




博文大綱:
- 1、RANGE分區
- 2、LIST分區
- 3、HASH分區
- 4、key分區
- 5、MySQL分表和分區的區別
- 6、附加:如何實現將分區放在不同的目錄下進行存儲
MySQL分區類型如下:
- RANFGE分區
- LIST分區
- HASH分區
- key分區
上面的四種分區的條件必須是整形,如果不是整形需要通過函數將其轉換爲整形。
1、RANGE分區
RANGE分區是基於屬於一個給定連續區間的列值,把多行分配給分區。這些區間要連續且不能相互重疊,使用values less than操作符來進行定義。
創建一個RANGE分區方式的表:
mysql> create table employees (
-> id int not null,
-> fname varchar(30),
-> lname varchar(30),
-> hired date not null default '1970-01-01',
-> separated date not null default '9999-12-31',
-> job_code int not null,
-> store_id int not null
-> )
-> partition by range (store_id) (
-> partition p0 values less than (6),
-> partition p1 values less than (11),
-> partition p2 values less than (16),
-> partition p3 values less than (21)
-> );按照這種分區方案,當插入的記錄store_id小於6,會保存在p0這個分區,如果store_id小於11則會將數據保存在p1這個分區.....以此類推。但是在上面的分區方案中,定義的最後一個分區是小於21的,那麼,如果此時有store_id大於或等於21的記錄,則會插入失敗,因爲數據庫不知道應該插入到哪個分區中,避免這種情況的發生,就需要在指定分區方案或者新增一個分區,最後一個分區指定的範圍應該爲maxvalue,而不是一個具體的值。
根據上面創建的表,可以添加一個範圍爲maxvalue的分區,命令如下:
mysql> alter table employees add partition (partition p4 values less than maxvalue);如果最後一個分區指定的範圍是maxvalue,那麼後期想要添加分區的話,需要使用以下方式(使用類似於分區合併的指令):
mysql> alter table employees reorganize partition p4 into
-> ( partition p03 values less than (25),
-> partition p04 values less than maxvalue
-> );刪除分區的指令如下(注:當分區被刪除,那麼分區所存儲的數據也將被刪除,慎用!!!):
mysql> alter table employees drop partition p2;2、LIST分區
LIST分區類似於RANGE分區,區別在於LIST分區是基於列值匹配一個離散值集合中的某個值來進行選擇。LIST分區通過使用“partition by list(expr)”來實現,其中“expr”是某列值或一個基於某個列值、並返回一個整數值的表達式,然後通過“values in(value_list)”的方式來定義每個分區,其中“value_list”是一個通過逗號分隔的整數列表。
創建LIST分區類型舉例:
mysql> create table employees (
-> id int not null,
-> fname varchar(30),
-> lname varchar(30),
-> hired date not null default '1970-01-01',
-> separated date not null default '2100-12-31',
-> job_code int,
-> store_id int
-> )
-> partition by list(store_id)(
-> partition pNorth values in (3,5,6,9,17),
-> partition pEast values in (1,2,10,11,19,20),
-> partition pWest values in (4,12,13,14,18),
-> partition pCentral values in (7,8,15,16)
-> );
在上面創建的表中,如果插入一個store_id爲22(不在定義的分列表中)的數據,那麼將會插入失敗,如下:

失敗的原因就是:LIST分區沒有類似如“VALUES LESS THAN MAXVALUE”這樣的包含其他值在內的定義。將要匹配的任何值都
必須在值列表中找到。
解決辦法就是增加有這個值的分區,如下:
mysql> alter table employees add partition (partition p4 values ins (22,23,24));3、HASH分區
這種模式允許DBA通過對錶的一個或多個列的Hash Key進行計算,最後通過這個Hash碼不同數值對應的數據區域進行分區。 hash分區的目的是將數據均勻的分佈到預先定義的各個分區中,保證各分區的數據量大致一致。在range和list分區中,必須明確指定一個給定的列值或列值集合應該保存在哪個分區中;而在hash分區中,MySQL自動完成這些工作,用戶所要定一個列值或者表達式,以及指定被分區的表將要被分割成的分區數量。
1)創建hash分區的表
mysql> create table t_hash(a int(11),b datetime) partition by hash(year(b)) partitions 4;上述創建表的命令中,使用了year函數來提取b列中的年份來做分區的依據,通過partitions來指定需要4個分區。
2)插入測試數據
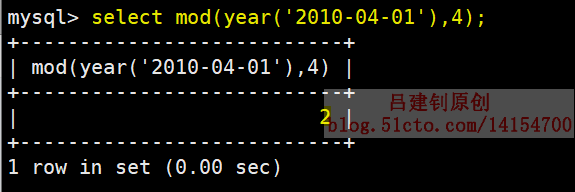
mysql> insert into t_hash values(1,'2010-04-01');上述指令插入的數據將被存放在p2分區,計算方法如下:
查看information_schema庫中的partitions也可以查看到p2分區中會有1條記錄,如下:
mysql> select * from information_schema.partitions where table_schema='test001' and table_name='t_hash'\G
返回結果如下:
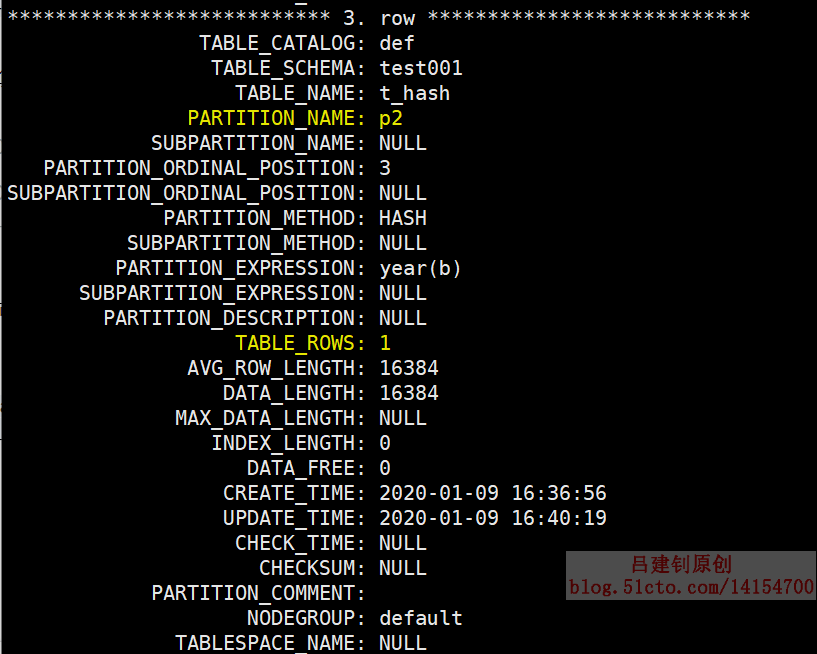
上面的例子並不能把數據均勻的分佈到各個分區,因爲按照YEAR函數進行的,該值本身是離散的。如果對連續的值進行HASH分區,如自增長的主鍵,則可以較好地將數據平均分佈。
4、key分區
key分區和hash分區相似,不同在於hash分區是用戶自定義函數進行分區,key分區使用mysql數據庫提供的函數進行分區,NDB cluster使用MD5函數來分區,對於其他存儲引擎mysql使用內部的hash函數。
創建一個key分區的表:
mysql> create table t_key(a int(11), b datetime) partition by key(b) partitions 4;如果後期需要新增分區,使用以下指令即可:
mysql> alter table t_key add partition partitions 5;上述指令是新增了5個分區,也就是說,現在t_key這個表一共有9個分區了。
注: mysql-5.5開始支持COLUMNS分區,可視爲RANGE和LIST分區的進化,COLUMNS分區可以直接使用非整形數據進行分區。COLUMNS分區支持以下數據類型: 所有整形,如INT SMALLINT
TINYINT BIGINT。FLOAT和DECIMAL則不支持。 日期類型,如DATE和DATETIME。其餘日期類型不支持。字符串類型,如CHAR、VARCHAR、BINARY和VARBINARY。BLOB和TEXT類型不支持。 COLUMNS可以使用多個列進行分區。
5、MySQL分表和分區的區別
1) 實現方式上
- mysql的分表是真正的分表,一張表分成很多表後,每一個小表都是完整的一張表,都對應三個文件,一個.MYD數據文件,.MYI索引文件,.frm表結構文件。
- 分區不一樣,一張大表進行分區後,它還是一張表,不會變成二張表,但是它存放數據的區塊變多了
2)數據處理上
- 分表後,數據都是存放在分表裏,總表只是一個外殼,存取數據發生在一個一個的分表裏面。
- 分區呢,不存在分表的概念,分區只不過把存放數據的文件分成了許多小塊,分區後的表呢,還是一張表,數據處理還是由自己來完成。
3)提高性能上
- 分表後,單表的併發能力提高了,磁盤I/O性能也提高了。因爲查尋一次所花的時間變短了,如果出現高併發的話,總表可以根據不同的查詢,將併發壓力分到不同的小表裏面。
- mysql提出了分區的概念,主要是想突破磁盤I/O瓶頸,想提高磁盤的讀寫能力,來增加mysql性能。
- 在這一點上,分區和分表的側重點不同,分表重點是存取數據時,如何提高mysql併發能力上;而分區呢,如何突破磁盤的讀寫能力,從而達到提高mysql性能的目的。
4)實現的難易度上
- 分表的方法有很多,用merge來分表,是最簡單的一種方式。這種方式跟分區難易度差不多,並且對程序代碼來說可以做到透明的。如果是用其他分表方式就比分區麻煩了。
- 分區實現是比較簡單的,建立分區表,和建平常的表沒什麼區別,並且對開代碼端來說是透明的。
5) 其他區別
- 都能提高mysql的性高,在高併發狀態下都有一個良好的表現。
- 分表和分區不矛盾,可以相互配合的,對於那些大訪問量,並且表數據比較多的表,我們可以採取分表和分區結合的方式,訪問量不大,但是表數據很多的表,我們可以採取分區的方式等。
- 分表技術是比較麻煩的,需要手動去創建子表,app服務端讀寫時候需要計算子表名。採用merge好一些,但也要創建子表和配置子表間的union關係。
- 表分區相對於分表,操作方便,不需要創建子表。
6、附加:如何實現將分區放在不同的目錄下進行存儲
先在本地創建好需要的目錄:
[root@mysql ~]# mkdir /data
[root@mysql ~]# chown -R mysql.mysql /data然後創建表時,指定data directory就可以,如下:
mysql> create table user(
-> id int not null auto_increment,
-> name varchar(30) not null default '',
-> primary key(id)) default charset=utf8 auto_increment=1
-> partition by range(id)(
-> partition p1 values less than (3) data directory '/data/area1',
-> partition p2 values less than (6) data directory '/data/area2',
-> partition p3 values less than (9) data directory '/data/area3');
查看本地目錄,則會發現自動創建了相應的存放數據的目錄,如下: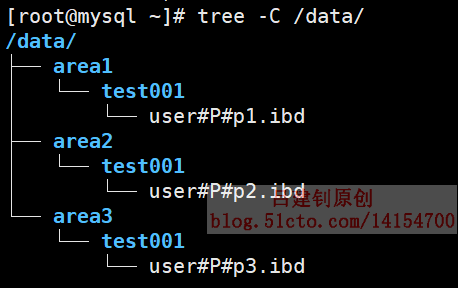
注:使用mysql默認的存儲引擎inodb時候,只需要指定data directory 就可以,因爲inodb的數據和索引在一個文件中。但是創建表格時指定engine=myisam時,修改分區的存儲位置,需要同時指定data directory和index directory。
———————— 本文至此結束,感謝閱讀 ————————