




淺談開源大數據平臺的演變
一說到開源大數據處理平臺,就不得不說此領域的開山鼻祖Hadoop,它是GFS和MapReduce的開源實現。雖然在此之前有很多類似的分佈式存儲和計算平臺,但真正能實現工業級應用、降低使用門檻、帶動業界大規模部署的就是Hadoop。得益於MapReduce框架的易用性和容錯性, 以及同時包含存儲系統和計算系統,使得Hadoop成爲大數據處理平臺的基石之一。Hadoop能夠滿足大部分的離線存儲和離線計算需求,且性能表現不 俗;小部分離線存儲和計算需求,在對性能要求不高的情況下,也可以使用Hadoop實現。因此,在搭建大數據處理平臺的初期,Hadoop能滿足90%以 上的離線存儲和離線計算需求,成爲了各大公司初期平臺的首選。
隨着Hadoop集羣越來越大,單點的namenode漸漸成爲了問 題:第一個問題是單機內存有限,承載不了越來越多的文件數目;第二個問題是單點故障,嚴重影響集羣的高可用性。因此業界出現了幾種分佈式namenode 的方案,用以解決單點問題。此外,爲了實現多種計算框架可以運行在同一個集羣中,充分複用機器資源,Hadoop引進了YARN。YARN是一個通用資源 管理器,負責資源調度和資源隔離。它試圖成爲各個計算框架的統一資源管理中心,使得同一個集羣可以同時跑MapReduce、storm、Tez等實例。
Hadoop 解決了大數據平臺的有無問題,隨着業務和需求的精細化發展,在一些細分領域人們對大數據平臺提出了更高的期望和要求,因此誕生了一批在不同領域下的更高效 更有針對性的平臺。首先基於對Hadoop框架自身的改良,出現了haloop和dryad等變種平臺,不過這些平臺後來基本上都沒有被大規模部署,其原 因要麼是改良效果不明顯,要麼是被跳出Hadoop框架重新設計的新平臺所取代了。
爲了解決在hadoop平臺上更好地進行海量網 頁分析,進而實現通用的分佈式NoSQL數據庫的問題,HBase誕生了。Hadoop參照了Google的GFS和MapReduce的設計。而 Google的BigTable在Hadoop的生態圈裏對應的則是HBase。HBase豐富了Hadoop的存儲方式,在hdfs的文件式存儲的基礎 上,提供了表格式存儲,使得可以將網頁的衆多屬性提取出來按字段存放,提升網頁查詢分析的效率。同時,HBase也廣泛被用作通用的NoSQL存儲系統,它 是基於列存儲的非關係型數據庫,彌補了hdfs在隨機讀寫方面的不足,提供低延時的數據訪問能力。但HBase本身沒有提供腳本語言式(如SQL)的數據 訪問方式,爲了克服數據訪問的不便捷問題,最開始用於Hadoop的PIG語言開始支持HBase。PIG是一種操作Hadoop和Hbase的輕量級腳 本語言,不想編寫MapReduce作業的人員可以用PIG方便地訪問數據。
跟HBase類似的另一個較爲有名的系統是C++編寫的Hypertable,也 是BigTable的開源實現,不過由於後來維護的人員越來越少,以及Hadoop生態系統越來越活躍,漸漸地Hypertable被人們遺忘了。還有一 個不得不提的系統是Cassandra,它最初由Facebook開發,也是一個分佈式的NoSQL數據庫。但與HBase和Hypertable是 Bigtable的複製者不同,Cassandra結合了Amazon的Dynamo的存儲模型和Bigtable的數據模型。它的一大特點是使用 Gossip協議實現了去中心化的P2P存儲方式,所有服務器都是等價的,不存在任何一個單點問題。Cassandra與HBase的區別在於:Cassandra配置簡單,平臺組件少,集羣化部署和運維較容易,CAP定理側重於Availability和Partition tolerance,不提供行鎖,不適合存儲超大文件;HBase配置相對複雜,平臺組件多,集羣化部署和運維稍微麻煩,CAP定理側重於Consistency和Availability,提供行鎖,可處理超大文件。
雖 然Hadoop的MapReduce框架足夠易用,但是對於傳統使用SQL操作的數據倉庫類需求時,直接調用Map和Reduce接口來達到類似效果,還 是相對繁瑣,而且對不熟悉MapReduce框架的使用者來說是一個門檻,因此Hive就是爲了解決此問題而誕生。它在Hadoop上建立了一個數據倉庫 框架,可以將結構化的數據文件映射成一張數據庫表,並提供類似SQL的查詢接口,彌補了Hadoop和數據倉庫操作的鴻溝,大大提高了數據查詢和展示類業 務的生產效率。一方面,熟悉SQL的使用者只需要很小的成本就可以遷移至hive平臺,另一方面,由於量級大而在傳統數據倉庫架構下已無法存放的數據,也 可以較爲容易地遷移到hive平臺。因此hive平臺已經成爲了很多公司的大數據倉庫的核心方案。
Hive跟hbase在功能上也 有小部分重疊的地方,它們的主要區別是:Hbase本質是一個數據庫,提供在存儲層的低延時數據讀寫能力,可用在實時場景,但沒有提供類SQL語言的查詢 方式,所以數據查詢和計算不太方便(PIG學習成本較高);hive本質是將SQL語句映射成MapReduce作業,延時較高但使用方便,適合離線場 景,自身不做存儲。此外,hive可以搭建在Hbase之上,訪問Hbase的數據。
Hive的出現橋接了Hadoop與數據倉庫領域,但 隨着hive的逐步應用,人們發現hive的效率並不是太高,原因是hive的查詢是使用MapReduce作業的方式實現的,是在計算層而不是存儲層, 因此受到了MapReduce框架單一的數據傳輸和交互方式的侷限、以及作業調度開銷的影響。爲了讓基於Hadoop的數據倉庫操作效率更高,在hive 之後出現了另一個不同的實現方案——impala,它的基於Hadoop的數據查詢操作,並不是使用MapReduce作業的方式實現,而是跳過了 Hadoop的計算層,直接讀寫hadoop的存儲層——hdfs來實現。由於省去了計算層,因此也就省去了計算層所有的開銷,避免了計算層的單一數據交 互方式的問題,以及多輪計算之間的磁盤IO問題。直接讀寫hdfs,可以實現更加靈活的數據交互方式,提高讀寫效率。它實現了嵌套型數據的列存儲,同時採 用了多層查詢樹,使得它可以在數千節點中快速地並行執行查詢與結果聚合。據一些公開的資料顯示,impala在各個場景下的效率可以比hive提升 3~68倍,尤其在某些特殊場景下的效率提升甚至可達90倍。
Hadoop極大降低了海量數據計算能力的門檻,使得各個業務都可以 快速使用Hadoop進行大數據分析,隨着分析計算的不斷深入,差異化的需求慢慢浮現了。人們開始發現,某些計算,如果時效性更快,收益會變得更大,能提 供給用戶更好的體驗。一開始,在Hadoop平臺上爲了提高時效性,往往會將一整批計算的海量數據,切割成小時級數據,甚至亞小時級數據,從而變成相對輕 量的計算任務,使得在Hadoop上可以較快地計算出當前片段的結果,再把當前片段結果跟之前的累積結果進行合併,就可以較快地得出當前所需的整體結果, 實現較高的時效性。但隨着互聯網行業競爭越來越激烈,對時效性越來越看重,尤其是實時分析統計的需求大量涌現,分鐘級甚至秒級輸出結果,是大家所期望的。 hadoop計算的時效性所能達到的極限一般爲10分鐘左右,受限於集羣負載和調度策略,要想持續穩定地低於10分鐘是非常困難的,除非是專用集羣。因 此,爲了實現更高的時效性,在分鐘級、秒級、甚至毫秒級內計算出結果,Storm應運而生,它完全擺脫了MapReduce架構,重新設計了一個適用於流 式計算的架構,以數據流爲驅動,觸發計算,因此每來一條數據,就可以產生一次計算結果,時效性非常高,一般可以達到秒級。而且它的有向無環圖計算拓撲的設 計,提供了非常靈活豐富的計算方式,覆蓋了常見的實時計算需求,因此在業界得到了大量的部署應用。
Storm的核心框架保證數據流 可靠性方式是:每條數據會被至少發送一次,即正常情況會發送一次,異常情況會重發。這樣會導致中間處理邏輯有可能會收到兩條重複的數據。大多數業務中這樣 不會帶來額外的問題,或者是能夠容忍這樣的誤差,但對於有嚴格事務性要求的業務,則會出現問題,例如扣錢重複扣了兩次這是用戶不可接受的。爲了解決此問 題,Storm引入了事務拓撲,實現了精確處理一次的語義,後來被新的Trident機制所取代。Trident同時還提供了實時數據的join、 groupby、filter等聚合查詢操作。
跟storm類似的系統還有yahoo的S4,不過storm的用戶遠遠多於S4,因此storm的發展比較迅速,功能也更加完善。
隨 着大數據平臺的逐步普及,人們不再滿足於如數據統計、數據關聯等簡單的挖掘,漸漸開始嘗試將機器學習/模式識別的算法用於海量數據的深度挖掘中。因爲機器 學習/模式識別的算法往往比較複雜,屬於計算密集型的算法,且是單機算法,所以在沒有Hadoop之前,將這些算法用於海量數據上幾乎是不可行,至少是工 業應用上不可行:一是單機計算不了如此大量的數據;二是就算單機能夠支撐,但計算時間太長,通常一次計算耗時從幾個星期到幾個月不等,這對於工業界來說資 源和時間的消耗不可接受;三是沒有一個很易用的並行計算平臺,可以將單機算法快速改成並行算法,導致算法的並行化成本很高。而有了Hadoop之後,這些 問題迎刃而解,一大批機器學習/模式識別的算法得以快速用MapReduce框架並行化,被廣泛用在搜索、廣告、自然語言處理、個性化推薦、安全等業務 中。
那麼問題來了,上述的機器學習/模式識別算法往往都是迭代型的計算,一般會迭代幾十至幾百輪,那麼在Hadoop上就是連續的 幾十至幾百個串行的任務,前後兩個任務之間都要經過大量的IO來傳遞數據,據不完全統計,多數的迭代型算法在Hadoop上的耗時,IO佔了80%左右, 如果可以省掉這些IO開銷,那麼對計算速度的提升將是巨大的,因此業界興起了一股基於內存計算的潮流,而Spark則是這方面的佼佼者。它提出了RDD的 概念,通過對RDD的使用將每輪的計算結果分佈式地放在內存中,下一輪直接從內存中讀取上一輪的數據,節省了大量的IO開銷。同時它提供了比Hadoop 的MapReduce方式更加豐富的數據操作方式,有些需要分解成幾輪的Hadoop操作,可在Spark裏一輪實現。因此對於機器學習/模式識別等迭代 型計算,比起Hadoop平臺,在Spark上的計算速度往往會有幾倍到幾十倍的提升。另一方面,Spark的設計初衷就是想兼顧MapReduce模式和迭代型計算,因此老的MapReduce計算也可以遷移至spark平臺。由於Spark對Hadoop計算的兼容,以及對迭代型計算的優異表現,成熟之後的Spark平臺得到迅速的普及。
人 們逐漸發現,Spark所具有的優點,可以擴展到更多的領域,現在Spark已經向通用多功能大數據平臺的方向邁進。爲了讓Spark可以用在數據倉庫領 域,開發者們推出了Shark,它在Spark的框架上提供了類SQL查詢接口,與Hive QL完全兼容,但最近被用戶體驗更好的Spark SQL所取代。Spark SQL涵蓋了Shark的所有特性,並能夠加速現有Hive數據的查詢分析,以及支持直接對原生RDD對象進行關係查詢,顯著降低了使用門檻。在實 時計算領域,Spark streaming項目構建了Spark上的實時計算框架,它將數據流切分成小的時間片段(例如幾秒),批量執行。得益於Spark的內存計算模式和低延 時執行引擎,在Hadoop上做不到的實時計算,在Spark上變得可行。雖然時效性比專門的實時處理系統有一點差距,但也可用於不少實時/準實時場景。 另外Spark上還有圖模型領域的Bagel,其實就是Google的Pregel在Spark上的實現。它提供基於圖的計算模式,後來被新的Spark 圖模型API——GraphX所替代。
當大數據集羣越來越大,出現局部故障的概率也越來越高,集羣核心數據的分佈式一致性變得越來 越難保證。Zookeeper的出現很好地解決了這個棘手的問題,它實現了著名的Fast Paxos算法,提供了一個集羣化的分佈式一致性服務,使得其他平臺和應用可以通過簡單地調用它的服務來實現數據的分佈式一致性,不需要自己關心具體的實 現細節,使大數據平臺開發人員可以將精力更加集中在平臺自身特性上。例如Storm平臺就是使用Zookeeper來存儲集羣元信息(如 節點信息、狀態信息、任務信息等),從而可以簡單高效地實現容錯機制。即使某個組件出現故障,新的替代者可以快速地在Zookeeper上註冊以及獲取所 需的元信息,從而恢復失敗的任務。除了分佈式一致性以外,Zookeeper還可以用作leader選取、熱備切換、資源定位、分佈式鎖、配置管理等場 景。
數據在其生命週期是流動的,往往會有產生、收集、存儲、計算、銷燬等不同狀態,數據可以在 不同狀態之間流動,也可以從同一個狀態的內部進行流動(例如計算狀態),流動時上下游的載體有很多種,例如終端、線上日誌服務器、存儲集羣、計算集羣等。 在後臺,多數情況下都是在大數據平臺之間流動,因此各個大數據平臺並不是孤立的,處理數據時,它們往往成爲上下游的關係,而數據從上游流往下游,就需要一 個數據管道,來正確連接每份數據正確的上下游,這個場景的需求可以使用Kafka集羣來很好地解決。Kafka最初是由LinkedIn開發的,是一個分 布式的消息發佈與訂閱系統。Kafka集羣可以充當一個大數據管道的角色,負責正確連接每種數據的上下游。各個上游產生的數據都發往Kafka集羣,而下 遊則通過向Kafka集羣訂閱的方式,靈活選擇自己所需的上游數據。Kafka支持多個下游訂閱同一個上游數據。當上遊產生了數據,Kafka會把數據進 行一定時間窗口內的持久化,等待下游來讀取數據。Kafka的數據持久化方式及內部容錯機制,提供了較好的數據可靠性,它同時適合於離線和在線消息消費。
以上平臺的誕生時間點如下圖所示:
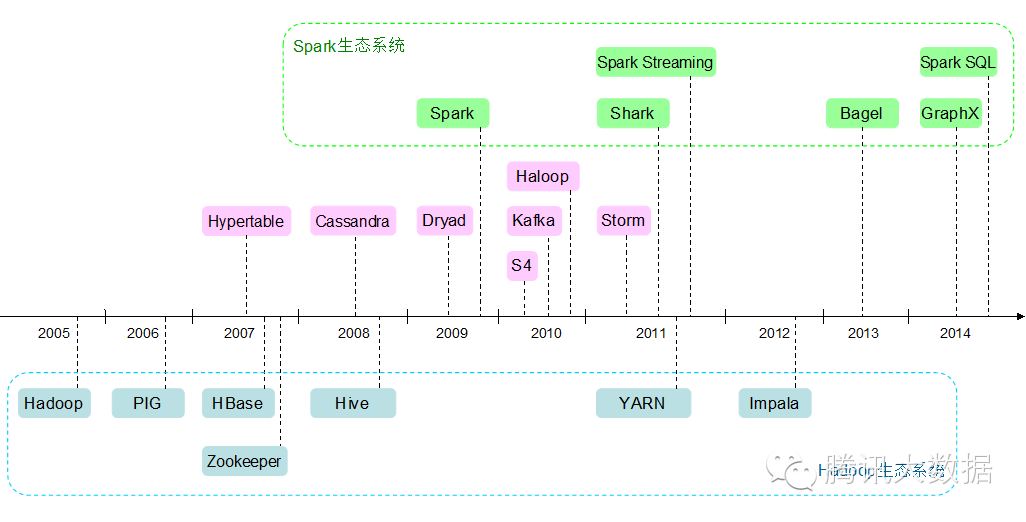
大數據平臺極大地提高了業界的生產力,使得海量數據的存儲、計算變得更加容易和高效。通過這些平臺的使用,可以快速搭建出一個承載海量用戶的應用,移動互聯網正是在它們的催化下不斷高速發展,改變我們的生活。
轉自:騰訊大數據

