




在前東家,我對於運維平臺重新做了二次的改造,當然基於zabbix平臺的功能也在不斷的完善,相對於之前的基礎架構,我們這次採用vue + element的前端架構,出圖使用的是echart的方式。後端我們使用了restful的標準通信框架。
自動化架構
1、當然在講到zabbix之前我們先看一下我們之前在老東家的時候做的相關的一些平臺操作:
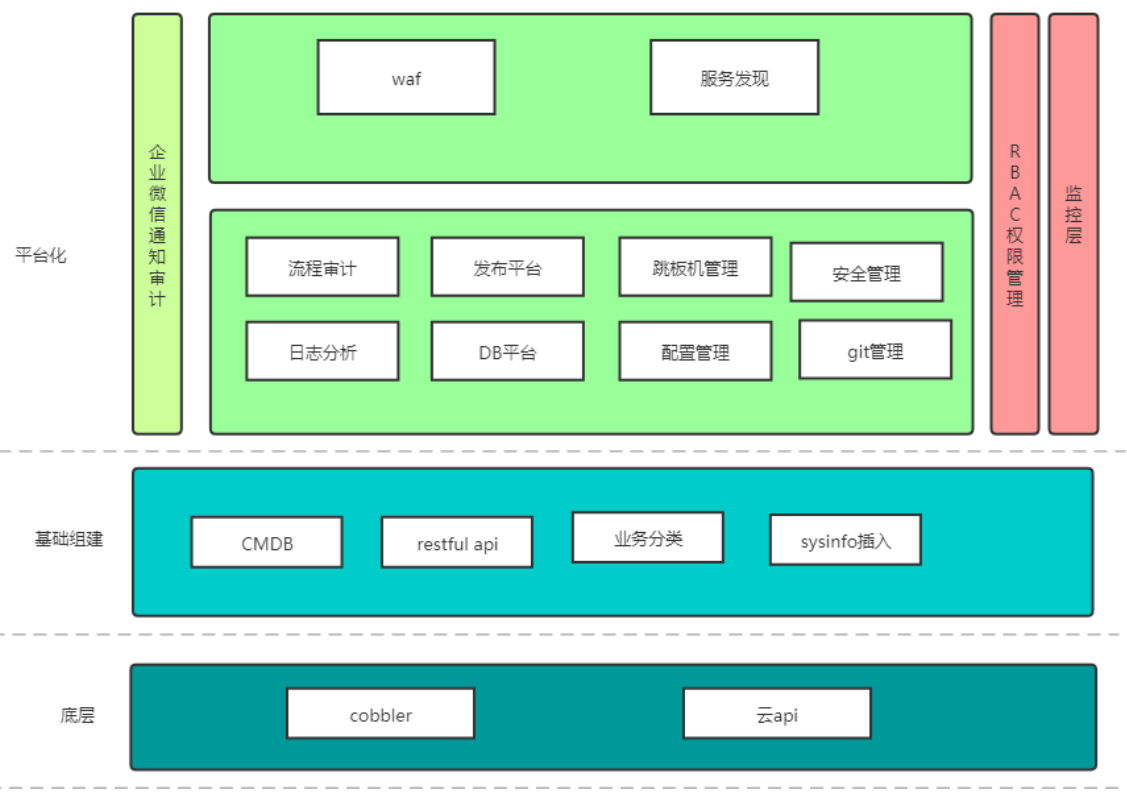
平臺相關注解:
- 底層的數據主要使用CMDB來進行管理,CMDB開放APi接口給上層的發佈系統、DB系統;當然各個子系統對接都是有權限審計。
- 數據錄入統一使用腳本進行採集,錄入cmdb數據庫,再由cmdb的開放接口,依次同步到我們的監控平臺。
- 流程審計和消息通知,主要事基於企業微信來進行操作。因爲公司使用的事企業微信,所以默認用戶對接到我們平臺,我們直接提取相關企業微信信息。
- 發佈平臺主要使用的是ansible 的一些api,支持直接的tar.gz文件發送,支持代碼上傳,並且打包編譯。
- DB平臺主要做數據的配置管理和審計。
- 跳板機使用jumpserver,非常好用,所以我們沒有自己開發。
2、下面我們看一下ansible 的一些相關流程:
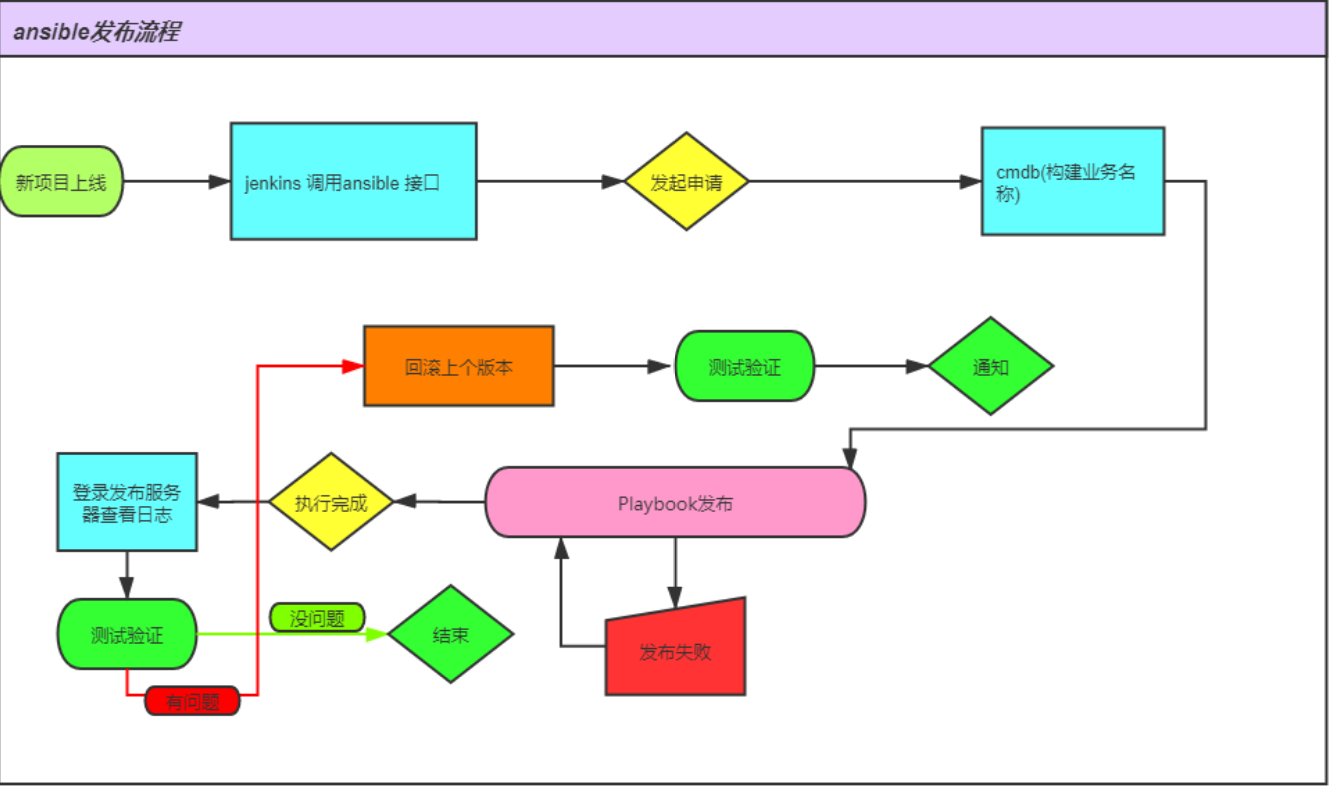
當然我們知道基於ansible 也好jenkins也好都是直接發佈的,爲什麼我們還要集成到平臺的,其實有兩個地方是我們在發佈的時候可以優化的:
- 直觀的web界面
- 添加相關的流程審計
- 發佈之後回滾快速方便
3、我們看下基於jenkins還可以做哪些事
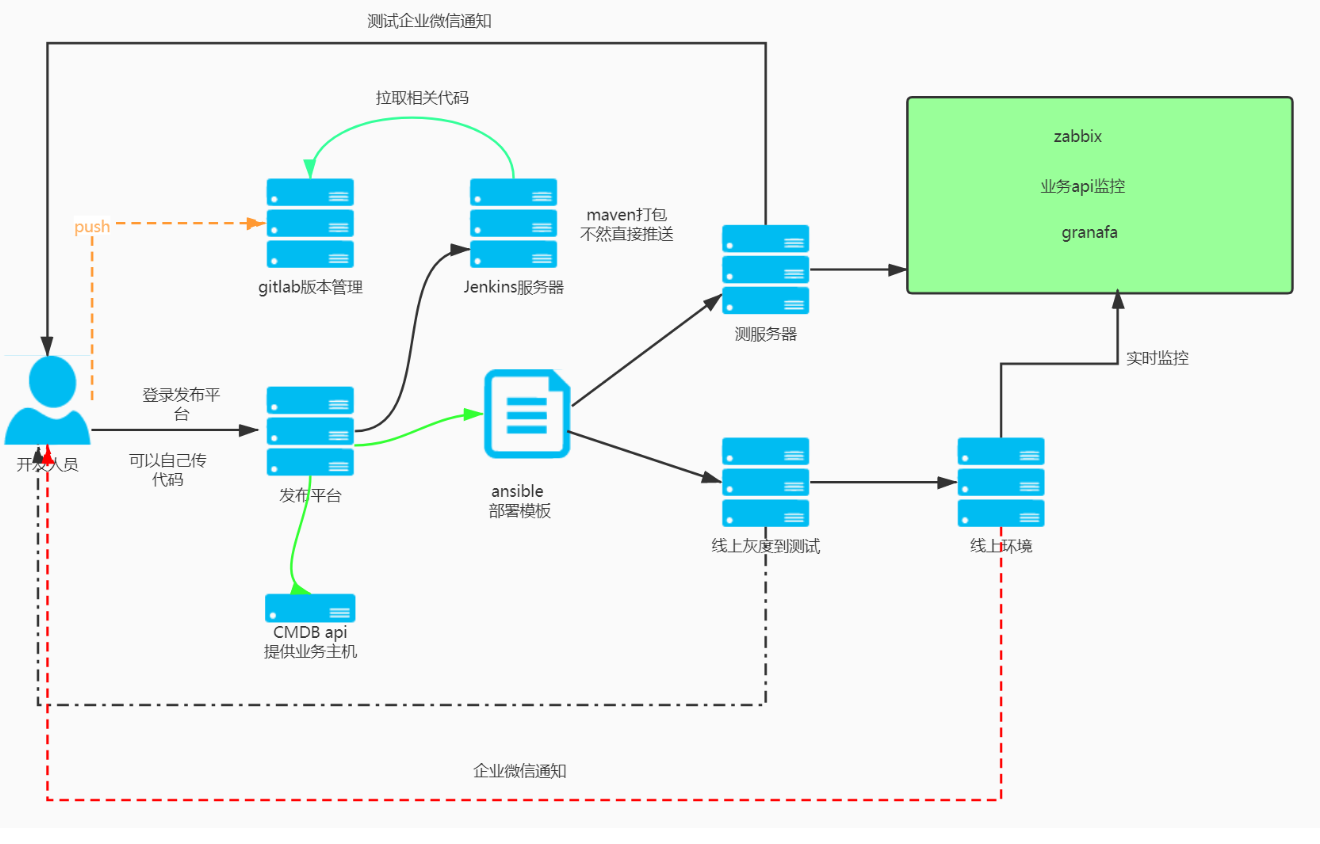
4、我們添加了相關的流程審計之後:

基於zabbix的相關自動化
1、基礎架構
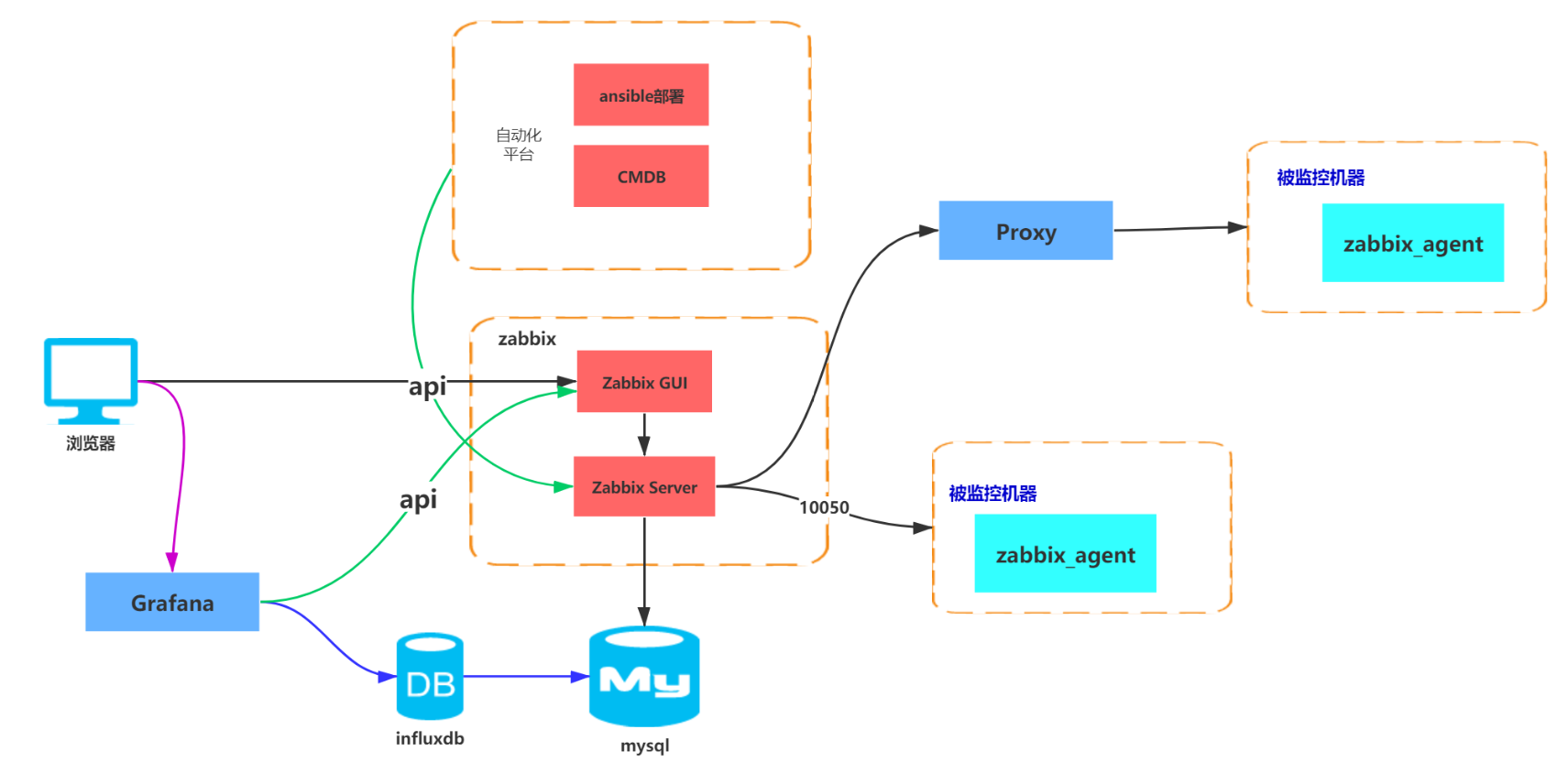
#註解
1、當我們需要大量部署zabbxi agent的時候,可以使用ansible playbook 來進行分組推送部署。
2、zabbix 數據從cmdb平臺獲取相關設備信息,並且綁定到相關模板。
3、前端使用vue + element + echart來進行出圖。
4、對於維護週期的管控,給故障設備添加維護,防止數據一直更新。
2、看下平臺關於添加zabbix主機的配置:
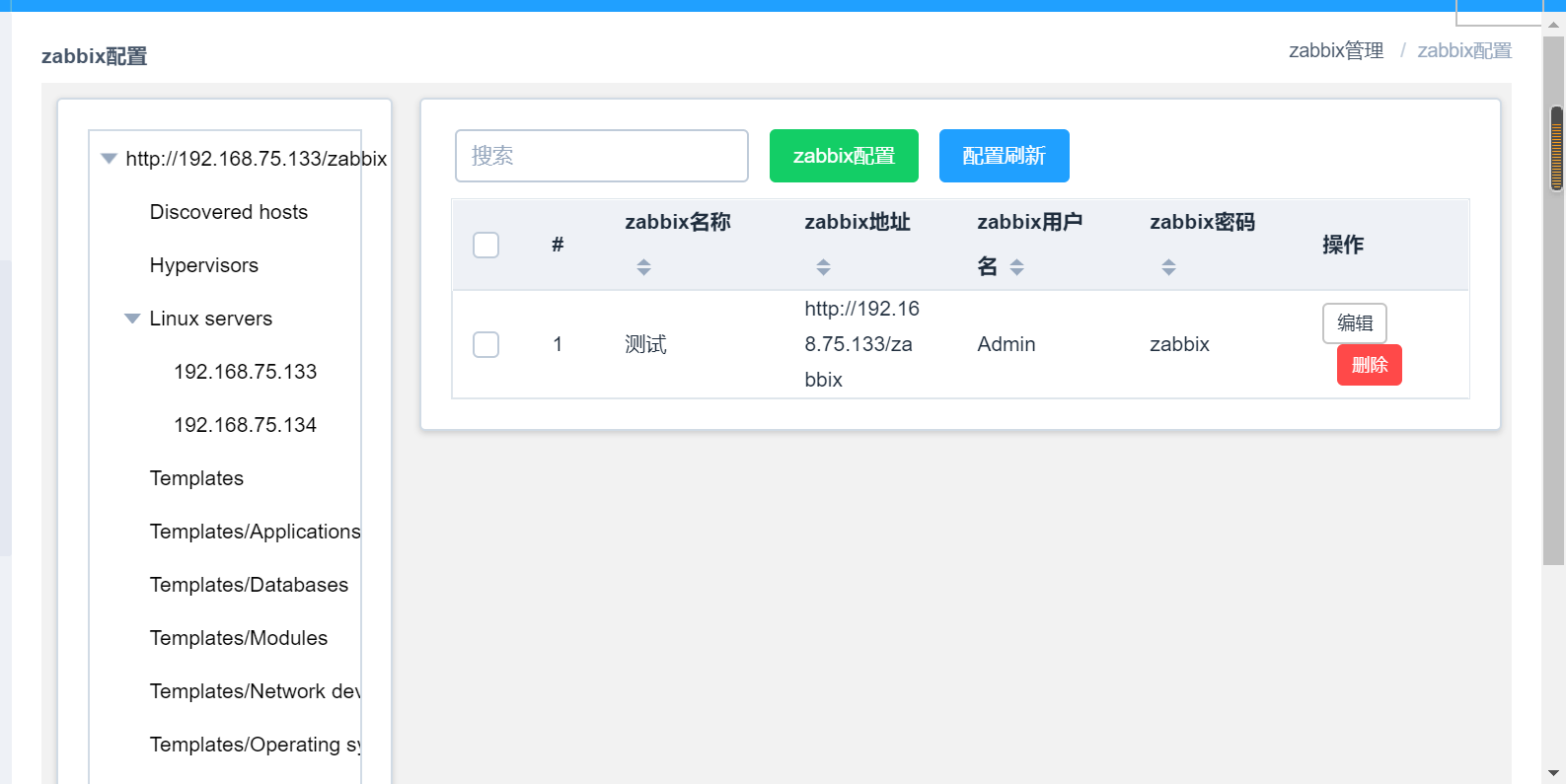
#這樣添加配置從數據庫讀取有個好處就是,我們可以隨機的更改我們的配置,添加成功刷新配置之後,可以獲取到相關的模板主機信息。
3、CMDB相關數據同步到zabbix:
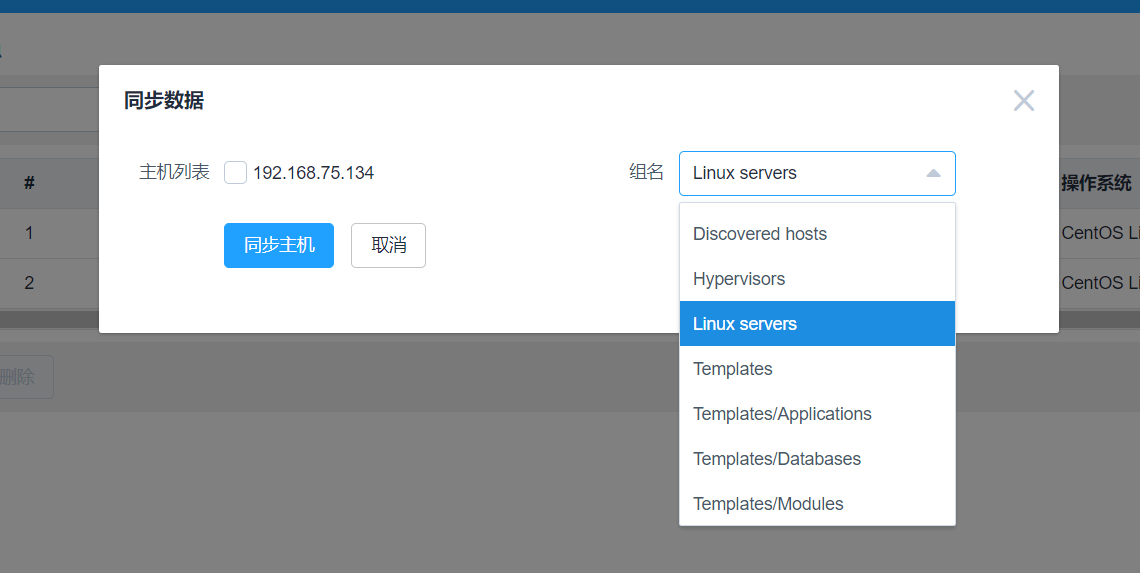
從cmdb裏面同步數據到相關的zabbix數據庫。可以判斷沒有同步過的主機回在左邊以列表的形式顯示出來,同步完成之後就沒有相關信息。
4、添加的主機進行模板綁定:
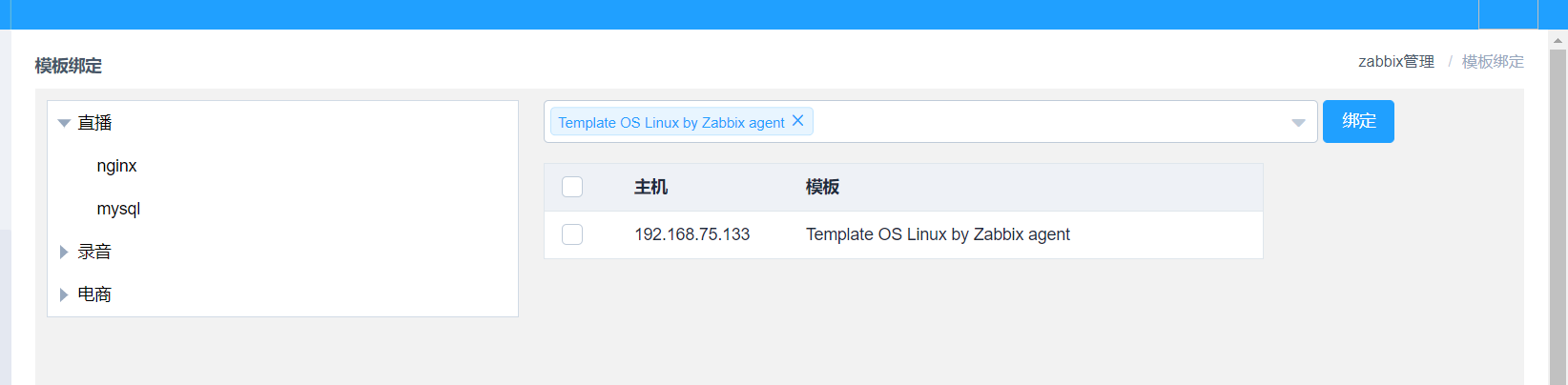
註釋:
1、我們已經對cmdb的主機進行了一個業務分組,所以我們會看到有一個層級的樹形業務結構
2、模板可以搜索多個,多個模板進行綁定。
5、給主機添加維護週期:
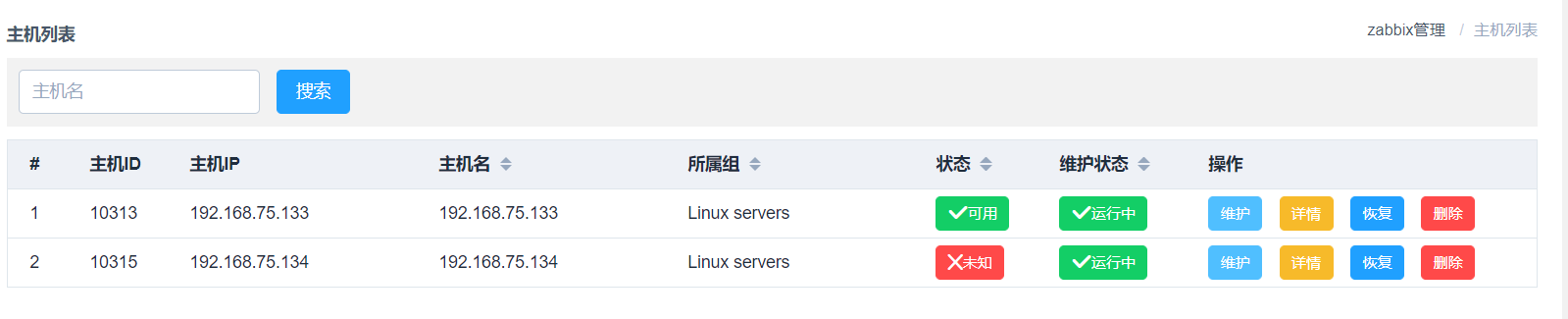
註釋:
當主機出現故障的時候,會發送大量的告警,所有有一個維護週期創建和刪除,可以幫我們省下不少活。
6、基於zabbix出圖:
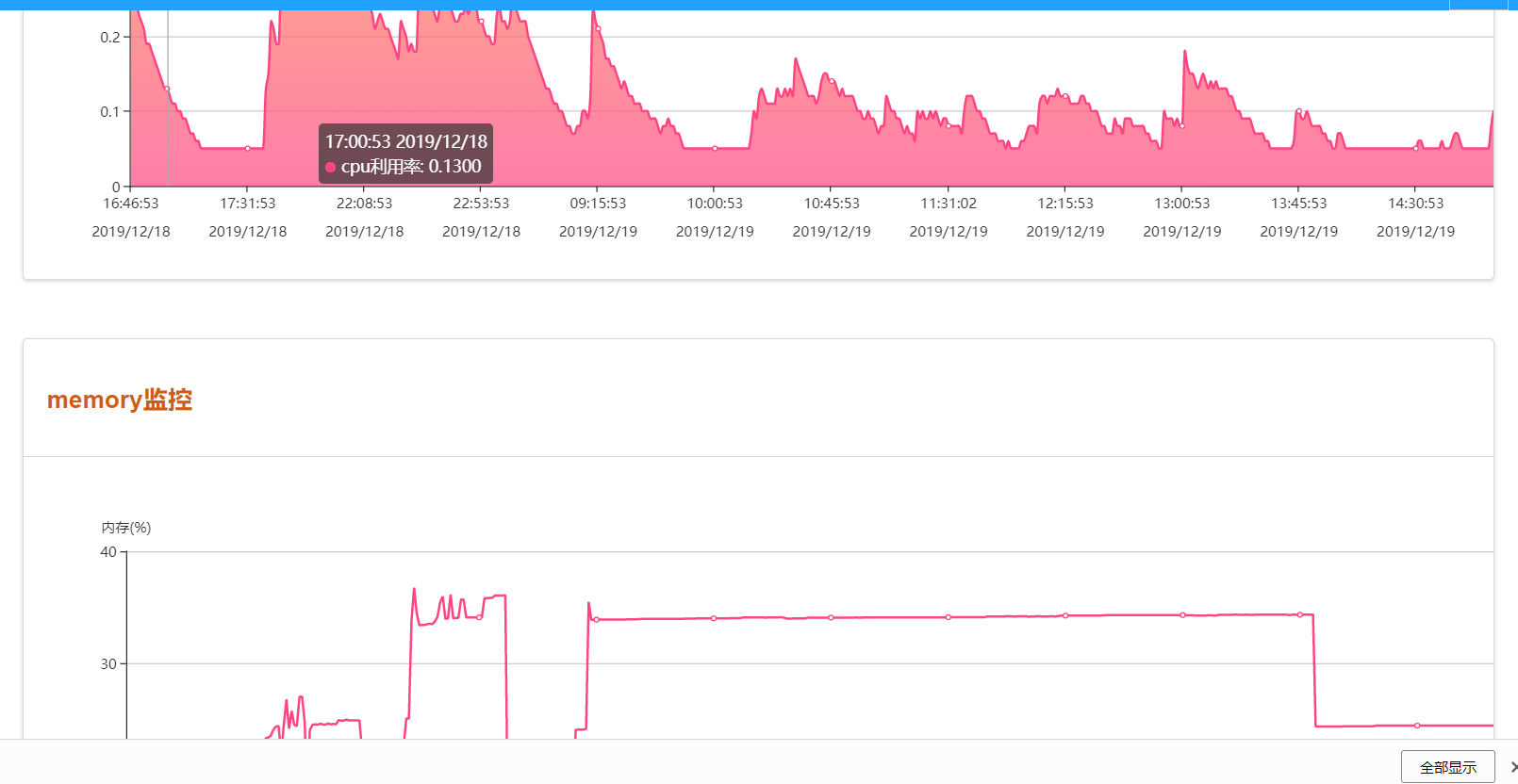
註釋:
這裏比較簡單,我們前端使用vue + echart的相關圖表,後端使用zabbix api 獲取的歷史數據,可以根據某臺主機點擊之後路由到相關圖表。
7、簡單看下前端的vue子組件代碼:
[root@localhost nav3]# cat Memory.vue
<template>
<div id="memory">
</div>
</template>
<script>
import echarts from 'echarts'
import moment from 'moment'
import { getMemory } from '../../api/api';
export default {
props: {
hostid: String
},
created() {
getMemory({hostid:this.hostid}).then((res) => {
const items = res.data;
let ydata = [];
let xdata = [];
items.forEach(function (item) {
xdata.push(item['clock']);
ydata.push(item['value']);
});
xdata = xdata.map(function (time) {
return moment(time * 1000).format('HH:mm:ss') + '\n\n' + moment(time * 1000).format('YYYY/MM/DD')
});
console.log(xdata)
const cpuChart = echarts.init(document.getElementById('memory'));
const option = {
title: {
text: ''
},
tooltip: {
trigger: 'axis'
},
legend: {
data: ['可用內存百分比']
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
xAxis: {
data: xdata,
},
yAxis: {
name:'內存(%)'
},
series: [
{
name: '可用內存',
type: 'line',
//smooth: true,
data: ydata,
//sampling: 'average',
itemStyle: {
normal: {
color: 'rgb(255,70,131)'
}
}
}
]
};
// 使用剛指定的配置項和數據顯示圖表。
cpuChart.setOption(option);
});
}
}
</script>
<style scoped="scoped">
#memory {
width: 1500px;
height: 500px;
}
</style>
7、後端restful 返回的json查詢:
class MemoryAPI(Resource):
decorators = [auth.login_required]
def get(self):
hostid = request.args.get('hostid')
res = zabbix.item.get(
hostids=[hostid],
output=["name",
"key_",
"value_type",
"hostid",
"status",
"state"],
filter={'key_': 'vm.memory.size[pavailable]'})
itemid = res[0]['itemid']
t_till = int(time.time())
t_from = t_till - 2 * 24 * 60 * 60
# 查詢cpu歷史數據
history = zabbix.history.get(
# hostids=[hostid],
itemids=[itemid],
history=0,
output='extend',
sortfield='clock',
sortorder='ASC',
time_from=t_from,
time_till=t_till)
json_dump = jsonify(history)
return json_dump雲平臺與微服務監控
最近在雲計算公司上班,在做雲平臺openstack、k8s和微服務的時候,我們也在面臨監控的選型問題,最終我們選擇的是prometheus,原因如下:
1、因爲k8s、微服務監控對象是動態可變的,無法進行固定的配置。
2、微服務之間調用接口是動態的,我們如何通過註冊中心去發現他們的調用,獲取請求指標,我們這邊是spring alibaba提醒。
3、當然像k8s主推的也是prometheus進行監控,動態的發現pod一些相關狀態。
4、社區很多exporter也是拿來就用的非常簡單,而且對接第三方接口也是很方便的。
5、當然是酷炫的granafa圖表了,基於prometheus監控的granafa社區非常多,基本上就是拿來就用的,所以滿足了我們出圖的需求。
簡單看下我們這邊的granafa相關圖表:
1、主機監控: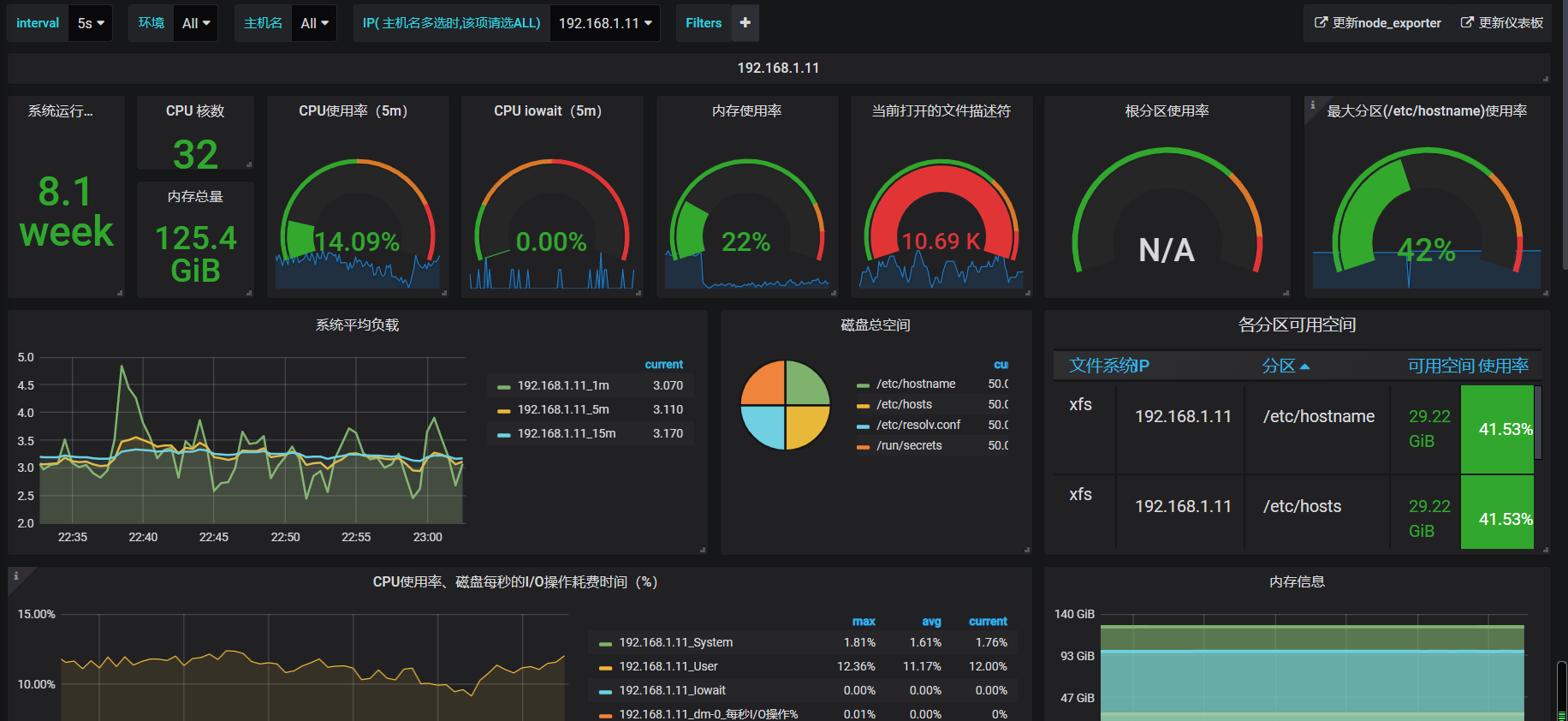
2、Docker容器狀態監控:
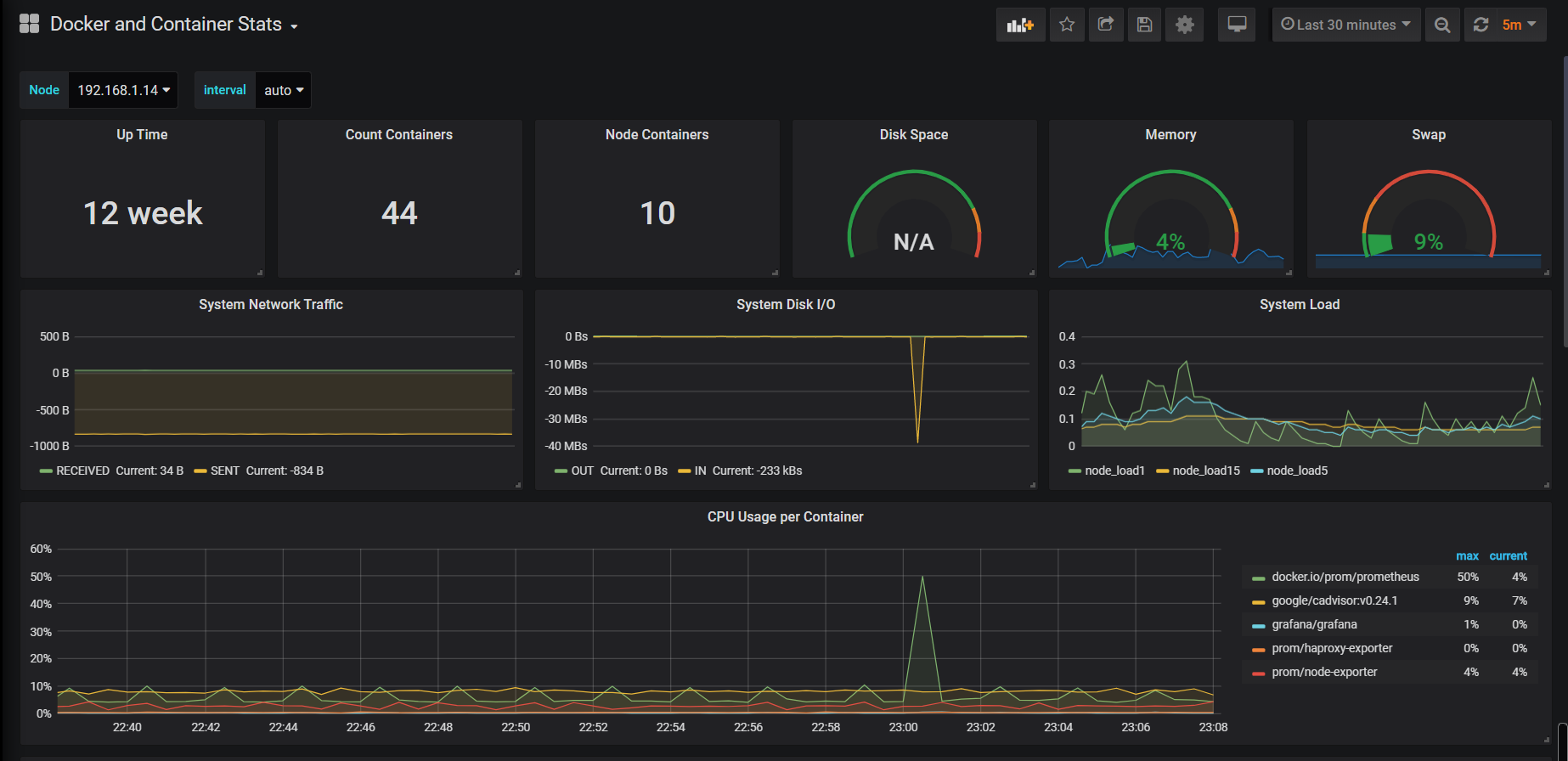
3、Ceph存儲: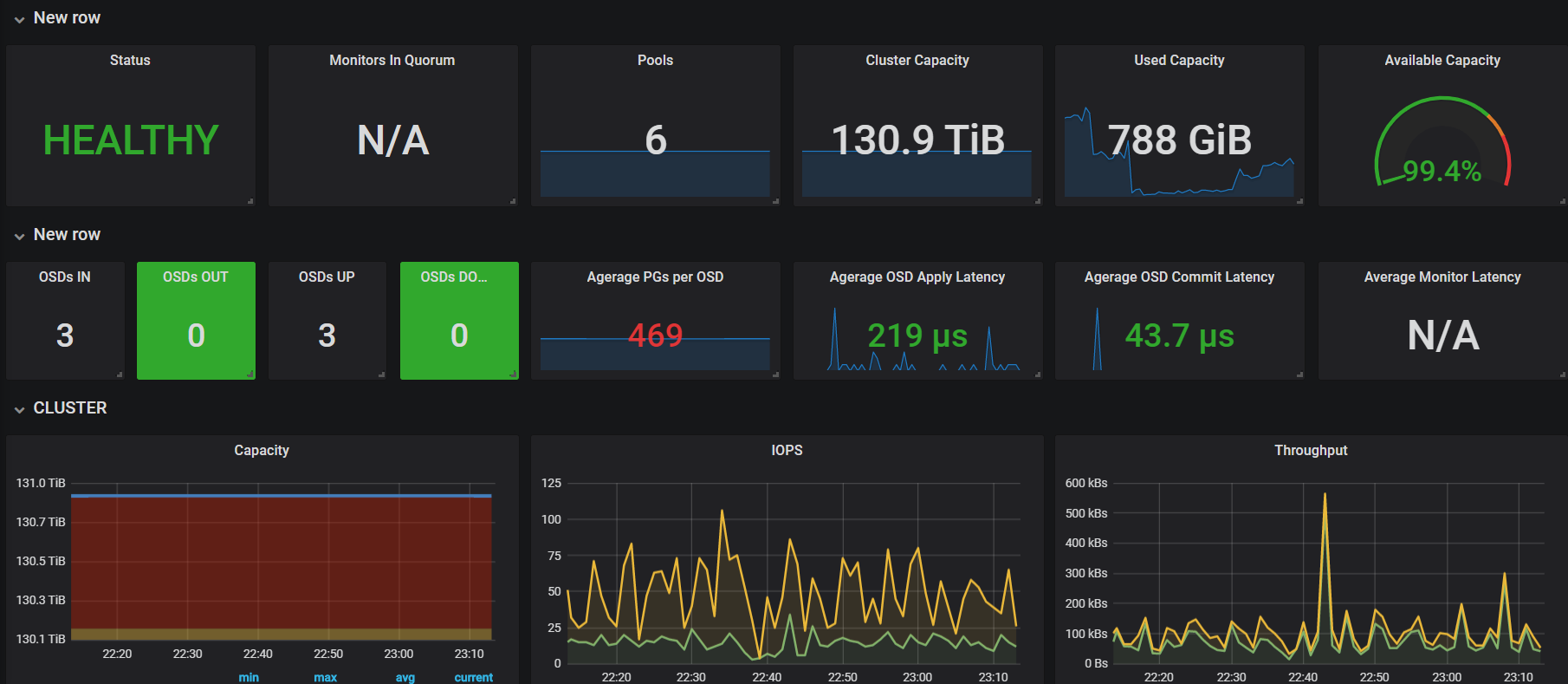
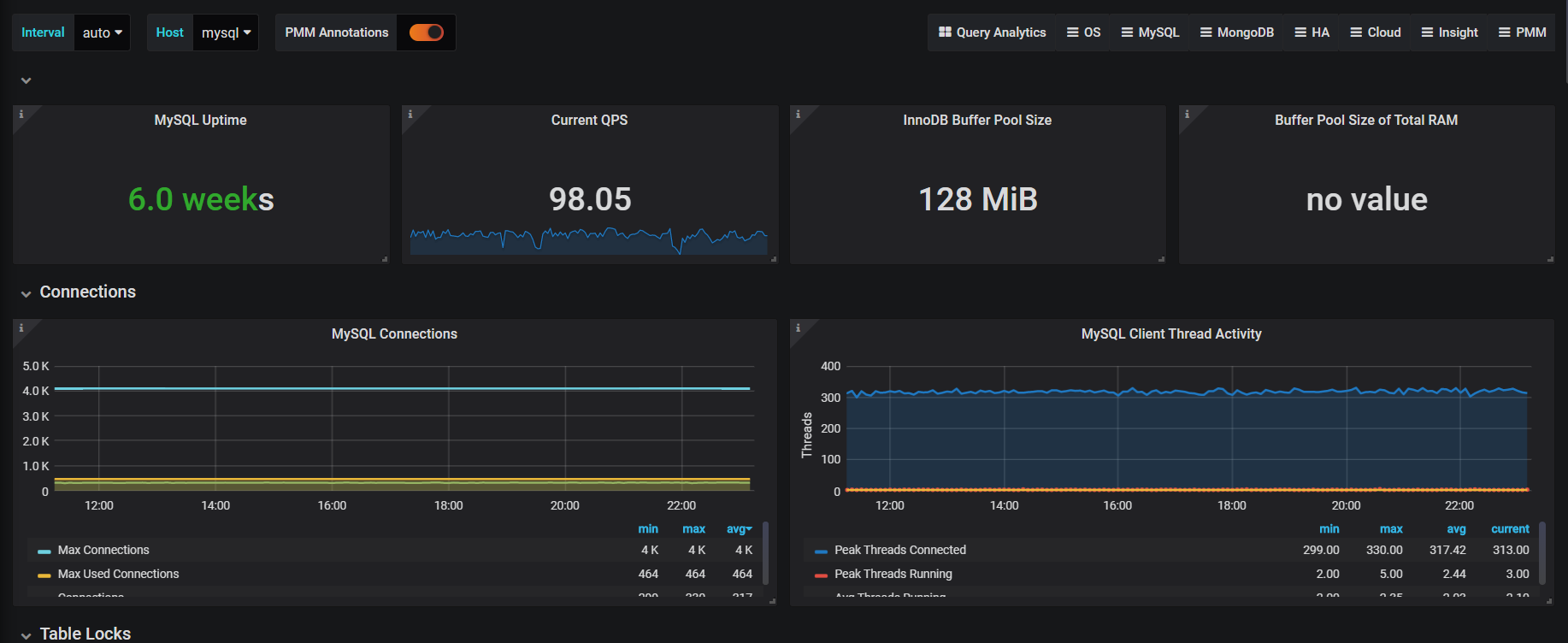
4、mysql
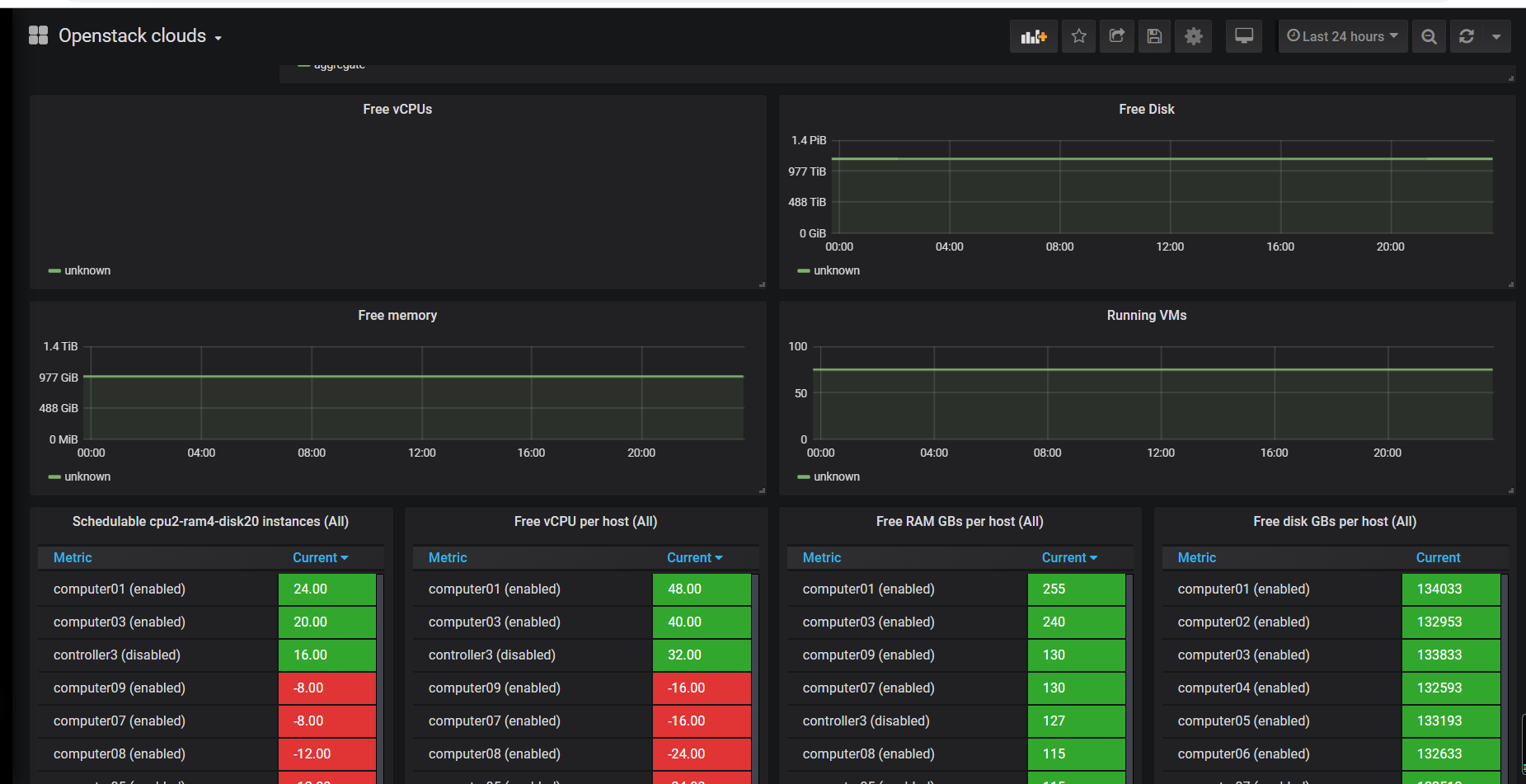
5、雲平臺:
總結
在我們企業構建平臺的時候,如何選型和思路是非常重要的。上面的只是我在生成過程當中實施和二次開發的工具,可以給大家提供一下參考。我們可以慢慢去拓寬我們的視野,完善我們自己的平臺。實現自動化也不是空談。最後送上個人的prometheus專欄地址:
https://blog.51cto.com/cloumn/detail/77