




標籤(空格分隔): 機器學習
最近快被各大公司的筆試題淹沒了,其中有一道題是從貝葉斯先驗,優化等各個方面比較L0、L1、L2範數的聯繫與區別。
L0範數
L0範數表示向量中非零元素的個數:
也就是如果我們使用L0範數,即希望w的大部分元素都是0. (w是稀疏的)所以可以用於ML中做稀疏編碼,特徵選擇。通過最小化L0範數,來尋找最少最優的稀疏特徵項。但不幸的是,L0範數的最優化問題是一個NP hard問題,而且理論上有證明,L1範數是L0範數的最優凸近似,因此通常使用L1範數來代替。
L1範數 – (Lasso Regression)
L1範數表示向量中每個元素絕對值的和:
L1範數的解通常是稀疏性的,傾向於選擇數目較少的一些非常大的值或者數目較多的insignificant的小值。
L2範數 – (Ridge Regression)
L2範數即歐氏距離:
L2範數越小,可以使得w的每個元素都很小,接近於0,但L1範數不同的是他不會讓它等於0而是接近於0.
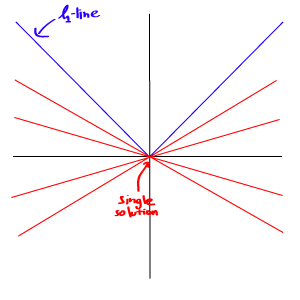
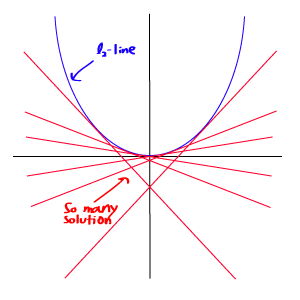
L1範數與L2範數的比較:


但由於L1範數並沒有平滑的函數表示,起初L1最優化問題解決起來非常困難,但隨着計算機技術的到來,利用很多凸優化算法使得L1最優化成爲可能。
貝葉斯先驗
從貝葉斯先驗的角度看,加入正則項相當於加入了一種先驗。即當訓練一個模型時,僅依靠當前的訓練數據集是不夠的,爲了實現更好的泛化能力,往往需要加入先驗項。
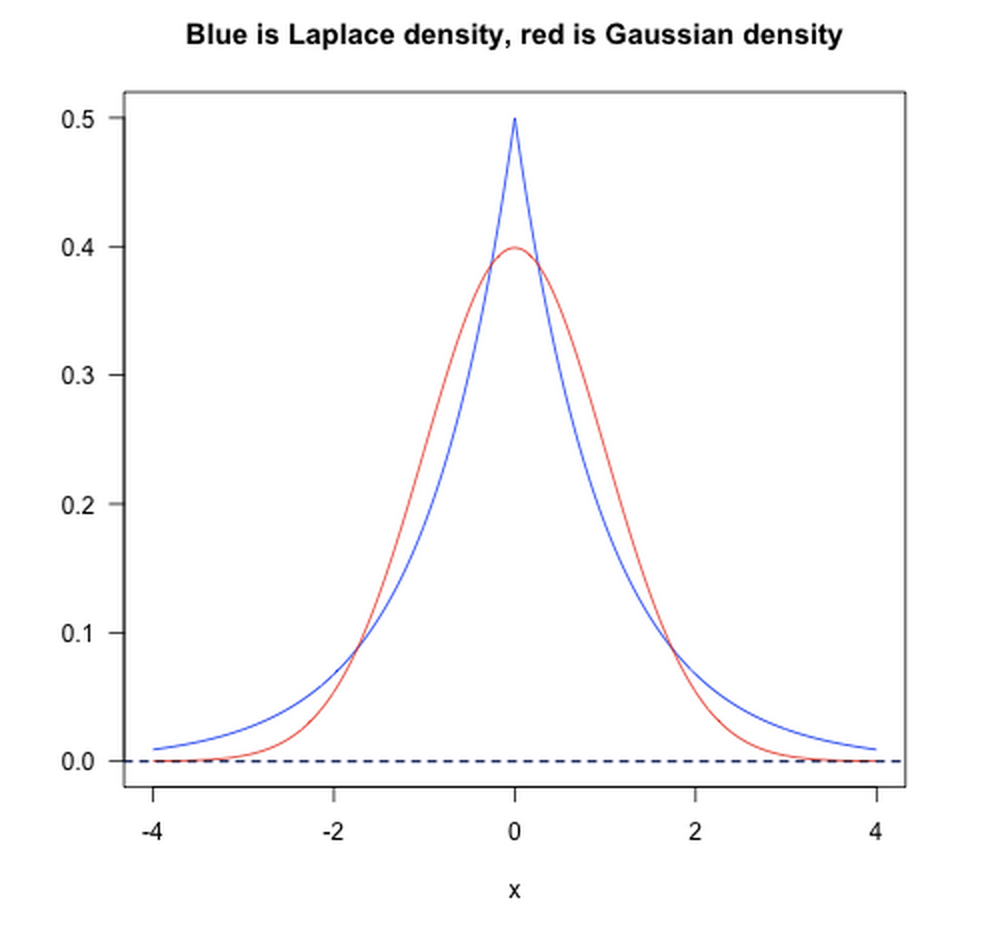
* L1範數相當於加入了一個Laplacean先驗;
* L2範數相當於加入了一個Gaussian先驗。
如下圖所示:

【Reference】
1. http://blog.csdn.net/zouxy09/article/details/24971995
2. http://blog.sciencenet.cn/blog-253188-968555.html
3. http://t.hengwei.me/post/%E6%B5%85%E8%B0%88l0l1l2%E8%8C%83%E6%95%B0%E5%8F%8A%E5%85%B6%E5%BA%94%E7%94%A8.html


{kind=link}
{kind=link}
{kind=link}