,讀對象的普通域操作被處理器重排序到讀對象引用之前。在讀普通域時,該域還沒有被寫線程寫入,這是一個錯誤的讀取操作,而讀final域的重排序規則會把讀對象final域的操作“限定”在讀對象引用之後,此時該final域已經被A線程初始化過了,這是一個正確的讀取操作。
讀final域的重排序規則可以確保:在讀一個對象的final域之前,一定會先讀包含這個final域的對象的引用。在這個示例程序中,如果該引用不爲null,那麼引用對象的final域一定已經被A線程初始化過了。
final域爲引用類型,上面我們看到的final域是基礎的數據類型,如果final域是引用類型呢?
<pre>public class FinalReferenceTest { final int[] arrs;//final引用
static FinalReferenceTest obj; public FinalReferenceTest(){
arrs = new int[1];//1
arrs[0] = 1;//2} public static void write0(){//A線程
obj = new FinalReferenceTest();//3
} public static void write1(){//線程B
obj.arrs[0] = 2;//4
} public static void reader(){//C線程
if(obj!=null){//5
int temp =obj.arrs[0];//6
}
}
}</pre>
JMM可以確保讀線程C至少能看到寫線程A在構造函數中對final引用對象的成員域的寫入。即C至少能看到數組下標0的值爲1。而寫線程B對數組元素的寫入,讀線程C可能看得到,也可能看不到。JMM不保證線程B的寫入對讀線程C可見,因爲寫線程B和讀線程C之間存在數據競爭,此時的執行結果不可預知。
如果想要確保讀線程C看到寫線程B對數組元素的寫入,寫線程B和讀線程C之間需要使用同步原語(lock或volatile)來確保內存可見性。
前面我們提到過,寫final域的重排序規則可以確保:在引用變量爲任意線程可見之前,該引用變量指向的對象的final域已經在構造函數中被正確初始化過了。其實,要得到這個效果,還需要一個保證:在構造函數內部,不能讓這個被構造對象的引用爲其他線程所見,也就是對象引用不能在構造函數中“逸出”。
<pre>public class FinalReferenceEscapeExample {final int i;static FinalReferenceEscapeExample obj;public FinalReferenceEscapeExample () {
i = 1; // 1寫final域
obj = this; // 2 this引用在此"逸出"
}
public static void writer() {new FinalReferenceEscapeExample ();
}public static void reader() {if (obj != null) { // 3
int temp = obj.i; // 4
}
}
}</pre>
假設一個線程A執行writer()方法,另一個線程B執行reader()方法。這裏的操作2使得對象還未完成構造前就爲線程B可見。即使這裏的操作2是構造函數的最後一步,且在程序中操作2排在操作1後面,執行read()方法的線程仍然可能無法看到final域被初始化後的值,因爲這裏的操作1和操作2之間可能被重排序。
JSR-133爲什麼要增強final的語義:
通過爲final域增加寫和讀重排序規則,可以爲Java程序員提供初始化安全保證:只要對象是正確構造的(被構造對象的引用在構造函數中沒有“逸出”),那麼不需要使用同步(指lock和volatile的使用)就可以保證任意線程都能看到這個final域在構造函數中被初始化之後的值。
五、JMM是如何處理併發過程中的三大特性
JMM是圍繞這在併發過程中如何處理原子性、可見性和有序性這3個特性來建立的。
-
原子性:
Java中,對基本數據類型的讀取和賦值操作是原子性操作,所謂原子性操作就是指這些操作是不可中斷的,要做一定做完,要麼就沒有執行。比如:
i = 2;j = i;i++;i = i + 1;
上面4個操作中,i=2是讀取操作,必定是原子性操作,j=i你以爲是原子性操作,其實吧,分爲兩步,一是讀取i的值,然後再賦值給j,這就是2步操作了,稱不上原子操作,i++和i = i + 1其實是等效的,讀取i的值,加1,再寫回主存,那就是3步操作了。所以上面的舉例中,最後的值可能出現多種情況,就是因爲滿足不了原子性。
JMM只能保證對單個volatile變量的讀/寫具有原子性,但類似於volatile++這種符合操作不具有原子性,這時候就必須藉助於synchronized和Lock來保證整塊代碼的原子性了。線程在釋放鎖之前,必然會把i的值刷回到主存的。
-
可見性:可見性指當一個線程修改了共享變量的值,其他線程能夠立即得知這個修改。Java內存模型是通過在變量修改後將新值同步回主內存,在變量讀取前從主內存刷新變量值這種依賴主內存作爲傳遞媒介的方式來實現可見性。
-
無論是普通變量還是volatile變量,它們的區別是:volatile的特殊規則保證了新值能立即同步到主內存,以及每次使用前立即從主內存刷新。因爲,可以說volatile保證了多線程操作時變量的可見性,而普通變量不能保證這一點。
-
除了volatile之外,java中還有2個關鍵字能實現可見性,即synchronized和final(final修飾的變量,線程安全級別最高)。同步塊的可見性是由“對一個變量執行unlock操作之前,必須先把此變量同步回主內存中(執行store,write操作)”這條規則獲得;而final關鍵字的可見性是指:被final修飾的字段在構造器中一旦初始化完成,並且構造器沒有把“this”的引用傳遞出去(this引用逃逸是一件很危險的事,其他線程有可能通過這個引用訪問到“初始化了一半”的對象),那麼在其他線程中就能看到final字段的值。
-
有序性:JMM的有序性在講解volatile時詳細的討論過,java程序中天然的有序性可以總結爲一句話:如果在本線程內觀察,所有操作都是有序的;如果在一個線程中觀察另一個線程,所有操作都是無序的。前半句是指“線程內表現爲串行的語義”,後半句指的是“指令重排”現象和“工作內存與主內存同步延遲”現象。
- 前半句可以用JMM規定的as-if-serial語義來解決,後半句可以用JMM規定的happens-before原則來解決。Java語義提供了volatile和synchronized兩個關鍵字來保證線程之間操作的有序性,volatile關鍵字本身就包含了禁止指令重排的語義,而synchronized則是由“一個變量在同一個時刻只允許一條線程對其進行lock操作”這條規則獲取的。這個規則決定了持有同一個鎖的兩個同步塊只能串行的進入。
參考鏈接:
https://blog.csdn.net/javazejian/article/details/72772461#volatile%E7%A6%81%E6%AD%A2%E9%87%8D%E6%8E%92%E4%BC%98%E5%8C%96
https://www.cnblogs.com/_popc/p/6096517.html
https://blog.csdn.net/liu_dong_liang/article/details/80391040
https://www.jb51.net/article/76006.htm
https://blog.csdn.net/x_i_y_u_e/article/details/50728602
https://blog.csdn.net/FYGu18/article/details/79001688
https://blog.csdn.net/soongp/article/details/80292796
《Java 併發編程的藝術》 方騰飛 魏鵬 程曉明 著