




引言
在機器學習應用中,我們不可能離開數據。沒有了數據,機器學習算法就像沒有了靈魂。更好地理解數據,可以使我們把它更好地應用在機器學習上。在這篇文章中,我會介紹一些在統計學中,理解數據的一些重要概念,從而使大家更準確地操作數據,玩轉數據。
頻率(frequency)和相對頻率(relative frequency)
爲了更好地解釋這些數學概念,我用Iris數據集實例來說明頻率和相對頻率。如果大家不熟悉這個數據集沒有關係,下面我用具體的R代碼來看看這個數據集的細節。
> names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
> str(iris)
'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
> summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50
Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500 通過上面代碼我們可以看出,總共有150個observations,總共有3個物種,分別是:virginica、setosa、versicolor. 每個物種分別有50個observations. 每個observations有4個變量,分別是:”Sepal.Length” 、”Sepal.Width”、 “Petal.Length” 、”Petal.Width” “Species”
virginica的頻率爲50,setosa的頻率爲50,versicolor的頻率也爲50. 它們三個物種的相對頻率都爲50 / 150 = 1/3. 所有物種相對頻率的和爲1.
下面我用ggplot來畫出histogram(直方圖)和bar chart(條形圖)
library(ggplot2)
library(gridExtra)
p1 <- ggplot(data = iris, aes(x = Species, fill = Species)) +
geom_bar() +
labs(list(title = "頻率演示", x = "物種", y = "物種頻率"))
p2 <- ggplot(data = iris, aes(x = Species, y = 1 / length(iris$Species))) +
geom_bar(stat = "identity", aes(fill = Species)) +
labs(list(title = "相對頻率演示", x = "物種", y = "物種相對頻率"))
grid.arrange(p1, p2)
ggplot(data = iris, aes(x = Petal.Length)) +
geom_histogram(aes(fill = Species)) +
scale_x_continuous(limits = c(1, 7), breaks = seq(1, 7, 1))
直方圖的x-axis是Numerical/Quantitative,我們可以從中看到某個變量的分佈情況。條形圖的x-axis是Categoriacla/Qualitative,我們可以看到某個類別的總數。如果你想了解更多的信息,請參考:histogram(直方圖)和bar chart(條形圖)
直方圖的區間(interval <=> bin <=> bucket)並不是一成不變的,我們可以根據具體的應用來調整。如果你想玩玩直方圖的區間,這有個交互式的網站,你可以玩玩。Interactivate Histogram
衆數(mode)、平均數(Mean)和中位數(Median)
衆數、平均數和中位數在某些情況下測量的都是數據的中心。下面,我們來具體看一下這三個統計學量。
假設我們從自然數population中取出2個samples,如下:
- 2,1,1,10,12,9,7,6
- 1,2,3,4,4,5,6,7,8
上面兩個samples的衆數分別是:1和4
- 如果我在上面兩個samples中分別加上一個自然數1999999999,衆數依然保持不變,它並沒有受到異常值影響。
- 從同一個population中取出的sample,衆數並不相接近
- 第2個sample的衆數代表着數據的中心,而第一個沒有
下面兩個公式分別計算的是sample和population的平均數。
# 從mean爲99,標準差爲1的正態分佈中取出5個samples
s1 = np.random.normal(99, 1, 100)
s2 = np.random.normal(99, 1, 100)
s3 = np.random.normal(99, 1, 100)
s4 = np.random.normal(99, 1, 100)
s5 = np.random.normal(99, 1, 100)
# 求出每個sample的mean,保留兩位小數
round(np.mean(s1), 2) # 99.07
round(np.mean(s2), 2) # 99.17
round(np.mean(s3), 2) # 99.06
round(np.mean(s4), 2) # 98.85
round(np.mean(s5), 2) # 98.93
# 在s1中加入異常值19999999
s1_outlier = np.append(s1, 19999999)
round(np.mean(s1), 2) # 198117.89從上面的代碼中,我們可以總結以下幾點:
- 從同一個population中取出的sample,mean很接近,因此我們可以用sample平均數去推斷出population的平均數
- 異常值會對mean有非常大的影響
- 異常值會將mean拉向它,從而導致mean不能很好地代表數據中心
假設我們從自然數population中取出2個samples,如下:
- 1,2,3,4,5
- 1,2,3,4,5,6
上面兩個samples的中位數分別是:3和3.5
要想找出數據的中位數,我們首先要給數據排序。假設我們有
如果我在上面的sample中加入異常值,它並不會對median有多大的影響。因此在高度傾斜的分佈中,median是測量數據中心最好的方式。有一點我們應該注意,median並沒有考慮到所有的數據點。
Q1、Q3、IQR、方差和標準差
說到Q1、Q3和IQR,我們不能不提到Boxplot。請看下圖:

圖片來源:https://www.leansigmacorporation.com/wp/wp-content/uploads/2015/12/Box-Plot-MTB_01-1024x470.png
上圖中已經很明白地說明Q1、Q3和IQR各自的含義了。從上圖我們也看到了
- 找到Q2,也就是數據集的Median,因此把數據集分成兩部分
- 找上半部分的Median,即Q3
- 找下半部分的Median,即Q1
方差和標準差度量的是數據的分散程度。計算方差和標準差的公式如下:
大家可能會想爲了去掉數據點與平均值差的負號,我們直接用絕對值不是更簡單明瞭嗎,它也可以度量數據的分散程度啊?爲什麼我們要費這麼大功夫去平方然後在開根號求標準差?
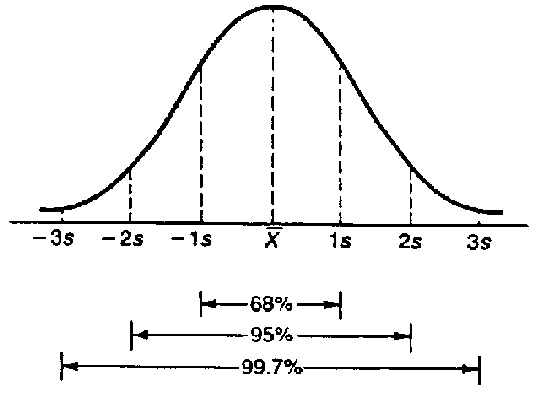
這是因爲在統計分析中,標準差有一些很Cool的性質。下面,是一張關於標準差在正態分佈中的一些性質。

從上圖我們可以看出,在正態分佈中,有大約68%的數據落在距離平均值1個標準差的範圍內,有大約95%的數據落在距離平均值2個標準差的範圍內,等等。實際上,我們可以求出任意百分比的數據落在什麼樣的標準差範圍內。因此,求出標準差至關重要。如果你繼續看文章的後半部分,你就明白了。
下面我來說一下關於population和sample的標準差之間的關係。
如果我們的數據集是整個population,那麼求標準差的公式和我上面寫的一樣。但是如果我們的數據集僅僅是從population中抽取的sample,我們的公式如下:
我們把它叫做Sample standard deviation. 直觀上來講,population中數據大多數都分佈在中心,因此我們的Sample中的數據基本上都來自於中心,這樣所計算出的標準差要比真實的標準差要小,因爲它的數據分散程度要小。因此我們要用N - 1來求解(叫做Bessel’s Correction),這樣會使我們求出的標準差更加接近真實的標準差。Sample standard deviation也就是population標準差
Z-Score
z-score表示一個元素與mean之間相差幾個標準差。它的計算公式如下:
X: 元素的值μ: 平均值σ: 標準差當我們standardization正態分佈時(即z-score過程),我們將得到一個標準的正態分佈,即平均值爲0,標準差爲1的正態分佈。
正態分佈
下圖是一張關於正態分佈的圖片:

圖片來源:https://www.mathsisfun.com/data/images/normal-distrubution-large.gif
在上圖中的正態分佈中,X軸上隨機選擇一個小於x的概率等於負無窮到x與曲線形成的面積。
你可以用微積分的知識求出任意兩點與曲線之間形成的面積。我們也可以用Z-Table來求出小於某個x值的面積。但是,在用Z-Table之前,我們必須要把正態分佈standardization,也就是求出對應x值的z-score。
比如,我想知道小於0.64的面積。Z-Table的行對應着0.6,列對應着0.04,因此我想得到的面積爲0.7389.
中心極限定理(Central limit theorem)
假設一個sample包含很多的observations,每個observation是隨機生成的並且它們之間是相互獨立的,計算這個sample的平均值。重複計算這樣sample的平均值,中心極限定理告訴我們這些平均值服從正態分佈。
在概率理論中,中心極限定理的定義爲:在特定的條件下,不管潛在的population分佈是什麼樣的,大量重複地計算獨立隨機變量的算術平均值,這些平均值將服從正態分佈。
抽樣分佈(Sampling Distribution)
維基百科上給出抽樣分佈的定義爲:In statistics, a sampling distribution or finite-sample distribution is the probability distribution of a given statistic based on a random sample.
舉個例子,假設我們有一個mean爲
這是一個可以自由模擬sampling distribution的網站,大家自己玩玩吧。
http://onlinestatbook.com/stat_sim/sampling_dist/index.html
如果大家想更詳細地理解我上面的內容,這有個Udacity在線課程,希望能幫助到大家 。
https://www.udacity.com/course/ud827
結尾
在第二篇文章中,我會包含以下內容:
- 用sample統計分析去估算population的參數
- hypothesis testing 和自信區間(confidence intervals)
- t-tests and ANOVA
- 變量之間的相關性
- 卡方檢驗(chi-squared test)


{kind=link}
{kind=link}
{kind=link}