




讓我們不厭其煩地回顧一下:最小熵原理是一個無監督學習的原理,“熵”就是學習成本,而降低學習成本是我們的不懈追求,所以通過“最小化學習成本”就能夠無監督地學習出很多符合我們認知的結果,這就是最小熵原理的基本理念。
這篇文章裏,我們會介紹一種相當漂亮的聚類算法,它同樣也體現了最小熵原理,或者說它可以通過最小熵原理導出來,名爲InfoMap,或者MapEquation。事實上InfoMap已經是2007年的成果了,最早的論文是《Maps of random walks on complex networks reveal community structure》,雖然看起來很舊,但我認爲它仍是當前最漂亮的聚類算法,因爲它不僅告訴了我們“怎麼聚類”,更重要的是給了我們一個“爲什麼要聚類”的優雅的信息論解釋,並從這個解釋中直接導出了整個聚類過程。
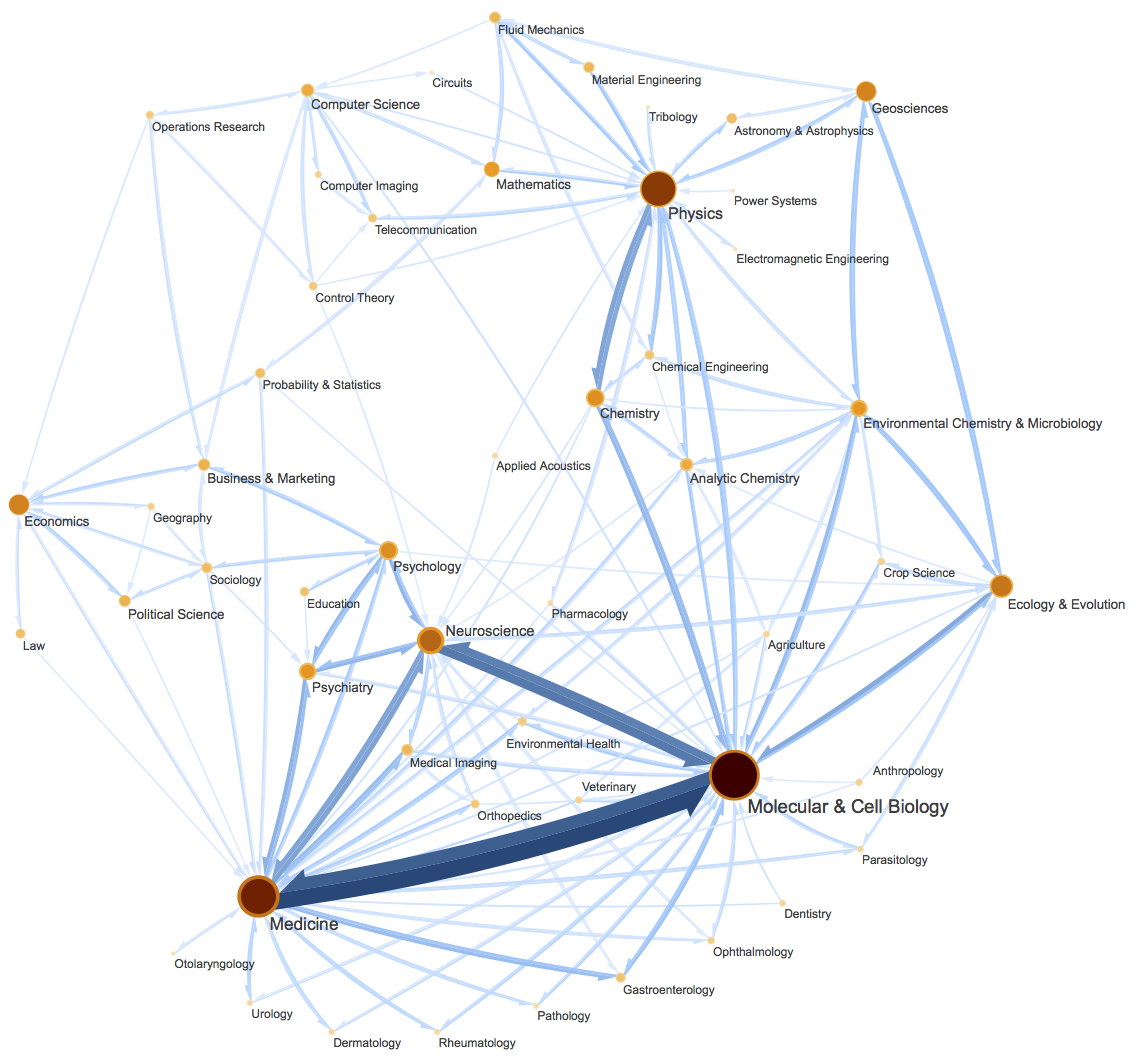
一個複雜有向圖網絡示意圖。圖片來自InfoMap最早的論文《Maps of random walks on complex networks reveal community structure》
當然,它的定位並不僅僅侷限在聚類上,更準確地說,它是一種圖網絡上的“社區發現”算法。所謂社區發現(Community Detection),大概意思是給定一個有向/無向圖網絡,然後找出這個網絡上的“抱團”情況,至於詳細含義,大家可以自行搜索一下。簡單來說,它跟聚類相似,但是比聚類的含義更豐富。(還可以參考《什麼是社區發現?》)
熵與編碼 #
在前面幾篇文章中,我們一直用信息熵的概念來描述相關概念,而從這篇文章開始,我們引入信息熵的等價概念——平均編碼長度,引入它有助於我們更精確地理解和構建最小熵的目標。
二叉樹編碼 #
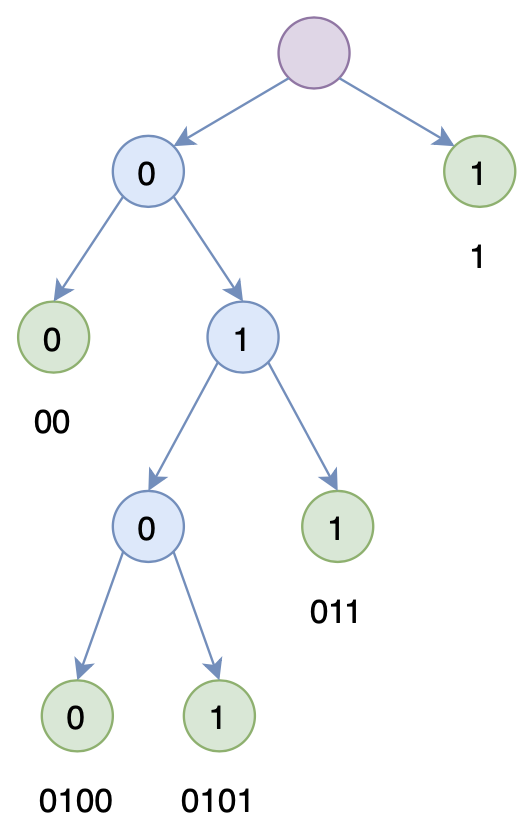
每個編碼都不是其餘某個編碼的前綴,所以這些編碼可以構成一棵二叉樹
所謂編碼,就是隻用有限個標記的組合來表示原始信息,最典型的就是二進制編碼,即只用0和1兩個數字。編碼與原始對象通常是一一對應的,比如“科”可能對應着11,“學”對應着1001,那麼“科學”就對應着(11,1001)。
注意這裏我們考慮的是靜態編碼,即每個被編碼對象跟編碼結果是一一對應的,同時這裏考慮的是無分隔符編碼,即不需要額外的分隔符就可以解碼出單個被編碼對象。這隻須要求每個編碼不能是其餘某個編碼的前綴(這樣我們每次只需要不斷讀取編碼,直至識別出一個編碼對象,然後再開始新的讀取)。這就意味着所有編碼能夠構建成一棵二叉樹,使得每個編碼對應着這棵樹的某個葉子,如圖所示。
在此基礎上,我們可以得到一個很有趣也很有意義的結論,就是假設n個不同的字符,它們的編碼長度分別爲
 (1)
(1)
這其實就是這種二叉樹表示的直接推論了,讀者可以自行嘗試去證明它。
最短編碼長度 #
現在想象一個“速記”的場景,我們需要快速地記錄下我們所聽到的文字,記錄的方式正是每個字對應一個二進制編碼(暫時別去考慮人怎麼記得住字與編碼間的對應關係),那爲了記得更快,我們顯然是希望經常出現的字用短的編碼,比如“的”通常出現的很頻繁,如果用11000010001來表示“的”,那麼每次聽到“的”我們都需要寫這麼一長串的數字,會拖慢記錄速度,反而如果用短的編碼比如10來表示“的”,那相對而言記錄速度就能有明顯提升了。
假設一共有n個不同的字符,每個字符的出現概率分別是
對於第一個問題,答案是Huffman編碼,沒錯,就是Word2Vec裏邊的Huffman Softmax的那個Huffman,但這不是本文的重點,有興趣的讀者自行找資料閱讀就好。而第二個問題的答案,是信息論裏邊的一個基本結果,它正是信息熵

也就是說,信息熵正好是理論上的最短平均編碼長度。注意這是一個非常“強大”的結果,它告訴我們不管你用什麼編碼(不管是有分隔符還是沒分隔符,不管是靜態的還是動態的),其平均編碼長度都不可能低於(2)。
在這裏我們就前面說的無分隔符編碼場景,給出(2)的一個簡單的證明。依然設n個字符的編碼長度分別是

因爲我們有不等式(1),所以定義:

上式可以寫成:

這就是概率分佈


其實稍微接觸過信息論的讀者,都應該知道這個結論,它告訴我們編碼的最短平均長度就是信息熵,這其實也是無損壓縮的能力極限,我們通過尋找更佳的方案去逼近這個極限,這便是最小熵。
最後,由於不同的對數底只會導致結果差一個常數比例,所以通常情況下我們不特別聲明是哪個底,有些情況下則乾脆默認地使用自然對數底,因爲自然對數有時能得到更簡單的理論形式。
InfoMap #
回到InfoMap,它跟前面說的壓縮編碼有直接聯繫。事實上,在中大讀研一的時候導師就已經給筆者介紹過InfoMap了,但是很遺憾,直到前幾天(2019年10月15日)我纔算是理解了InfoMap的來龍去脈。那麼久都沒弄懂的原因,一方面是當時對信息熵和編碼相關理論都不熟悉,以至於看到文章的概念就覺得迷迷糊糊;另一方面,我覺得原論文的作者們可能並不清楚非信息論相關的讀者理解這個算法的瓶頸在哪,以至於沒有把關鍵地方表達清楚。
於是我決定把我自己的理解寫下來,希望能讓給多的讀者更好地理解InfoMap這個算法,畢竟它真的很美~~
InfoMap的論文清單:https://www.mapequation.org/publications.html
(爲了一個算法還特意辦了一個網站,並且算法活躍至今,可見作者本身對這個算法的熱愛,以及這個算法的漂亮和有效。)
分類記憶 #
假如我們有這麼一個任務,要求我們在短時間內把下面的序列背下來:

待記憶序列
序列不長,背下來不難,爲了快速地形成記憶,大家的記憶思路可能是這樣的:
1、前面3個是水果;中間5個是城市;後面4個是阿拉伯數字;
2、前面3個水果分別是雪梨、葡萄、香蕉;
3、中間5個城市分別是廣州、上海、北京、杭州、深圳;
4、後面4個數字分別是123、654、798、963。
也就是說,大家基本上都會想着按類分組記憶的思路,這樣記憶效率和效果都會更好些,而最小熵系列告訴我們,“提效”、“省力”的數學描述就是熵的降低,所以一個好的分類方案,應該是滿足最小熵原理的,它能夠使得系統的熵降低。這便是InfoMap本質的優化目標,通過最小化熵來尋求最優的聚類方案。
層次編碼:概念 #
前面說了,信息熵就等價於最短編碼長度,所以最小熵事實上就是在尋找更好的壓縮算法。既然剛纔說分組記憶效率更高,那必然對應着某種編碼方法使得我們能更有效地壓縮信息,這種編碼方法就是層次編碼。
所謂層次編碼,就是我們不再用單一的編碼來表示一個對象,而是用兩個(也可以更多,本文主要分析兩個)編碼的組合來表示一個對象,其中第一個編碼代表對象的類別,第二個編碼則代表它在類內的編號。假如同一個類的對象經常“扎堆”出現,那麼層次編碼就能起到壓縮的作用。
究竟怎樣的層次編碼能壓縮呢?很遺憾,我看到的所有InfoMap的資料,包括原作者的論文,都沒有突出這個分層編碼的方法。我認爲這個編碼過程是要突出的,這樣對非信息論相關專業的讀者會更友好。事實上,它的編碼過程如下:

層次編碼方式。在同一個類別的詞語前插入一個類別標記,以及在類結束處插入一個終止標記
要注意,編碼要保證無損,換言之要有相應的方法解碼爲原始序列,爲此層次編碼在原始序列的基礎上插入了類別標記和終止標記,其中類別標記用單獨一套編碼,類別內的對象以及終止標記用另一套編碼(這個是最重要的,類別的結束標記,也就是論文中的exit code word是算到類別內部編碼的,而不是和類別一起的,所以計算平均編碼長度的時候要考慮除了類別內的節點之外,還有額外的一個exit code word需要計算),由於有了類別區分,因此不同類的對象可以用同一個編碼,比如上圖中“雪梨”和“上海”都可以用001編碼,這樣就可以使得整體的平均編碼長度變小了。解碼的時候,只需要讀到第一個類別編碼,就開始使用該類別的類內編碼來識別原對象,直到出現結束符就開始新的類別編碼讀取,然後重複這個過程。
層次編碼:計算 #
好了,既然確定了這種編碼方式確實是無損的,接下來就需要計算了,因爲“縮短平均編碼長度”的結論不能單靠直觀感知,還必須有定量的計算結果。
假設已經有了特定的層次編碼方案,那麼我們就可以計算這種編碼方案的平均編碼長度了,定義下述記號

對於公式(8),還是有不少人不太理解,總覺得類別的概率怎麼能和類別內部的節點的概率加到一起呢?這倆不是一個層次的啊!這裏再解釋一下:infomap的引出是藉助隨機遊走模型產生的隨機遊走序列,然後對該無限步的隨機遊走序列進行編碼,最後計算平均每步隨機遊走編碼的長度。這裏只需要從隨機遊走序列出發來解釋公式(8)就很容易理解了。因爲要使用層次化編碼,那麼隨機遊走序列必然包含3類編碼:類別編碼、類別內的節點編碼和類別的結束編碼。這樣這3類在整個編碼序列中都佔有一定的比率,自然就是出現的概率啦!!!。

隨機遊走 #
至此,我們得到了一個優化目標(11),在給定一個序列的情況下,我們可以通過最小化這個目標來爲這個序列的對象聚類。但我們仍然還沒有將它跟經典的聚類任務對應起來,因爲經典的聚類問題並沒有這種序列,一般只是給出了任意兩個樣本之間的相似度(或者給出樣本本身的向量,通過這個向量也可以去算兩個樣本之間的某種相似度)。
InfoMap做得更細緻一些,它將我們要聚類的樣本集抽象爲一個有向圖,每個樣本是圖上的一個點,而圖上的任意兩個點(α,β)都有一條β→α的邊,邊的權重爲轉移概率

有了這個設定之後,一個很經典的想法——“隨機遊走”——就出來了:從某個點jj開始,依概率p(i|j))跳轉下一個點i,然後從i點出發,再依轉移概率跳轉到下一個點,重複這個過程。這樣我們就可以得到一個很長很長的序列。有了序列之後,就能以(11)爲目標來聚類了。
InfoMap編碼與聚類過程。(a)隨機遊走; (b)根據隨機遊走的概率直接構建huffman編碼; (c)層次編碼; (d)層次編碼中的類別編碼。最下方顯示了對應的編碼序列,可以看到層次編碼的編碼序列更短
這就是InfoMap的聚類過程了——通過構造轉移概率,在圖上進行隨機遊走來生成序列,在通過對序列做層次編碼,最小化目標(11)(11),從而完成聚類。
順便提一下,當初DeepWalk(2014年)提出來在圖上進行隨機遊走生成序列然後套用Word2Vec的做法,不少人都覺得很新奇,是個突破,但現在看來在圖上做隨機遊走的思路由來已久了。
InfoMap #
現在,我們將上述過程做得更細緻化、數學化一些,畢竟數學公式是把原理描述清楚的唯一方法。
首先,我們不需要真的圖上進行隨機遊走模擬,因爲事實上我們不需要生成的序列,我們只需要知道隨機遊走生成的序列裏邊每個對象的概率,爲此,我們只需要去解方程

有了穿越概率,模型一般就不會陷入某個局部解了,從而導致瞭解的唯一性。ττ是一個額外的超參,作者取了τ=0.15,而爲了使得結果對ττ更魯棒,作者還使用了其他一些技巧,具體細節請去看作者的《The map equation》和《Community detection and visualization of networks with the map equation framework》。


推廣思路 #
InfoMap的美妙之處,不僅在於它漂亮的信息論解釋、沒有過多的超參等,還在於它易於推廣性——至少思路上是很容易想到的。
比如,前面都是用兩層的層次編碼,我們可以構造多層的層次編碼,也就是給類再聚類,而事實上將優化目標(11)(11)從雙層推廣到多層只是一件繁瑣但沒有技術難度的事情,因爲只需要模仿雙層編碼的方式,構思對應的多層編碼的方案(引入類中類的類標記和終止標記等),具體細節可以參考《Multilevel compression of random walks on networks reveals hierarchical organization in large integrated systems》、《Community detection and visualization of networks with the map equation framework》,本文不再詳細介紹了。
再比如,還可以推廣到重疊社區挖掘。所謂重疊社區挖掘,也就是單個對象可能同時屬於多個不同的類別。《什麼是社區發現?》一文提供一個關於小區大媽組隊跳廣場舞的很生動的例子:一般來說,每個大媽參加活動時,往往會優先選擇自己所在小區的廣場舞隊伍,但是,有些大媽精力比較旺盛,覺得只參加自己小區的隊伍還不過癮,或者她是社交型人士,希望通過跳廣場舞認識更多的朋友,那麼,她可能會同時參加周邊小區的多個廣場舞隊伍,換言之,她同時就屬於多個社區(類)了。另外還可以從NLP的詞聚類角度來看,重疊社區挖掘就意味着多義詞的挖掘了。對於InfoMap來說,挖掘重疊社區依然是最小化(11)(11),將同一個對象賦予到多個類中,對該對象本身的編碼會引入一定的冗餘,但是有可能減少了類標記和終止標記的使用,從而降低了整體的平均編碼長度。論文則可以參考《Compression of Flow Can Reveal Overlapping-Module Organization in Networks》。
這些推廣特性都是大多數其他聚類算法和社區發現算法所不具備的,這進一步體現了InfoMap的強大與漂亮。此外,官網的publications頁面上還有一堆InfoMap的推廣和應用論文,都可以參考:

InfoMap官方提供的論文列表
實驗 #
好了,說了那麼久理論,也該動動手做做實驗了。本節會先簡單介紹一下InfoMap具體是怎麼搜索這種分類策略的,然後給出一個詞聚類的例子,初步體驗一下InfoMap的魅力。
求解算法 #
InfoMap最早的求解算法是貪心搜索加模擬退火。貪心搜索中,最開始將每個點都視爲不同的類,然後將使得(11)下降幅度最大的兩個類合併爲一個類,並且重複這個過程,直到不能下降爲止;模擬退火是在探索搜索的結果基礎上對聚類方案進行進一步的微調。(來自《Maps of random walks on complex networks reveal community structure》)
而後在《The map equation》一文中,作者改進了貪心搜索,並移除了模擬退火,使得它達到了速度和效果的平衡。改進的算法大概是(具體細節還是得看原論文):
1、每個點都初始化一個獨立的類;
2、按照隨機的順序遍歷每個點,將每個點都歸到讓(11)下降幅度最大的那個相鄰的類;
3、重複步驟2(每次都用不同的隨機順序),直到(11)不再下降;
4、通過一些新的策略來精調前面三步得到的聚類結果。
不管是早期的求解算法還是後來的改進算法,InfoMap的求解都稱得上非常快,它裏邊給出了兩組參考結果:1、單純用貪心搜索可以在260萬個節點、2900萬條邊的圖網絡上成功完成社區發現;2、改進的算法在1萬個節點、10萬條邊的圖網絡上的社區發現可以在5秒內完成(考慮到當時的計算機並沒有現在的快,所以現在跑的話就不用五秒了。)。
安裝說明 #
作者們用C++實現了InfoMap,並且提供了Python、R等第三方語言的接口,同時支持Linux、Mac OS X和Windows系統~
官網:https://www.mapequation.org/code.html
Github:https://github.com/mapequation/infomap
這裏自然是隻關心Python接口了。經過一番折騰,確定了下面幾個情況:
1、InfoMap目前有兩個版本,其中0.x的是穩定版,另外有個1.0處於beta階段;
2、直接pip install infomap安裝的就是beta的1.0版本,但是功能不全,並且只支持Python 3.x;
3、全功能的還是0.x版本,支持Python 2.7,但我不知道爲什麼0.x的最新版編譯成功後import會出錯。
因爲我之前就安裝過InfoMap並且用得很舒適,但弄到新版後各種問題(不知道作者是怎麼改的),所以我建議還是從Github上拉它的0.x的舊版本手動編譯安裝吧,下面是參考的編譯安裝代碼:
wget -c https://github.com/mapequation/infomap/archive/6ab17f8b18a6fdf34b2a53454f79a3b976a49201.zip
unzip 6ab17f8b18a6fdf34b2a53454f79a3b976a49201.zip
cd infomap-6ab17f8b18a6fdf34b2a53454f79a3b976a49201
cd examples/python
make
# 編譯完之後,當前目錄下就會有一個infomap文件夾,就是編譯好的模塊;
# 爲了方便調用,可以複製到python的模塊文件夾(每臺電腦的路徑可能不一樣)中
python example-simple.py
cp infomap /home/you/you/python/lib/python2.7/site-packages -rf
examples/python則給出了一些簡單的demo,可以閱讀參考。
詞聚類 #
下面跟Word2Vec配合,跑一個詞聚類的例子,代碼位於:
https://github.com/bojone/infomap/blob/master/word_cluster.py
聚類結果(部分):
[u'妹妹', u'姐姐', u'哥哥', u'弟弟', u'爸爸', u'兒子', u'母親', u'女兒', u'父親', u'妻子', u'爺爺', u'老婆', u'丈夫', u'男友', u'女友', u'愛人', u'媽媽', u'長子', u'小時候', u'父母', u'祖父', u'情人', u' 親人', u'弟', u'家人', u'夫婦', u'妻', u'兄', u'妹', u'家裏', u'姐妹', u'父', u'嫁給', u'從小', u'子女', u'嫁', u'夫', u'家中', u'娶', u'姐', u'叔', u'長大', u'夫人', u'父子', u'在家', u'娘', u'兄弟', u' 家屬', u'奴', u'母', u'子', u'哥', u'兒', u'兒女', u'小姐']
[u'加強', u'建立健全', u'推進', u'擬定', u'落實', u'提高', u'規章制度', u'會同', u'搞好', u'切實', u'負責', u'促進', u'貫徹落實', u'制訂', u'增強', u'抓好', u'深化', u'組織協調', u'擬訂', u'加快', u'加大', u'實施', u'着力', u'有利於', u'制定', u'推動', u'進一步', u'貫徹', u'督促', u'改善', u'大力', u'貫徹執行', u'充分發揮', u'牽頭', u'政策措施', u'年度計劃', u'強化', u'提升', u'增進', u'中長期', u'健全', u'優化', u'方針', u'做好', u'協調', u'統籌', u'承辦', u'協助', u'全力', u'積極', u'責任制', u'黨和國家', u'步伐', u'力度', u'承擔', u'開展', u'鞏固', u'編制', u'有利', u'改進', u'加深', u'不利', u'各項', u'加速', u'圍繞', u'組織', u'銜接', u'認真']
[u'股權', u'證券', u'融資', u'股票', u'金融機構', u'上市公司', u'信貸', u'債券', u'商業銀行', u'貸款', u'金融', u'期貨', u'信託', u'存款', u'債權', u'擔保', u'股份', u'銀行', u'抵押', u'董事長', u'副總經 理', u'外匯', u'總經理', u'利率', u'董事', u'餘額', u'總監', u'保險公司', u'併購', u'股東', u'利息', u'CEO', u'國有企業', u'債務', u'資產', u'分行', u'經理', u'負債', u'股市', u'信用', u'總額', u'總裁', u'國有資產', u'股價', u'投資者', u'資本', u'匯率', u'數額', u'金額', u'投資', u'首席', u'賬戶', u'國有', u'貨幣', u'郵政', u'董事會', u'創始人', u'改制', u'支行', u'主管', u'出資', u'破產', u'重組', u'財產', u'披露', u'固定資產', u'收購', u'上漲', u'財富', u'商業', u'現金']
[u'教師', u'教學', u'教研', u'素質教育', u'課堂教學', u'教學質量', u'教學改革', u'該校', u'學生', u'基礎教育', u'我校', u'高職', u'德育', u'教職工', u'職業教育', u'高等院校', u'辦學', u'教師隊伍', u'院校', u'師資', u'在校生', u'考生', u'教育', u'高等學校', u'同學們', u'專任教師', u'畢業生', u'班級', u'班主任', u'報考', u'人才培養', u'高等教育', u'在校', u'孩子們', u'高校', u'老師', u'學員', u'招生', u'全 校', u'育人', u'學子', u'大學生', u'教學班', u'校長', u'入學', u'家長', u'在校學生', u'錄取', u'師生', u'青少年', u'同學', u'全日制', u'心理健康', u'招收', u'課堂', u'報名', u'青年', u'校友', u'先生', u' 義務教育', u'校園', u'校', u'成績', u'女士']
[u'慢性', u'疾病', u'糖尿病', u'急性', u'病變', u'腫瘤', u'高血壓', u'治療', u'炎症', u'併發症', u'心臟病', u'癌症', u'水腫', u'患者', u'病理', u'病因', u'腹瀉', u'嘔吐', u'咳嗽', u'症狀', u'便祕', u'臨牀表現', u'出血', u'病人', u'症', u'貧血', u'手術', u'頭痛', u'病例', u'療效', u'康復', u'發病', u'綜合徵', u'療法', u'診斷', u'發作', u'切除', u'病情', u'功效', u'損傷', u'病', u'傳染病', u'鑑別', u'感染', u'患', u'病毒', u'瘤', u'術', u'囊', u'畸形', u'部位', u'發熱', u'伴有', u'中毒']
[u'魔王', u'惡魔', u'妖', u'魔', u'冥', u'邪惡', u'吸血鬼', u'怪物', u'死神', u'鬼', u'幽靈', u'獵人', u'幻', u'魔獸', u'仙', u'黑暗', u'詛咒', u'封印', u'殭屍', u'毀滅', u'艦', u'艦隊', u'玄', u'咒', u' 精靈', u'幽', u'獸', u'艘', u'魔鬼', u'兇', u'騎士', u'BOSS', u'地獄', u'復活', u'國王', u'公主', u'女王', u'神仙', u'仙人', u'訣', u'召喚', u'屍', u'逍遙', u'魔法', u'怪', u'法術', u'神', u'王子', u'女神', u'魔力', u'靈', u'勇士', u'魂', u'邪', u'天使', u'怪獸', u'化身', u'屍體', u'武士', u'海盜', u'惡', u'戒', u'預言', u'死者', u'風流', u'光明', u'副本', u'變身', u'丹', u'殺手', u'正義', u'武功', u'荒']
顯然看起來聚類效果是很不錯的。
總結 #
寫了好幾天,終於把這篇博客寫完了,被我擱置了2年多的算法,總算是把它拿起來並且基本理解清楚了。
總的來說,InfoMap就是建立在轉移概率基礎上的一種聚類/社區發現算法,有清晰的信息論解釋(最小熵解釋),並且幾乎沒有任何超參(或者說超參就是轉移概率的構建),目前不少領域都開始關注到它,試圖用它來從數據中挖掘出有一定聯繫的模塊(哪個領域沒有節點和圖網絡的結構呢?)。當初我導師就是建議我用它來分析基因數據的,可惜我最終還是沒有完成這個目標~不管怎樣,就因爲它如此的優雅美妙,我覺得都應該去好好了解它。
最後,順便說一下,這已經是最小熵原理的第五篇文章了,它究竟還能走多遠?讓我們拭目以待~