




作者:Trisha 譯者:方騰飛 校對:丁一
我們經常提到一個短語Mechanical Sympathy,這個短語也是Martin博客的標題(譯註:Martin Thompson),Mechanical Sympathy講的是底層硬件是如何運作的,以及與其協作而非相悖的編程方式。
我在上一篇文章中提到RingBuffer後,我們收到一些關於RingBuffer中填充高速緩存行的評論和疑問。由於這個適合用漂亮的圖片來說明,所以我想這是下一個我該解決的問題了。
(譯註:Martin Thompson很喜歡用Mechanical Sympathy這個短語,這個短語源於賽車駕駛,它反映了駕駛員對於汽車有一種天生的感覺,所以他們對於如何最佳的駕御它非常有感覺。)
計算機入門
我喜歡在LMAX工作的原因之一是,在這裏工作讓我明白從大學和A Level Computing所學的東西實際上還是有意義的。做爲一個開發者你可以逃避不去了解CPU,數據結構或者大O符號——而我用了10年的職業生涯來忘記這些東西。但是現在看來,如果你知道這些知識並應用它,你能寫出一些非常巧妙和非常快速的代碼。
因此,對在學校學過的人是種複習,對未學過的人是個簡單介紹。但是請注意,這篇文章包含了大量的過度簡化。
CPU是你機器的心臟,最終由它來執行所有運算和程序。主內存(RAM)是你的數據(包括代碼行)存放的地方。本文將忽略硬件驅動和網絡之類的東西,因爲Disruptor的目標是儘可能多的在內存中運行。
CPU和主內存之間有好幾層緩存,因爲即使直接訪問主內存也是非常慢的。如果你正在多次對一塊數據做相同的運算,那麼在執行運算的時候把它加載到離CPU很近的地方就有意義了(比如一個循環計數-你不想每次循環都跑到主內存去取這個數據來增長它吧)。
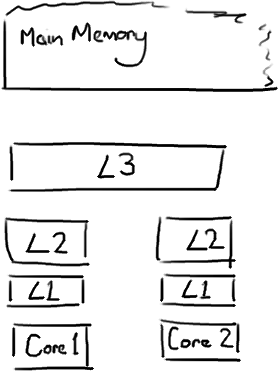
越靠近CPU的緩存越快也越小。所以L1緩存很小但很快(譯註:L1表示一級緩存),並且緊靠着在使用它的CPU內核。L2大一些,也慢一些,並且仍然只能被一個單獨的 CPU 核使用。L3在現代多核機器中更普遍,仍然更大,更慢,並且被單個插槽上的所有 CPU核共享。最後,你擁有一塊主存,由全部插槽上的所有 CPU核共享。
當CPU執行運算的時候,它先去L1查找所需的數據,再去L2,然後是L3,最後如果這些緩存中都沒有,所需的數據就要去主內存拿。走得越遠,運算耗費的時間就越長。所以如果你在做一些很頻繁的事,你要確保數據在L1緩存中。
Martin和Mike的 QConpresentation演講中給出了一些緩存未命中的消耗數據:
|
從CPU到 |
大約需要的 CPU 週期 |
大約需要的時間 |
|
主存 |
|
約60-80納秒 |
|
QPI 總線傳輸 (between sockets, not drawn) |
|
約20ns |
|
L3 cache |
約40-45 cycles, |
約15ns |
|
L2 cache |
約10 cycles, |
約3ns |
|
L1 cache |
約3-4 cycles, |
約1ns |
|
寄存器 |
1 cycle |
|
如果你的目標是讓端到端的延遲只有 10毫秒,而其中花80納秒去主存拿一些未命中數據的過程將佔很重的一塊。
緩存行
現在需要注意一件有趣的事情,數據在緩存中不是以獨立的項來存儲的,如不是一個單獨的變量,也不是一個單獨的指針。緩存是由緩存行組成的,通常是64字節(譯註:這篇文章發表時常用處理器的緩存行是64字節的,比較舊的處理器緩存行是32字節),並且它有效地引用主內存中的一塊地址。一個Java的long類型是8字節,因此在一個緩存行中可以存8個long類型的變量。
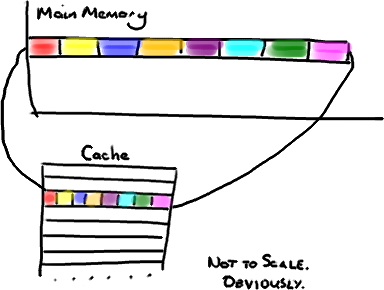
(爲了簡化,我將忽略多級緩存)
非常奇妙的是如果你訪問一個long數組,當數組中的一個值被加載到緩存中,它會額外加載另外7個。因此你能非常快地遍歷這個數組。事實上,你可以非常快速的遍歷在連續的內存塊中分配的任意數據結構。我在第一篇關於ringbuffer的文章中順便提到過這個,它解釋了我們的ring buffer使用數組的原因。
因此如果你數據結構中的項在內存中不是彼此相鄰的(鏈表,我正在關注你呢),你將得不到免費緩存加載所帶來的優勢。並且在這些數據結構中的每一個項都可能會出現緩存未命中。
不過,所有這種免費加載有一個弊端。設想你的long類型的數據不是數組的一部分。設想它只是一個單獨的變量。讓我們稱它爲head,這麼稱呼它其實沒有什麼原因。然後再設想在你的類中有另一個變量緊挨着它。讓我們直接稱它爲tail。現在,當你加載head到緩存的時候,你也免費加載了tail。
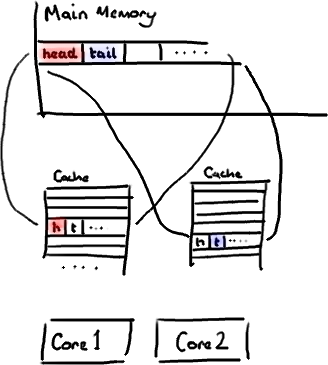
聽想來不錯。直到你意識到tail正在被你的生產者寫入,而head正在被你的消費者寫入。這兩個變量實際上並不是密切相關的,而事實上卻要被兩個不同內核中運行的線程所使用。
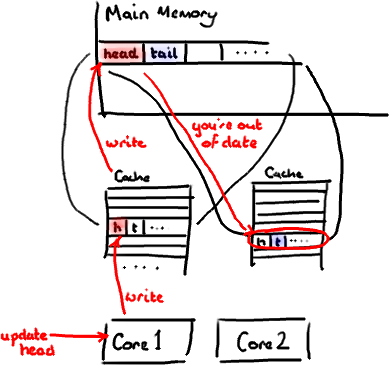
設想你的消費者更新了head的值。緩存中的值和內存中的值都被更新了,而其他所有存儲head的緩存行都會都會失效,因爲其它緩存中head不是最新值了。請記住我們必須以整個緩存行作爲單位來處理(譯註:這是CPU的實現所規定的,詳細可參見深入分析Volatile的實現原理),不能只把head標記爲無效。
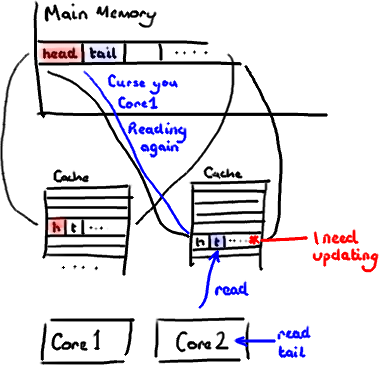
現在如果一些正在其他內核中運行的進程只是想讀tail的值,整個緩存行需要從主內存重新讀取。那麼一個和你的消費者無關的線程讀一個和head無關的值,它被緩存未命中給拖慢了。
當然如果兩個獨立的線程同時寫兩個不同的值會更糟。因爲每次線程對緩存行進行寫操作時,每個內核都要把另一個內核上的緩存塊無效掉並重新讀取裏面的數據。你基本上是遇到兩個線程之間的寫衝突了,儘管它們寫入的是不同的變量。
這叫作“僞共享”(譯註:可以理解爲錯誤的共享),因爲每次你訪問head你也會得到tail,而且每次你訪問tail,你也會得到head。這一切都在後臺發生,並且沒有任何編譯警告會告訴你,你正在寫一個併發訪問效率很低的代碼。
解決方案-神奇的緩存行填充
你會看到Disruptor消除這個問題,至少對於緩存行大小是64字節或更少的處理器架構來說是這樣的(譯註:有可能處理器的緩存行是128字節,那麼使用64字節填充還是會存在僞共享問題),通過增加補全來確保ring buffer的序列號不會和其他東西同時存在於一個緩存行中。
|
1 |
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding |
|
2 |
private volatile long cursor = INITIAL_CURSOR_VALUE; |
|
3 |
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding |
因此沒有僞共享,就沒有和其它任何變量的意外衝突,沒有不必要的緩存未命中。
在你的Entry類中也值得這樣做,如果你有不同的消費者往不同的字段寫入,你需要確保各個字段間不會出現僞共享。
修改:Martin寫了一個從技術上來說更準確更詳細的關於僞共享的文章,並且發佈了性能測試結果。
轉載自併發編程網 – ifeve.com本文鏈接地址: 剖析Disruptor:爲什麼會這麼快?(二)神奇的緩存行填充