




本人免費整理了Java高級資料,涵蓋了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高併發分佈式等教程,一共30G,需要自己領取。
傳送門:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
1.ConcurrentLinkedQueue簡介
在單線程編程中我們會經常用到一些集合類,比如ArrayList,HashMap等,但是這些類都不是線程安全的類。在面試中也經常會有一些考點,比如ArrayList不是線程安全的,Vector是線程安全。而保障Vector線程安全的方式,是非常粗暴的在方法上用synchronized獨佔鎖,將多線程執行變成串行化。要想將ArrayList變成線程安全的也可以使用Collections.synchronizedList(List<T> list)方法ArrayList轉換成線程安全的,但這種轉換方式依然是通過synchronized修飾方法實現的,很顯然這不是一種高效的方式,同時,隊列也是我們常用的一種數據結構,爲了解決線程安全的問題,Doug Lea大師爲我們準備了ConcurrentLinkedQueue這個線程安全的隊列。從類名就可以看的出來實現隊列的數據結構是鏈式。
1.1 Node
要想先學習ConcurrentLinkedQueue自然而然得先從它的節點類看起,明白它的底層數據結構。Node類的源碼爲:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
.......}Node節點主要包含了兩個域:一個是數據域item,另一個是next指針,用於指向下一個節點從而構成鏈式隊列。並且都是用volatile進行修飾的,以保證內存可見性。另外ConcurrentLinkedQueue含有這樣兩個成員變量:
private transient volatile Node<E> head;private transient volatile Node<E> tail;
說明ConcurrentLinkedQueue通過持有頭尾指針進行管理隊列。當我們調用無參構造器時,其源碼爲:
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);}head和tail指針會指向一個item域爲null的節點,此時ConcurrentLinkedQueue狀態如下圖所示:
如圖,head和tail指向同一個節點Node0,該節點item域爲null,next域爲null。

1.2 操作Node的幾個CAS操作
在隊列進行出隊入隊的時候免不了對節點需要進行操作,在多線程就很容易出現線程安全的問題。可以看出在處理器指令集能夠支持CMPXCHG指令後,在java源碼中涉及到併發處理都會使用CAS操作,那麼在ConcurrentLinkedQueue對Node的CAS操作有這樣幾個:
//更改Node中的數據域item
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);}//更改Node中的指針域nextvoid lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);}//更改Node中的指針域nextboolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);}可以看出這些方法實際上是通過調用UNSAFE實例的方法,UNSAFE爲sun.misc.Unsafe類,該類是hotspot底層方法,目前爲止瞭解即可,知道CAS的操作歸根結底是由該類提供就好。
2.offer方法
對一個隊列來說,插入滿足FIFO特性,插入元素總是在隊列最末尾的地方進行插入,而取(移除)元素總是從隊列的隊頭。所有要想能夠徹底弄懂ConcurrentLinkedQueue自然而然是從offer方法和poll方法開始。那麼爲了能夠理解offer方法,採用debug的方式來一行一行的看代碼走。另外,在看多線程的代碼時,可採用這樣的思維方式:
單個線程offer 多個線程offer 部分線程offer,部分線程poll ----offer的速度快於poll --------隊列長度會越來越長,由於offer節點總是在對隊列隊尾,而poll節點總是在隊列對頭,也就是說offer線程和poll線程兩者並無“交集”,也就是說兩類線程間並不會相互影響,這種情況站在相對速率的角度來看,也就是一個"單線程offer" ----offer的速度慢於poll --------poll的相對速率快於offer,也就是隊頭刪的速度要快於隊尾添加節點的速度,導致的結果就是隊列長度會越來越短,而offer線程和poll線程就會出現“交集”,即那一時刻就可以稱之爲offer線程和poll線程同時操作的節點爲 臨界點 ,且在該節點offer線程和poll線程必定相互影響。根據在臨界點時offer和poll發生的相對順序又可從兩個角度去思考:1. 執行順序爲offer-->poll-->offer,即表現爲當offer線程在Node1後插入Node2時,此時poll線程已經將Node1刪除,這種情況很顯然需要在offer方法中考慮; 2.執行順序可能爲:poll-->offer-->poll,即表現爲當poll線程準備刪除的節點爲null時(隊列爲空隊列),此時offer線程插入一個節點使得隊列變爲非空隊列
先看這麼一段代碼:
1\. ConcurrentLinkedQueue<Integer> queue = new ConcurrentLinkedQueue<>();2\. queue.offer(1);3\. queue.offer(2);
創建一個ConcurrentLinkedQueue實例,先offer 1,然後再offer 2。offer的源碼爲:
public boolean offer(E e) {1\. checkNotNull(e);2\. final Node<E> newNode = new Node<E>(e);3\. for (Node<E> t = tail, p = t;;) {4\. Node<E> q = p.next;5\. if (q == null) {6\. // p is last node7\. if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point // for e to become an element of this queue, // and for newNode to become "live".8\. if (p != t) // hop two nodes at a time9\. casTail(t, newNode); // Failure is OK.10\. return true;
}
// Lost CAS race to another thread; re-read next }11\. else if (p == q)
// We have fallen off list. If tail is unchanged, it // will also be off-list, in which case we need to // jump to head, from which all live nodes are always // reachable. Else the new tail is a better bet.12\. p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.13\. p = (p != t && t != (t = tail)) ? t : q;
}}單線程執行角度分析:
先從單線程執行的角度看起,分析offer 1的過程。第1行代碼會對是否爲null進行判斷,爲null的話就直接拋出空指針異常,第2行代碼將e包裝成一個Node類,第3行爲for循環,只有初始化條件沒有循環結束條件,這很符合CAS的“套路”,在循環體CAS操作成功會直接return返回,如果CAS操作失敗的話就在for循環中不斷重試直至成功。
這裏實例變量t被初始化爲tail,p被初始化爲t即tail。爲了方便下面的理解,p被認爲隊列真正的尾節點,tail不一定指向對象真正的尾節點,因爲在ConcurrentLinkedQueue中tail是被延遲更新的,具體原因我們慢慢來看。代碼走到第3行的時候,t和p都分別指向初始化時創建的item域爲null,next域爲null的Node0。
第4行變量q被賦值爲null,第5行if判斷爲true,在第7行使用casNext將插入的Node設置成當前隊列尾節點p的next節點,如果CAS操作失敗,此次循環結束在下次循環中進行重試。CAS操作成功走到第8行,此時p==t,if判斷爲false,直接return true返回。如果成功插入1的話,此時ConcurrentLinkedQueue的狀態如下圖所示:
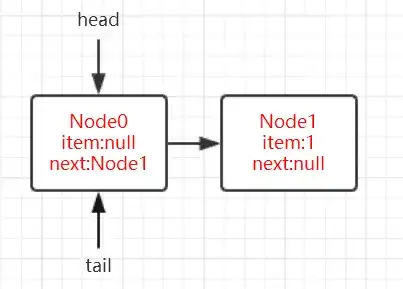
如圖,此時隊列的尾節點應該爲Node1,而tail指向的節點依然還是Node0,因此可以說明tail是延遲更新的。那麼我們繼續來看offer 2的時候的情況,很顯然此時第4行q指向的節點不爲null了,而是指向Node1,第5行if判斷爲false,第11行if判斷爲false,代碼會走到第13行。
好了,再插入節點的時候我們會問自己這樣一個問題?上面已經解釋了tail並不是指向隊列真正的尾節點,那麼在插入節點的時候,我們是不是應該最開始做的就是找到隊列當前的尾節點在哪裏才能插入?那麼第13行代碼就是找出隊列真正的尾節點。
定位隊列真正的對尾節點
p = (p != t && t != (t = tail)) ? t : q;
我們來分析一下這行代碼,如果這段代碼在單線程環境執行時,很顯然由於p==t,此時p會被賦值爲q,而q等於Node<E> q = p.next,即Node1。在第一次循環中指針p指向了隊列真正的隊尾節點Node1,那麼在下一次循環中第4行q指向的節點爲null,那麼在第5行中if判斷爲true,那麼在第7行依然通過casNext方法設置p節點的next爲當前新增的Node,接下來走到第8行,這個時候p!=t,第8行if判斷爲true,會通過casTail(t, newNode)將當前節點Node設置爲隊列的隊尾節點,此時的隊列狀態示意圖如下圖所示:
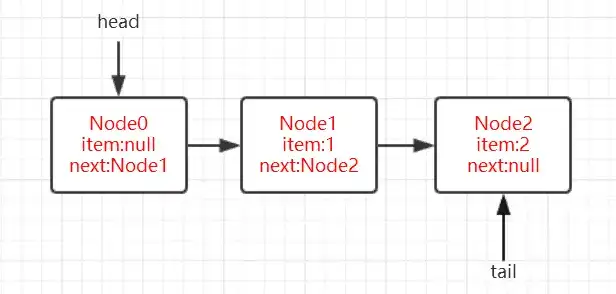
tail指向的節點由Node0改變爲Node2,這裏的casTail失敗不需要重試的原因是,offer代碼中主要是通過p的next節點q(Node<E> q = p.next)決定後面的邏輯走向的,當casTail失敗時狀態示意圖如下
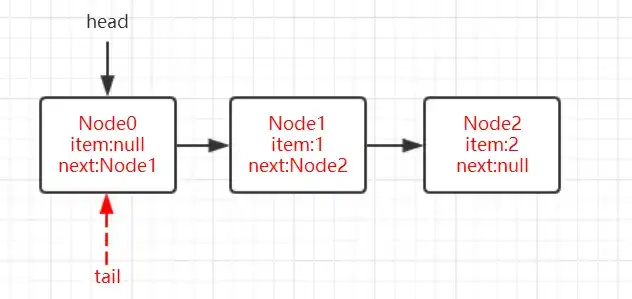
如圖,如果這裏casTail設置tail失敗即tail還是指向Node0節點的話,無非就是多循環幾次通過13行代碼定位到隊尾節點。
通過對單線程執行角度進行分析,我們可以瞭解到poll的執行邏輯爲:
如果tail指向的節點的下一個節點(next域)爲null的話,說明tail指向的節點即爲隊列真正的隊尾節點,因此可以通過casNext插入當前待插入的節點,但此時tail並未變化,如圖2;
如果tail指向的節點的下一個節點(next域)不爲null的話,說明tail指向的節點不是隊列的真正隊尾節點。通過
q(Node<E> q = p.next)指針往前遞進去找到隊尾節點,然後通過casNext插入當前待插入的節點,並通過casTail方式更改tail,如圖3。
我們回過頭再來看p = (p != t && t != (t = tail)) ? t : q;這行代碼在單線程中,這段代碼永遠不會將p賦值爲t,那麼這麼寫就不會有任何作用,那我們試着在多線程的情況下進行分析。
多線程執行角度分析
多個線程offer
很顯然這麼寫另有深意,其實在多線程環境下這行代碼很有意思的。 t != (t = tail)這個操作並非一個原子操作,有這樣一種情況:
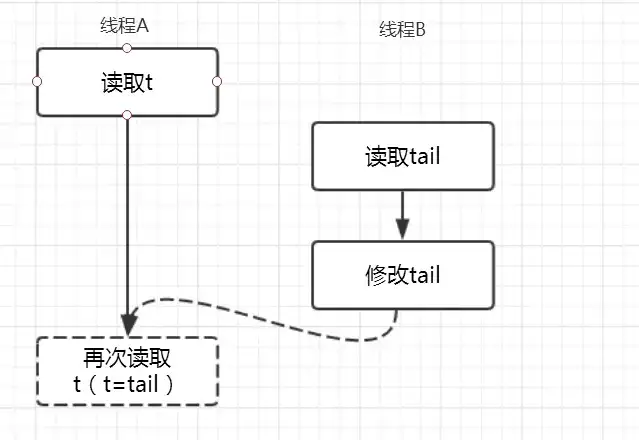
如圖,假設線程A此時讀取了變量t,線程B剛好在這個時候offer一個Node後,此時會修改tail指針,那麼這個時候線程A再次執行t=tail時t會指向另外一個節點,很顯然線程A前後兩次讀取的變量t指向的節點不相同,即t != (t = tail)爲true,並且由於t指向節點的變化p != t也爲true,此時該行代碼的執行結果爲p和t最新的t指針指向了同一個節點,並且此時t也是隊列真正的對尾節點。那麼,現在已經定位到隊列真正的隊尾節點,就可以執行offer操作了。
offer->poll->offer
那麼還剩下第11行的代碼我們沒有分析,大致可以猜想到應該就是回答一部分線程offer,一部分poll的這種情況。當if (p == q)爲true時,說明p指向的節點的next也指向它自己,這種節點稱之爲哨兵節點,這種節點在隊列中存在的價值不大,一般表示爲要刪除的節點或者是空節點。爲了能夠很好的理解這種情況,我們先看看poll方法的執行過程後,再回過頭來看,總之這是一個很有意思的事情 :)。
3.poll方法
poll方法源碼如下:
public E poll() { restartFromHead:
1\. for (;;) {
2\. for (Node<E> h = head, p = h, q;;) {
3\. E item = p.item;
4\. if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point // for item to be removed from this queue. 5\. if (p != h) // hop two nodes at a time 6\. updateHead(h, ((q = p.next) != null) ? q : p);
7\. return item;
}
8\. else if ((q = p.next) == null) {
9\. updateHead(h, p);
10\. return null;
}
11\. else if (p == q)
12\. continue restartFromHead;
else
13\. p = q;
}
}}我們還是先站在單線程的角度去理清該方法的基本邏輯。假設ConcurrentLinkedQueue初始狀態如下圖所示:
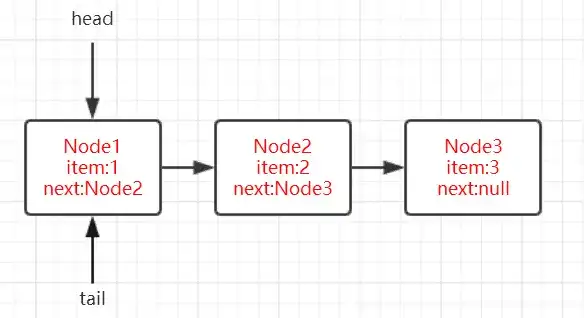
參數offer時的定義,我們還是先將變量p作爲隊列要刪除真正的隊頭節點,h(head)指向的節點並不一定是隊列的隊頭節點。先來看poll出Node1時的情況,由於p=h=head,參照上圖,很顯然此時p指向的Node1的數據域不爲null,在第4行代碼中item!=null判斷爲true後接下來通過casItem將Node1的數據域設置爲null。
如果CAS設置失敗則此次循環結束等待下一次循環進行重試。若第4行執行成功進入到第5行代碼,此時p和h都指向Node1,第5行if判斷爲false,然後直接到第7行return回Node1的數據域1,方法運行結束,此時的隊列狀態如下圖。

下面繼續從隊列中poll,很顯然當前h和p指向的Node1的數據域爲null,那麼第一件事就是要定位準備刪除的隊頭節點(找到數據域不爲null的節點)。
定位刪除的隊頭節點
繼續看,第三行代碼item爲null,第4行代碼if判斷爲false,走到第8行代碼(q = p.next)if也爲false,由於q指向了Node2,在第11行的if判斷也爲false,因此代碼走到了第13行,這個時候p和q共同指向了Node2,也就找到了要刪除的真正的隊頭節點。
可以總結出,定位待刪除的隊頭節點的過程爲:如果當前節點的數據域爲null,很顯然該節點不是待刪除的節點,就用當前節點的下一個節點去試探。在經過第一次循環後,此時狀態圖爲下圖:
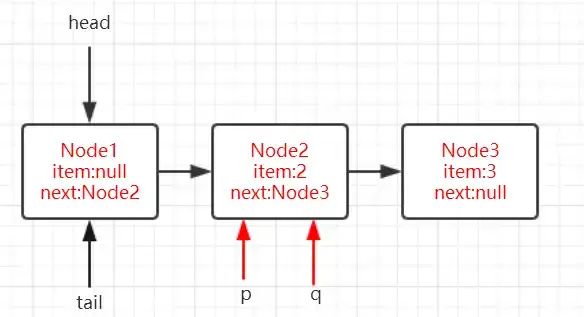
進行下一次循環,第4行的操作同上述,當前假設第4行中casItem設置成功,由於p已經指向了Node2,而h還依舊指向Node1,此時第5行的if判斷爲true,然後執行updateHead(h, ((q = p.next) != null) ? q : p),此時q指向的Node3,所有傳入updateHead方法的分別是指向Node1的h引用和指向Node3的q引用。updateHead方法的源碼爲:
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h);
}該方法主要是通過casHead將隊列的head指向Node3,並且通過 h.lazySetNext將Node1的next域指向它自己。最後在第7行代碼中返回Node2的值。此時隊列的狀態如下圖所示:

Node1的next域指向它自己,head指向了Node3。如果隊列爲空隊列的話,就會執行到代碼的第8行(q = p.next) == null,if判斷爲true,因此在第10行中直接返回null。以上的分析是從單線程執行的角度去看,也可以讓我們瞭解poll的整體思路,現在來做一個總結:
如果當前head,h和p指向的節點的Item不爲null的話,說明該節點即爲真正的隊頭節點(待刪除節點),只需要通過casItem方法將item域設置爲null,然後將原來的item直接返回即可。
如果當前head,h和p指向的節點的item爲null的話,則說明該節點不是真正的待刪除節點,那麼應該做的就是尋找item不爲null的節點。通過讓q指向p的下一個節點(q = p.next)進行試探,若找到則通過updateHead方法更新head指向的節點以及構造哨兵節點(
通過updateHead方法的h.lazySetNext(h))。
接下來,按照上面分析offer的思維方式,下面來分析一下多線程的情況,第一種情況是;
多線程執行情況分析:
多個線程poll
現在回過頭來看poll方法的源碼,有這樣一部分:
else if (p == q) continue restartFromHead;
這一部分就是處理多個線程poll的情況,q = p.next也就是說q永遠指向的是p的下一個節點,那麼什麼情況下會使得p,q指向同一個節點呢?根據上面我們的分析,只有p指向的節點在poll的時候轉變成了哨兵節點(通過updateHead方法中的h.lazySetNext)。
當線程A在判斷p==q時,線程B已經將執行完poll方法將p指向的節點轉換爲哨兵節點並且head指向的節點已經發生了改變,所以就需要從restartFromHead處執行,保證用到的是最新的head。
poll->offer->poll
試想,還有這樣一種情況,如果當前隊列爲空隊列,線程A進行poll操作,同時線程B執行offer,然後線程A在執行poll,那麼此時線程A返回的是null還是線程B剛插入的最新的那個節點呢?我們來寫一代demo:
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
Integer value = queue.poll();
System.out.println(Thread.currentThread().getName() + " poll 的值爲:" + value);
System.out.println("queue當前是否爲空隊列:" + queue.isEmpty());
});
thread1.start();
Thread thread2 = new Thread(() -> {
queue.offer(1);
});
thread2.start();
}輸出結果爲:
Thread-0 poll 的值爲:null queue當前是否爲空隊列:false
通過debug控制線程thread1和線程thread2的執行順序,thread1先執行到第8行代碼if ((q = p.next) == null),由於此時隊列爲空隊列if判斷爲true,進入if塊,此時先讓thread1暫停,然後thread2進行offer插入值爲1的節點後,thread2執行結束。再讓thread1執行,這時thread1並沒有進行重試,而是代碼繼續往下走,返回null,儘管此時隊列由於thread2已經插入了值爲1的新的節點。所以輸出結果爲thread0 poll的爲null,然隊列不爲空隊列。因此,在判斷隊列是否爲空隊列的時候是不能通過線程在poll的時候返回爲null進行判斷的,可以通過isEmpty方法進行判斷。
4. offer方法中部分線程offer部分線程poll
在分析offer方法的時候我們還留下了一個問題,即對offer方法中第11行代碼的理解。
offer->poll->offer
在offer方法的第11行代碼if (p == q),能夠讓if判斷爲true的情況爲p指向的節點爲哨兵節點,而什麼時候會構造哨兵節點呢?在對poll方法的討論中,我們已經找到了答案,即當head指向的節點的item域爲null時會尋找真正的隊頭節點,等到待插入的節點插入之後,會更新head,並且將原來head指向的節點設置爲哨兵節點。假設隊列初始狀態如下圖所示:
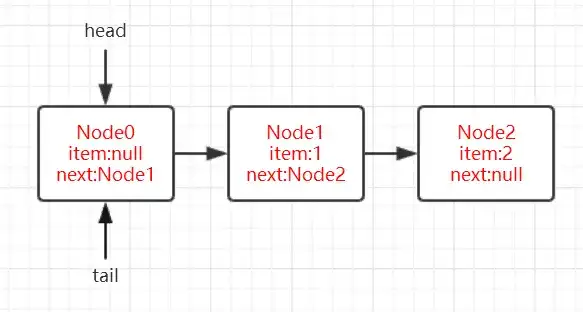
因此在線程A執行offer時,線程B執行poll就會存在如下一種情況:

如圖,線程A的tail節點存在next節點Node1,因此會通過引用q往前尋找隊列真正的隊尾節點,當執行到判斷if (p == q)時,此時線程B執行poll操作,在對線程B來說,head和p指向Node0,由於Node0的item域爲null,同樣會往前遞進找到隊列真正的隊頭節點Node1,在線程B執行完poll之後,Node0就會轉換爲哨兵節點,也就意味着隊列的head發生了改變,此時隊列狀態爲下圖。
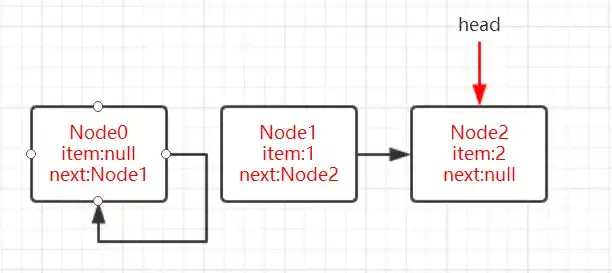
image.png
此時線程A在執行判斷if (p == q)時就爲true,會繼續執行p = (t != (t = tail)) ? t : head;,由於tail指針沒有發生改變所以p被賦值爲head,重新從head開始完成插入操作。
5. HOPS的設計
通過上面對offer和poll方法的分析,我們發現tail和head是延遲更新的,兩者更新觸發時機爲:
tail更新觸發時機:當tail指向的節點的下一個節點不爲null的時候,會執行定位隊列真正的隊尾節點的操作,找到隊尾節點後完成插入之後纔會通過casTail進行tail更新;當tail指向的節點的下一個節點爲null的時候,只插入節點不更新tail。
head更新觸發時機:當head指向的節點的item域爲null的時候,會執行定位隊列真正的隊頭節點的操作,找到隊頭節點後完成刪除之後纔會通過updateHead進行head更新;當head指向的節點的item域不爲null的時候,只刪除節點不更新head。
並且在更新操作時,源碼中會有註釋爲:hop two nodes at a time。所以這種延遲更新的策略就被叫做HOPS的大概原因是這個(猜的 :)),從上面更新時的狀態圖可以看出,head和tail的更新是“跳着的”即中間總是間隔了一個。那麼這樣設計的意圖是什麼呢?
如果讓tail永遠作爲隊列的隊尾節點,實現的代碼量會更少,而且邏輯更易懂。但是,這樣做有一個缺點,**如果大量的入隊操作,每次都要執行CAS進行tail的更新,彙總起來對性能也會是大大的損耗。如果能減少CAS更新的操作,無疑可以大大提升入隊的操作效率,所以doug lea大師每間隔1次(tail和隊尾節點的距離爲1)進行才利用CAS更新tail。
**對head的更新也是同樣的道理,雖然,這樣設計會多出在循環中定位隊尾節點,但總體來說讀的操作效率要遠遠高於寫的性能,因此,多出來的在循環中定位尾節點的操作的性能損耗相對而言是很小的。