




本文將由淺入深詳細介紹Java內存分配的原理,以幫助新手更輕鬆的學習Java。這類文章網上有很多,但大多比較零碎。本文從認知過程角度出發,將帶給讀者一個系統的介紹。
進入正題前首先要知道的是Java程序運行在JVM(Java Virtual Machine,Java虛擬機)上,可以把JVM理解成Java程序和操作系統之間的橋樑,JVM實現了Java的平臺無關性,由此可見JVM的重要 性。所以在學習Java內存分配原理的時候一定要牢記這一切都是在JVM中進行的,JVM是內存分配原理的基礎與前提。
簡單通俗的講,一個完整的Java程序運行過程會涉及以下內存區域:
l 寄存器:JVM內部虛擬寄存器,存取速度非常快,程序不可控制。
l 棧:保存局部變量的值,包括:1.用來保存基本數據類型的值;2.保存類的實例,即堆區對象的引用(指針)。也可以用來保存加載方法時的幀。
l 堆:用來存放動態產生的數據,比如new出來的對象。注意創建出來的對象只包含屬於各自的成員變量,並不包括成員方法。因爲同一個類的對象擁有各自的成員變量,存儲在各自的堆中,但是他們共享該類的方法,並不是每創建一個對象就把成員方法複製一次。
l 常量池:JVM爲每個已加載的類型維護一個常量池,常量池就是這個類型用到的常量的一個有序集合。包括直接常量(基本類型,String)和對其他類型、方法、字段的符號引用(1)。池中的數據和數組一樣通過索引訪問。由於常量池包含了一個類型所有的對其他類型、方法、字段的符號引用,所以常量池在Java的動態鏈接中起了核心作用。常量池存在於堆中。
l 代碼段:用來存放從硬盤上讀取的源程序代碼。
l 數據段:用來存放static定義的靜態成員。
下面是內存表示圖:

上圖中大致描述了Java內存分配,接下來通過實例詳細講解Java程序是如何在內存中運行的(注:以下圖片引用自尚學堂馬士兵老師的J2SE課件,圖右側是程序代碼,左側是內存分配示意圖,我會一一加上註釋)。
預備知識:
1.一個Java文件,只要有main入口方法,我們就認爲這是一個Java程序,可以單獨編譯運行。
2.無論是普通類型的變量還是引用類型的變量(俗 稱實例),都可以作爲局部變量,他們都可以出現在棧中。只不過普通類型的變量在棧中直接保存它所對應的值,而引用類型的變量保存的是一個指向堆區的指針, 通過這個指針,就可以找到這個實例在堆區對應的對象。因此,普通類型變量只在棧區佔用一塊內存,而引用類型變量要在棧區和堆區各佔一塊內存。
示例:

1.JVM自動尋找main方法,執行第一句代碼,創建一個Test類的實例,在棧中分配一塊內存,存放一個指向堆區對象的指針110925。
2.創建一個int型的變量date,由於是基本類型,直接在棧中存放date對應的值9。
3.創建兩個BirthDate類的實例d1、d2,在棧中分別存放了對應的指針指向各自的對象。他們在實例化時調用了有參數的構造方法,因此對象中有自定義初始值。
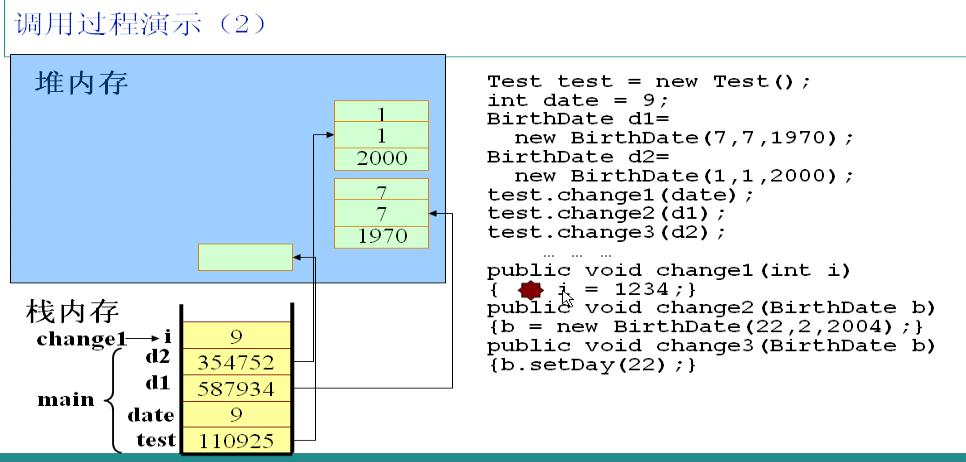
調用test對象的change1方法,並且以date爲參數。JVM讀到這段代碼時,檢測到i是局部變量,因此會把i放在棧中,並且把date的值賦給i。

把1234賦給i。很簡單的一步。

change1方法執行完畢,立即釋放局部變量i所佔用的棧空間。

調用test對象的change2方法,以實例d1爲參數。JVM檢測到change2方法中的b參數爲局部變量,立即加入到棧中,由於是引用類型的變量,所以b中保存的是d1中的指針,此時b和d1指向同一個堆中的對象。在b和d1之間傳遞是指針。

change2方法中又實例化了一個BirthDate對象,並且賦給b。在內部執行過程是:在堆區new了一個對象,並且把該對象的指針保存在棧中的b對應空間,此時實例b不再指向實例d1所指向的對象,但是實例d1所指向的對象並無變化,這樣無法對d1造成任何影響。

change2方法執行完畢,立即釋放局部引用變量b所佔的棧空間,注意只是釋放了棧空間,堆空間要等待自動回收。

調用test實例的change3方法,以實例d2爲參數。同理,JVM會在棧中爲局部引用變量b分配空間,並且把d2中的指針存放在b中,此時d2和b指向同一個對象。再調用實例b的setDay方法,其實就是調用d2指向的對象的setDay方法。

調用實例b的setDay方法會影響d2,因爲二者指向的是同一個對象。

change3方法執行完畢,立即釋放局部引用變量b。
以上就是Java程序運行時內存分配的大致情況。其實也沒什麼,掌握了思想就很簡單 了。無非就是兩種類型的變量:基本類型和引用類型。二者作爲局部變量,都放在棧中,基本類型直接在棧中保存值,引用類型只保存一個指向堆區的指針,真正的 對象在堆裏。作爲參數時基本類型就直接傳值,引用類型傳指針。
小結:
1.分清什麼是實例什麼是對象。Class a= new Class();此時a叫實例,而不能說a是對象。實例在棧中,對象在堆中,操作實例實際上是通過實例的指針間接操作對象。多個實例可以指向同一個對象。
2.棧中的數據和堆中的數據銷燬並不是同步的。方法一旦結束,棧中的局部變量立即銷燬,但是堆中對象不一定銷燬。因爲可能有其他變量也指向了這個對象,直到棧中沒有變量指向堆中的對象時,它才銷燬,而且還不是馬上銷燬,要等垃圾回收掃描時纔可以被銷燬。
3.以上的棧、堆、代碼段、數據段等等都是相對於應用程序而言的。每一個應用程序都對應唯一的一個JVM實例,每一個JVM實例都有自己的內存區域,互不影響。並且這些內存區域是所有線程共享的。這裏提到的棧和堆都是整體上的概念,這些堆棧還可以細分。
4.類的成員變量在不同對象中各不相同,都有自己的存儲空間(成員變量在堆中的對象中)。而類的方法卻是該類的所有對象共享的,只有一套,對象使用方法的時候方法才被壓入棧,方法不使用則不佔用內存。
以上分析只涉及了棧和堆,還有一個非常重要的內存區域:常量池,這個地方往往出現一些莫名其妙的問題。常量池是幹嘛的上邊已經說明了,也沒必要理解多麼深刻,只要記住它維護了一個已加載類的常量就可以了。接下來結合一些例子說明常量池的特性。
預備知識:
基本類型和基本類型的包裝類。基本類型有:byte、short、char、int、long、boolean。基本類型的包裝類分別是:Byte、Short、Character、Integer、Long、Boolean。注意區分大小寫。二者的區別是:基本類型體現在程序中是普通變量,基本類型的包裝類是類,體現在程序中是引用變量。因此二者在內存中的存儲位置不同:基本類型存儲在棧中,而基本類型包裝類存儲在堆中。上邊提到的這些包裝類都實現了常量池技術,另外兩種浮點數類型的包裝類則沒有實現。另外,String類型也實現了常量池技術。
實例:
[java] view plaincopy
-
123456789101112131415161718192021222324252627
publicclasstest {publicstaticvoidmain(String[] args) {objPoolTest();}publicstaticvoidobjPoolTest() {inti =40;inti0 =40;Integer i1 =40;Integer i2 =40;Integer i3 =0;Integer i4 =newInteger(40);Integer i5 =newInteger(40);Integer i6 =newInteger(0);Double d1=1.0;Double d2=1.0;System.out.println("i=i0\t"+ (i == i0));System.out.println("i1=i2\t"+ (i1 == i2));System.out.println("i1=i2+i3\t"+ (i1 == i2 + i3));System.out.println("i4=i5\t"+ (i4 == i5));System.out.println("i4=i5+i6\t"+ (i4 == i5 + i6));System.out.println("d1=d2\t"+ (d1==d2));System.out.println();}}
結果:
[java] view plaincopy
-
123456
i=i0truei1=i2truei1=i2+i3truei4=i5falsei4=i5+i6trued1=d2false
結果分析:
1.i和i0均是普通類型(int)的變量,所以數據直接存儲在棧中,而棧有一個很重要的特性:棧中的數據可以共享。當我們定義了int i = 40;,再定義int i0 = 40;這時候會自動檢查棧中是否有40這個數據,如果有,i0會直接指向i的40,不會再添加一個新的40。
2.i1和i2均是引用類型,在棧中存儲指針,因爲Integer是包裝類。由於Integer包裝類實現了常量池技術,因此i1、i2的40均是從常量池中獲取的,均指向同一個地址,因此i1=12。
3.很明顯這是一個加法運算,Java的數學運算都是在棧中進行的,Java會自動對i1、i2進行拆箱操作轉化成整型,因此i1在數值上等於i2+i3。
4.i4和i5均是引用類型,在棧中存儲指針,因爲Integer是包裝類。但是由於他們各自都是new出來的,因此不再從常量池尋找數據,而是從堆中各自new一個對象,然後各自保存指向對象的指針,所以i4和i5不相等,因爲他們所存指針不同,所指向對象不同。
5.這也是一個加法運算,和3同理。
6.d1和d2均是引用類型,在棧中存儲指針,因爲Double是包裝類。但Double包裝類沒有實現常量池技術,因此Doubled1=1.0;相當於Double d1=new Double(1.0);,是從堆new一個對象,d2同理。因此d1和d2存放的指針不同,指向的對象不同,所以不相等。
小結:
1.以上提到的幾種基本類型包裝類均實現了常量池技術,但他們維護的常量僅僅是【-128至127】這個範圍內的常量,如果常量值超過這個範圍,就會從堆中創建對象,不再從常量池中取。比如,把上邊例子改成Integer i1 = 400; Integer i2 = 400;,很明顯超過了127,無法從常量池獲取常量,就要從堆中new新的Integer對象,這時i1和i2就不相等了。
2.String類型也實現了常量池技術,但是稍微有點不同。String型是先檢測常量池中有沒有對應字符串,如果有,則取出來;如果沒有,則把當前的添加進去。
凡是涉及內存原理,一般都是博大精深的領域,切勿聽信一家之言,多讀些文章。我在這只是淺析,裏邊還有很多貓膩,就留給讀者探索思考了。希望本文能對大家有所幫助!
腳註:
(1) 符號引用,顧名思義,就是一個符號,符號引用被使用的時候,纔會解析這個符號。如果熟悉linux或unix系統的,可以把這個符號引用看作一個文件的軟鏈接,當使用這個軟連接的時候,纔會真正解析它,展開它找到實際的文件
對於符號引用,在類加載層面上討論比較多,源碼級別只是一個形式上的討論。
當一個類被加載時,該類所用到的別的類的符號引用都會保存在常量池,實際代碼執行的時候,首次遇到某個別的類時,JVM會對常量池的該類的符號引用展開,轉爲直接引用,這樣下次再遇到同樣的類型時,JVM就不再解析,而直接使用這個已經被解析過的直接引用。
除了上述的類加載過程的符號引用說法,對於源碼級別來說,就是依照引用的解析過程來區別代碼中某些數據屬於符號引用還是直接引用,如,System.out.println("test" +"abc");//這裏發生的效果相當於直接引用,而假設某個Strings = "abc"; System.out.println("test" + s);//這裏的發生的效果相當於符號引用,即把s展開解析,也就相當於s是"abc"的一個符號鏈接,也就是說在編譯的時候,class文件並沒有直接展看s,而把這個s看作一個符號,在實際的代碼執行時,纔會展開這個。
轉自 http://blog.csdn.net/u014723529/article/details/41862375

