




from:https://community.arm.com/cn/b/blog/posts/gpu
原文: Benchmarking floating-point precision in mobile GPUs
作者:tomolson / 2013 年 5 月 29 日下午 2:39 /
談到 GPU 性能時(在Mali官方網站有很多討論),我們通常會談論速度。在之前的博文中,我們談論了每秒可在屏幕中顯示的像素數,每秒可以宣稱繪製的三角形數(不要問),最近我們還談論了每秒可以運行的浮點數操作。談論速度非常有趣,我們熱衷於這一點,但這並非人們感興趣的唯一 GPU 性能指標;質量也算一個。畢竟,如果獲得錯誤的結果,計算速度有多快就不重要了。在我接下來幾篇博文中,我將(暫時)放下對速度的迷戀,談談對 GPU 浮點運算質量的基準測試。要談論的內容有許多,篇幅肯定會很長。所以請保存下來,有時間再細看。
但首先要大喊一聲…
使用浮點運算比較棘手。許多程序員都不能真正地瞭解它,即便是一些非常優秀的也不例外。一些看起來正確的代碼可能得不到正確的結果,而且常常會難以找到的原因。即使在你爲 IEEE-754 兼容良好的 CPU 編寫代碼時,也會存在該問題。當你面對具有更多特性(其實是GPU)的設備時,很容易推斷你看到的不正常現象是因爲在運算上出現了錯誤。但並不一定是這樣;可能只是因爲你對正常結果的直觀概念是錯誤的。
如果你準備利用浮點運算做些比較前衛的事情 – 當然質量基準測試就屬於這一類別 – 你最好習慣於準確思考浮點單元中發生的一切,也就是說要更加細緻地理解浮點運算的原理,可能要超過你真正想要達到的水平。搞定它,黑客!
比你想的更多的細節
如果已瞭解浮點的原理,你可以跳過這一部分;如果沒有,這裏有幾篇有關 IEEE-754 和單精度浮點的維基百科文章,你真的應該讀一下這些優秀文章。不過,對本文而言,你真正需要了解的只是下文:
基本的浮點數包含一個符號位 n,幾個指數位,還有幾個有效數位。(有些人說尾數而不是有效數;我有點喜歡它的發音 – 尾數、尾數,但如今已成爲一種懷舊的說法。)如果使用典型的 FP32 浮點,將有 8 位指數和 23 位有效數。指數(邏輯上)範圍爲 -126 到 +127;此處我將邏輯值寫爲 E。有效數是二進制定點數,我寫爲 1.sss…,值就是:
最後,整個浮點數的值按如下方法算出:
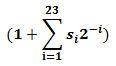
my_value = (-1)n × 2E × 1.sssssssssssssssssssssss
由於有效數的位數是有限的,數字表示的精度就存在限制。
假設我們要將兩個數字相加,如 1600 萬和 11.3125:
16000000 = (-1)0 × 223 × 1.11101000010010000000000
- 11.31250 = (-1)0 × 23 0× 1.01101010000000000000000
要將它們相加,我們首先要右移位(也叫非規範化)較小數字的有效數,使得指數相等。在本例中,我們得移位 20 位:
16000000 = (-1)0 × 223 × 1.11101000010010000000000
- 11.31250 = (-1)0 × 223 × 0.00000000000000000001011(010100…00)
… 然後,將有效數相加獲得結果:
16000011 = (-1)0 × 223 × 1.11101000010010000001011
… 最後,根據需要進行重新規範化,但本例中不需要。
請注意,較小數的一些位(上文紅色表示)移到了有效數的末尾之外而被丟棄,所以我們的結果偏差了 0.3125;這就是你在進行浮點運算時丟失精度的常見方式。你要相加的兩個數字指數差距越大,你丟失的位越多。
GPU 中的浮點精度
現在,我們已準備好開始討論 GPU 中的浮點。我談論這一主題的靈感源自 Stuart
Russell 的文章,該文章發佈在 Youi
Labs 網站上。他比較了 6 款移動 GPU,以及一款桌面顯卡,得到一些有趣的發現。我先回顧一下他的結果。我早前說過浮點是棘手的,正確的行爲可能會產生不直觀的結果 ... 這得到了證實。
Stuart 利用精心設計的 OpenGL ES 2.0 片段(像素)着色器進行了對比。我的版本如下所示;它稍有不同,但這些修改不會影響結果。他的博文包含着色器在每款設備上生成的內容的圖片,我強烈建議花點時間看看這些圖片。結果中存在顯著的差異。它們全部都是OpenGL ES 2.0 兼容設備,但 OpenGL ES 對浮點運算的定義非常鬆散。這對於一般的圖形應用來說不是問題,但測試着色器經過了精心設計,它對浮點運算精度比較敏感。
|
// Youi Labs GPU precision shader (slightly modified) precision highp float; uniform vec2 resolution; void main( void ) { float y = ( gl_FragCoord.y / resolution.y ) * 26.0; float x = 1.0 – ( gl_FragCoord.x / resolution.x ); float b = fract( pow( 2.0, floor(y) ) + x ); if(fract(y) >= 0.9) b = 0.0; gl_FragColor = vec4(b, b, b, 1.0 ); } |
看得出移動 GPU 中存在許多差異;告訴我一些以前不知道的。例如,什麼類型的差異?事實證明,Stuart 的結果中有多個不同(基本上互不相關的)的地方。我將從最簡單的開始:所有圖像都將屏幕畫面劃分多個水平條,但條紋的數量從最少 10 個到最多 23 個不等。爲什麼?
爲了回答這個問題,我們需要仔細看看測試着色器。
測試着色器的行爲
上述着色器在圖像的每個像素上運行。內置的輸入變量 gl_FragCoord 提供 x 和 y 像素座標。函數的第一行(變量 y)將圖像劃分爲 26 個水平條紋,其中 y 的整數部分告訴你當前像素位於哪一個條紋(0 到 25),小數部分告訴你它在條紋上方多遠處。第二行(變量 x)計算亮度值,從圖像最左側的接近 1.0(白色)到最右側的接近 0.0(黑色)呈線性方式改變。第 4 和第 5 行將每個條紋的上部 10% 像素變爲黑色,讓你容易看清條紋數量。
有趣的地方在第 3 行:
float b = fract( pow( 2.0, floor(y) ) + x );
內置的 pow() 函數返回整數:20(第一條)、21(第二條)、22(第三條),以此類推,直到達到 225(最後一條)爲止。該整數值與亮度 x 相加,兩者之和的整數部分被 fract() 函數丟棄。
我們已知道在將兩個不同大小的浮點數相加時會發生什麼:較小數的低階位將被丟棄。所以,當着色器丟棄整數部分時,留下的部分爲原始的亮度 x,除了一些低階位被丟棄之外;我們在第一條少了 0 位,第二條少了 1 位,以此類推。結果導致亮度在灰度的數量級上越來越小,光滑的斜坡變得越來越凹凸不平。當指數的差異等於有效數的位數時,x 的所有位都被丟棄,我們就看不到條紋了。由於 x 始終小於1,其浮點指數最多爲 -1;所以,如果你進行簡單的三年級運算(是介紹負數的時間嗎?),你會讓自己相信圖像中非黑色條紋的數量正好等於着色器引擎的浮點有效數的小數部分的位數。太棒了!
尾數、尾數
所以,這些圖像告訴我們的第一點是不同的 GPU 在有效數的位數上有所不同。似乎分成兩個大類:極簡派,僅提供 OpenGL
ES 2.0 要求的位數;以及奢侈派模型,提供接近於 FP32 的位數。我們來分開考慮。
小即是美
比較中的兩款 GPU 採取了極簡派方式:ARM 的 MaliTM-400 擁有 10 位有效數,NVIDIA 的 Tegra
3 擁有 13 位,兩者都大約是其他四款 GPU 提供位數的一半。區別很大 – 怎麼回事呢?
原因在於 OpenGL ES 2.0(或者說 GLSL ES 1.0 着色語言)定義了三種不同的浮點數:highp、mediump 和 lowp。第一種 (highp) 有至少7 位指數和 16 位有效數,而第二種 (mediump) 則擁有至少 5 位指數和 10 位有效數。(第三種 (lowp) 實際上根本算不上浮點數;最小的實施是 10 位定點數,小數精度爲 8 位。)務必要認識到這些是最小值;需要的話,可以完全自由地實現 64 位浮點的 lowp。
更爲重要的是要認識到,在 OpenGL ES 2.0 中,片段着色器對 highp 精度的支持是可選的。Mali-400 和 Tegra 3 不支持 highp,其他四種 GPU 則是支持的。爲何不同?其他四款 GPU 是統一着色器架構;它們對頂點和片段着色使用相同的計算引擎。OpenGL ES 2.0 要求在頂點着色器中支持 highp;由於必須爲頂點着色提供這一支持,同時提供給片段着色在這些結構上不會增加硅面積成本。Mali-400 和Tegra 3 使用非統一着色器,意味着它們對頂點着色和片段着色使用不同的計算引擎。這允許它們爲必須執行的任務優化各個引擎。支持highp 在硅面積和功耗上成本昂貴,而且並不是標準要求,所以放棄它似乎是這些架構理所當然的選擇。編寫良好的 OpenGL ES 2.0 內容並不需要它,丟棄它可以實現非常、非常高效的核心。
對於如何爲不支持 highp 的 GPU 編寫代碼還有許多要了解的地方;如果需要更加全面的討論,請參閱 seanellis 針對該主題撰寫的博文。
Puttin’ on the Bitz
(對不起,我控制不住自己。)
現在,我們來看看奢侈派模型。在 Stuart 的結果中,如果你放大圖像並且仔細數的話,你會看到 Qualcomm 的 Adreno 225 有 21條,ARM 的 Mali-T604 有 22 條,Vivante 和 Imagination 核心有 23 條。這是否表示 GC2000 和 SGX544 的精度比 Mali 和 Adreno高?
當 Stuart 的博文發表出來時,這個問題讓我輾轉反側。最後,我注意到除了屏幕底部有標準的 Android 導航欄之外,Mali-T604 圖像在屏幕頂部還有一個狀態欄。Adreno 225 圖像中的要厚一點,GC2000 和 SGX544 圖像中則沒有。嗯... 都來看看吧,我們的 Android 黑客。事實證明,如果你不夠仔細,Android 狀態欄可以混合到你所稱的全屏應用的上方;或許,它們覆蓋了其中一些條紋?好吧,我承認,這是我重新實現 Stuart 的着色器的真正原因。我必須搞清楚!
圖 1 顯示了在配備 Mali-T604 的 Nexus 10 上運行該着色器的結果,以及在使用 Qualcomm Adreno 225 的 Samsung Galaxy SIII(美國版)上運行的結果(我們在實施中使用 GL 座標,而不是 DX 座標,因此我們的圖像與 Stuart 的上下顛倒;如果這對你有干擾,那就倒立着看它們吧)。如果你不喜歡數條紋的話,這些圖像表明,這兩款 GPU 實際上在其有效數中有 23 個小數位,與 Imagination 和 Vivante核心相同。也就是說:所有這些 GPU 提供完全相同的原始精度。
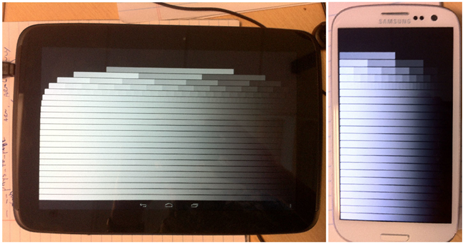
圖 1:測試着色器在 Mali-T604(Nexus 10,左側)和 Adreno 225(Samsung Galaxy SIII,右側)上運行
顯而易見的事實
我們解答了 Stuart 圖像中的條紋數告訴你的問題:它是片段着色器有效數中小數位的數量。Mali-400 有 10 位,正如你從使用 IEEE-754半精度 (binary16) 作爲其浮點類型的設備上所預期的。Adreno
225、GC4000、Mali-T604 和 SGX544 都提供 23 位,表示它們提供的位數與 IEEE-754 單精度 (binary32) 接近。Tegra
3 有效數擁有 13 個小數位,從我的瞭解來看是 NVIDIA 所獨一無二的。
不過,如果你看看 Stuart 的圖像,條紋數並不是你首先注意到的地方。首先跳入你眼簾的是這些條紋排列成形狀各不相同的圖案。其中一些(如上圖 1 中的 Mali-T604)組成了對稱的碗或蜂巢狀;而 Adreno 225 等另一些則緊靠在圖像左側並且逐漸以曲線方式向右分散;Imagination SGX544 的圖形則完全別具一格。怎麼回事呢?答案很是有趣,但這篇博文已經夠長了,今天到此爲止吧。在下一篇中,我們將探索那些不同之處,看看它們會告訴我們有關這些 GPU 的什麼信息。
到那時候 - 認爲我上面所說的有錯嗎?認爲我在胡說八道嗎?那就留言吧…


{kind=link}