




** efk的搭建**Elasticsearch 是一個實時的、分佈式的可擴展的搜索引擎,允許進行全文、結構化搜索,它通常用於索引和搜索大量日誌數據,也可用於搜索許多不同類型的文檔。
Elasticsearch 通常與 Kibana 一起部署,Kibana 是 Elasticsearch 的一個功能強大的數據可視化 Dashboard,Kibana 允許你通過 web 界面來瀏覽 Elasticsearch 日誌數據。
Fluentd是一個流行的開源數據收集器,我們將在 Kubernetes 集羣節點上安裝 Fluentd,通過獲取容器日誌文件、過濾和轉換日誌數據,然後將數據傳遞到 Elasticsearch 集羣,在該集羣中對其進行索引和存儲。
我們先來配置啓動一個可擴展的 Elasticsearch 集羣,然後在 Kubernetes 集羣中創建一個 Kibana 應用,最後通過 DaemonSet 來運行 Fluentd,以便它在每個 Kubernetes 工作節點上都可以運行一個 Pod。
1.創建 Elasticsearch 集羣
在創建 Elasticsearch 集羣之前,我們先創建一個命名空間。
新建一個kube-efk.yaml

kubectl apply -f kube-efk.yaml
kubectl get ns 查看有沒有這個efk的命名空間
這裏我們使用3個 Elasticsearch Pod 來避免高可用下多節點集羣中出現的“腦裂”問題,當一個或多個節點無法與其他節點通信時會產生“腦裂”,可能會出現幾個主節點。
一個關鍵點是您應該設置參數discover.zen.minimum_master_nodes=N/2+1,其中N是 Elasticsearch 集羣中符合主節點的節點數,比如我們這裏3個節點,意味着N應該設置爲2。這樣,如果一個節點暫時與集羣斷開連接,則另外兩個節點可以選擇一個新的主節點,並且集羣可以在最後一個節點嘗試重新加入時繼續運行,在擴展 Elasticsearch 集羣時,一定要記住這個參數。
首先創建一個名爲 elasticsearch 的無頭服務,新建文件 elasticsearch-svc.yaml,文件內容如下:

定義了一個名爲 elasticsearch 的 Service,指定標籤app=elasticsearch,當我們將 Elasticsearch StatefulSet 與此服務關聯時,服務將返回帶有標籤app=elasticsearch的 Elasticsearch Pods 的 DNS A 記錄,然後設置clusterIP=None,將該服務設置成無頭服務。最後,我們分別定義端口9200、9300,分別用於與 REST API 交互,以及用於節點間通信。
然後我們創建這個無頭服務
kubectl apply -f elasticsearch-svc.yaml

現在我們已經爲 Pod 設置了無頭服務和一個穩定的域名.elasticsearch.logging.svc.cluster.local,接下來我們通過 StatefulSet 來創建具體的 Elasticsearch 的 Pod 應用。
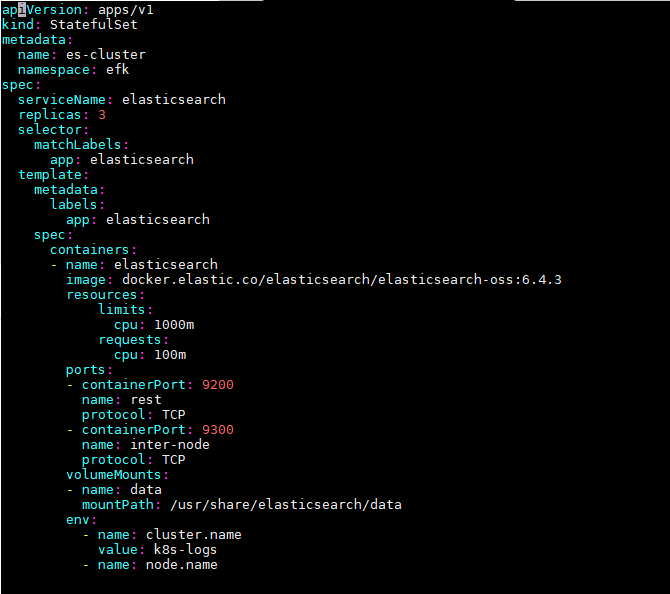
Kubernetes StatefulSet 允許我們爲 Pod 分配一個穩定的標識和持久化存儲,Elasticsearch 需要穩定的存儲來保證 Pod 在重新調度或者重啓後的數據依然不變,所以需要使用 StatefulSet 來管理 Pod。
我們使用了一個名爲 es-data-db 的 StorageClass 對象,所以我們需要提前創建該對象,我們這裏使用的 NFS 作爲存儲後端,所以需要安裝一個對應的 provisioner 驅動,
我們先創建elasticsearch-storageclass.yaml

然後我們創建pvc來對應這個storageclass
elasticsearch-pvc.yaml

最後我們創建這個statefulset
elasticsearch-statefulset.yaml


然後我們使用kubectl創建
kubectl apply -f elasticsearch-storageclass.yaml
kubectl apply -f elasticsearch-pvc.yaml
kubectl apply -f elasticsearch-statefulset.yaml
然後我們查看pod的運行情況

Pods 部署完成後,我們可以通過請求一個 REST API 來檢查 Elasticsearch 集羣是否正常運行。使用下面的命令將本地端口9200轉發到 Elasticsearch 節點(如es-cluster-0)對應的端口:

然後我們開另一個窗口

正常來說,應該會有這樣的信息。
看到上面的信息就表明我們名爲 k8s-logs 的 Elasticsearch 集羣成功創建了3個節點:es-cluster-0,es-cluster-1,和es-cluster-2,當前主節點是 es-cluster-0。
2.創建 Kibana 服務
Elasticsearch 集羣啓動成功了,接下來我們可以來部署 Kibana 服務,新建一個名爲 kibana.yaml 的文件,對應的文件內容如下:


上面我們定義了兩個資源對象,一個 Service 和 Deployment,爲了測試方便,我們將 Service 設置爲了 NodePort 類型,Kibana Pod 中配置都比較簡單,唯一需要注意的是我們使用 ELASTICSEARCH_URL 這個環境變量來設置Elasticsearch 集羣的端點和端口,直接使用 Kubernetes DNS 即可,此端點對應服務名稱爲 elasticsearch,由於是一個 headless service,所以該域將解析爲3個 Elasticsearch Pod 的 IP 地址列表。
然後我們創建這個服務
kubectl apply -f kibana.yaml

過了一會,我們的kibana的服務就起來了。
如果 Pod 已經是 Running 狀態了,證明應用已經部署成功了,然後可以通過 NodePort 來訪問 Kibana 這個服務,在瀏覽器中打開http://<任意節點IP>:30245即可,如果看到如下歡迎界面證明 Kibana 已經成功部署到了 Kubernetes集羣之中。

3.部署 Fluentd
Fluentd 是一個高效的日誌聚合器,是用 Ruby 編寫的,並且可以很好地擴展。對於大部分企業來說,Fluentd 足夠高效並且消耗的資源相對較少,另外一個工具Fluent-bit更輕量級,佔用資源更少,但是插件相對 Fluentd 來說不夠豐富,所以整體來說,Fluentd 更加成熟,使用更加廣泛,所以我們這裏也同樣使用 Fluentd 來作爲日誌收集工具。
工作原理
Fluentd 通過一組給定的數據源抓取日誌數據,處理後(轉換成結構化的數據格式)將它們轉發給其他服務,比如 Elasticsearch、對象存儲等等。Fluentd 支持超過300個日誌存儲和分析服務,所以在這方面是非常靈活的。主要運行步驟如下:
首先 Fluentd 從多個日誌源獲取數據
結構化並且標記這些數據
然後根據匹配的標籤將數據發送到多個目標服務去

日誌源配置
比如我們這裏爲了收集 Kubernetes 節點上的所有容器日誌,就需要做如下的日誌源配置:

路由配置
上面是日誌源的配置,接下來看看如何將日誌數據發送到 Elasticsearch:


match:標識一個目標標籤,後面是一個匹配日誌源的正則表達式,我們這裏想要捕獲所有的日誌並將它們發送給 Elasticsearch,所以需要配置成**。
id:目標的一個唯一標識符。
type:支持的輸出插件標識符,我們這裏要輸出到 Elasticsearch,所以配置成 elasticsearch,這是 Fluentd 的一個內置插件。
log_level:指定要捕獲的日誌級別,我們這裏配置成info,表示任何該級別或者該級別以上(INFO、WARNING、ERROR)的日誌都將被路由到 Elsasticsearch。
host/port:定義 Elasticsearch 的地址,也可以配置認證信息,我們的 Elasticsearch 不需要認證,所以這裏直接指定 host 和 port 即可。
logstash_format:Elasticsearch 服務對日誌數據構建反向索引進行搜索,將 logstash_format 設置爲true,Fluentd 將會以 logstash 格式來轉發結構化的日誌數據。
Buffer: Fluentd 允許在目標不可用時進行緩存,比如,如果網絡出現故障或者 Elasticsearch 不可用的時候。緩衝區配置也有助於降低磁盤的 IO。
4.安裝
要收集 Kubernetes 集羣的日誌,直接用 DasemonSet 控制器來部署 Fluentd 應用,這樣,它就可以從 Kubernetes 節點上採集日誌,確保在集羣中的每個節點上始終運行一個 Fluentd 容器。當然可以直接使用 Helm 來進行一鍵安裝,爲了能夠了解更多實現細節,我們這裏還是採用手動方法來進行安裝。
首先,我們通過 ConfigMap 對象來指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件,文件內容如下:


上面配置文件中我們配置了 docker 容器日誌目錄以及 docker、kubelet 應用的日誌的收集,收集到數據經過處理後發送到 elasticsearch:9200 服務。
然後新建一個 fluentd-daemonset.yaml 的文件,文件內容如下:




我們將上面創建的 fluentd-config 這個 ConfigMap 對象通過 volumes 掛載到了 Fluentd 容器中,另外爲了能夠靈活控制哪些節點的日誌可以被收集,所以我們這裏還添加了一個 nodSelector 屬性:
另外由於我們的集羣使用的是 kubeadm 搭建的,默認情況下 master 節點有污點,所以要想也收集 master 節點的日誌,則需要添加上容忍:

然後我們創建上面的configmap對象和daemonset服務


我們查看可以看到pod已經正常運行了。
然後我們進入kibana的頁面,點擊discover

在這裏可以配置我們需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我們採集的日誌使用的是 logstash 格式,這裏只需要在文本框中輸入logstash-*即可匹配到 Elasticsearch 集羣中的所有日誌數據,然後點擊下一步,進入以下頁面:

在該頁面中配置使用哪個字段按時間過濾日誌數據,在下拉列表中,選擇@timestamp字段,然後點擊Create index pattern,創建完成後,點擊左側導航菜單中的Discover,然後就可以看到一些直方圖和最近採集到的日誌數據了:
