




線程與進程區別
每個正在系統上運行的程序都是一個進程。每個進程包含一到多個線程。線程是一組指令的集合,或者是程序的特殊段,它可以在程序裏獨立執行,也可以把它理解爲代碼運行的上下文。所以線程基本上是輕量級的進程,它負責在單個程序裏執行多任務。通常由操作系統負責多個線程的調度和執行。
使用線程可以把佔據時間長的程序中的任務放到後臺去處理,程序的運行速度可能加快,在一些等待的任務實現上如用戶輸入、文件讀寫和網絡收發數據等,線程就比較有用了。在這種情況下可以釋放一些珍貴的資源如內存佔用等等。
如果有大量的線程,會影響性能,因爲操作系統需要在它們之間切換,更多的線程需要更多的內存空間,線程的中止需要考慮其對程序運行的影響。通常塊模型數據是在多個線程間共享的,需要防止線程死鎖情況的發生。
總結:進程是所有線程的集合,每一個線程是進程中的一條執行路徑。
爲什麼要使用多線程?
多線程應用場景?
主要能體現到多線程提高程序效率。如 迅雷多線程下載、數據庫連接池、分批發送短信等。
多線程有三大特性
原子性、可見性、有序性
什麼是原子性
即一個操作或者多個操作 要麼全部執行並且執行的過程不會被任何因素打斷,要麼就都不執行。
一個很經典的例子就是銀行賬戶轉賬問題:
比如從賬戶A向賬戶B轉1000元,那麼必然包括2個操作:從賬戶A減去1000元,往賬戶B加上1000元。這2個操作必須要具備原子性才能保證不出現一些意外的問題。
我們操作數據也是如此,比如i = i+1;其中就包括,讀取i的值,計算i,寫入i。這行代碼在Java中是不具備原子性的,則多線程運行肯定會出問題,所以也需要我們使用同步和lock這些東西來確保這個特性了。
原子性其實就是保證數據一致、線程安全一部分,
什麼是可見性
當多個線程訪問同一個變量時,一個線程修改了這個變量的值,其他線程能夠立即看得到修改後的值。
若兩個線程在不同的cpu,那麼線程1改變了i的值還沒刷新到主存,線程2又使用了i,那麼這個i值肯定還是之前的,線程1對變量的修改線程2未及時更新i的值這就是可見性問題。
什麼是有序性
程序執行的順序按照代碼的先後順序執行。
一般來說處理器爲了提高程序運行效率,可能會對輸入代碼進行優化,它不保證程序中各個語句的執行先後順序同代碼中的順序一致,但是它會保證程序最終執行結果和代碼順序執行的結果是一致的。如下:
int a = 10; //語句1
int r = 2; //語句2
a = a + 3; //語句3
r = a*a; //語句4
則因爲重排序,他還可能執行順序爲 2-1-3-4,1-3-2-4
但絕不可能 2-1-4-3,因爲這打破了依賴關係。
顯然重排序對單線程運行是不會有任何問題,而多線程就不一定了,所以我們在多線程編程時就得考慮這個問題了。
Java內存模型
共享內存模型指的就是Java內存模型(簡稱JMM),JMM決定一個線程對共享變量的寫入時,能對另一個線程可見。從抽象的角度來看,JMM定義了線程和主內存之間的抽象關係:線程之間的共享變量存儲在主內存(main memory)中,每個線程都有一個私有的本地內存(local memory),本地內存中存儲了該線程以讀/寫共享變量的副本。本地內存是JMM的一個抽象概念,並不真實存在。它涵蓋了緩存,寫緩衝區,寄存器以及其他的硬件和編譯器優化。

從上圖來看,線程A與線程B之間如要通信的話,必須要經歷下面2個步驟:
1. 首先,線程A把本地內存A中更新過的共享變量刷新到主內存中去。
2. 然後,線程B到主內存中去讀取線程A之前已更新過的共享變量。
下面通過示意圖來說明這兩個步驟:

如上圖所示,本地內存A和B有主內存中共享變量x的副本。假設初始時,這三個內存中的x值都爲0。線程A在執行時,把更新後的x值(假設值爲1)臨時存放在自己的本地內存A中。當線程A和線程B需要通信時,線程A首先會把自己本地內存中修改後的x值刷新到主內存中,此時主內存中的x值變爲了1。隨後,線程B到主內存中去讀取線程A更新後的x值,此時線程B的本地內存的x值也變爲了1。
從整體來看,這兩個步驟實質上是線程A在向線程B發送消息,而且這個通信過程必須要經過主內存。JMM通過控制主內存與每個線程的本地內存之間的交互,來爲java程序員提供內存可見性保證。
總結:什麼是Java內存模型:java內存模型簡稱jmm,定義了一個線程對另一個線程可見。共享變量存放在主內存中,每個線程都有自己的本地內存,當多個線程同時訪問一個數據的時候,可能本地內存沒有及時刷新到主內存,所以就會發生線程安全問題。
Volatile
什麼是Volatile
可見性也就是說一旦某個線程修改了該被volatile修飾的變量,它會保證修改的值會立即被更新到主存,當有其他線程需要讀取時,可以立即獲取修改之後的值。
在Java中爲了加快程序的運行效率,對一些變量的操作通常是在該線程的寄存器或是CPU緩存上進行的,之後纔會同步到主存中,而加了volatile修飾符的變量則是直接讀寫主存。
Volatile 保證了線程間共享變量的及時可見性,但不能保證原子性
Volatile特性
1.保證此變量對所有的線程的可見性,這裏的“可見性”,如本文開頭所述,當一個線程修改了這個變量的值,volatile 保證了新值能立即同步到主內存,以及每次使用前立即從主內存刷新。但普通變量做不到這點,普通變量的值在線程間傳遞均需要通過主內存(詳見:Java內存模型)來完成。
2.禁止指令重排序優化。有volatile修飾的變量,賦值後多執行了一個“load addl $0x0, (%esp)”操作,這個操作相當於一個內存屏障(指令重排序時不能把後面的指令重排序到內存屏障之前的位置),只有一個CPU訪問內存時,並不需要內存屏障;(什麼是指令重排序:是指CPU採用了允許將多條指令不按程序規定的順序分開發送給各相應電路單元處理)。
volatile 性能:
volatile 的讀性能消耗與普通變量幾乎相同,但是寫操作稍慢,因爲它需要在本地代碼中插入許多內存屏障指令來保證處理器不發生亂序執行。
(1)從而我們可以看出volatile雖然具有可見性但是並不能保證原子性。
(2)性能方面,synchronized關鍵字是防止多個線程同時執行一段代碼,就會影響程序執行效率,而volatile關鍵字在某些情況下性能要優於synchronized。
但是要注意volatile關鍵字是無法替代synchronized關鍵字的,因爲volatile關鍵字無法保證操作的原子性。
重排序
數據依賴性
如果兩個操作訪問同一個變量,且這兩個操作中有一個爲寫操作,此時這兩個操作之間就存在數據依賴性。數據依賴分下列三種類型:
|
名稱 |
代碼示例 |
說明 |
|
寫後讀 |
a = 1;b = a; |
寫一個變量之後,再讀這個位置。 |
|
寫後寫 |
a = 1;a = 2; |
寫一個變量之後,再寫這個變量。 |
|
讀後寫 |
a = b;b = 1; |
讀一個變量之後,再寫這個變量。 |
上面三種情況,只要重排序兩個操作的執行順序,程序的執行結果將會被改變。
前面提到過,編譯器和處理器可能會對操作做重排序。編譯器和處理器在重排序時,會遵守數據依賴性,編譯器和處理器不會改變存在數據依賴關係的兩個操作的執行順序。
注意,這裏所說的數據依賴性僅針對單個處理器中執行的指令序列和單個線程中執行的操作,不同處理器之間和不同線程之間的數據依賴性不被編譯器和處理器考慮。
as-if-serial語義
as-if-serial語義的意思指:不管怎麼重排序(編譯器和處理器爲了提高並行度),(單線程)程序的執行結果不能被改變。編譯器,runtime 和處理器都必須遵守as-if-serial語義。
爲了遵守as-if-serial語義,編譯器和處理器不會對存在數據依賴關係的程序操作做重排序,因爲這種重排序會改變執行結果。但是,如果操作之間不存在數據依賴關係,這些操作可能被編譯器和處理器重排序。爲了具體說明,請看下面計算圓面積的代碼示例:
|
double pi = 3.14; //A double r = 1.0; //B double area = pi * r * r; //C |
上面三個操作的數據依賴關係如下圖所示:


如左圖所示,A和C之間存在數據依賴關係,同時B和C之間也存在數據依賴關係。因此在最終執行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的結果將會被改變)。但A和B之間沒有數據依賴關係,編譯器和處理器可以重排序A和B之間的執行順序,右圖是該程序的兩種執行順序。
as-if-serial語義把單線程程序保護了起來,遵守as-if-serial語義的編譯器,runtime 和處理器共同爲編寫單線程程序的程序員創建了一個幻覺:單線程程序是按程序的順序來執行的。as-if-serial語義使單線程程序員無需擔心重排序會干擾他們,也無需擔心內存可見性問題。
程序順序規則
根據happens- before的程序順序規則,上面計算圓的面積的示例代碼存在三個happens- before關係:
1. A happens- before B;
2. B happens- before C;
3. A happens- before C;
這裏的第3個happens- before關係,是根據happens- before的傳遞性推導出來的。
這裏A happens- before B,但實際執行時B卻可以排在A之前執行(看上面的重排序後的執行順序)。如果A happens- before B,JMM並不要求A一定要在B之前執行。JMM僅僅要求前一個操作(執行的結果)對後一個操作可見,且前一個操作按順序排在第二個操作之前。這裏操作A的執行結果不需要對操作B可見;而且重排序操作A和操作B後的執行結果,與操作A和操作B按happens- before順序執行的結果一致。在這種情況下,JMM會認爲這種重排序並不非法(not illegal),JMM允許這種重排序。
在計算機中,軟件技術和硬件技術有一個共同的目標:在不改變程序執行結果的前提下,儘可能的開發並行度。編譯器和處理器遵從這一目標,從happens- before的定義我們可以看出,JMM同樣遵從這一目標。
重排序對多線程的影響
現在讓我們來看看,重排序是否會改變多線程程序的執行結果。看下面的示例代碼:
|
class ReorderExample { int a = 0; boolean flag = false;
public void writer() { a = 1; //1 flag = true; //2 }
Public void reader() { if (flag) { //3 int i = a * a; //4 …… } } } |
flag變量是個標記,用來標識變量a是否已被寫入。這裏假設有兩個線程A和B,A首先執行writer()方法,隨後B線程接着執行reader()方法。線程B在執行操作4時,能否看到線程A在操作1對共享變量a的寫入?
答案是:不一定能看到。
由於操作1和操作2沒有數據依賴關係,編譯器和處理器可以對這兩個操作重排序;同樣,操作3和操作4沒有數據依賴關係,編譯器和處理器也可以對這兩個操作重排序。讓我們先來看看,當操作1和操作2重排序時,可能會產生什麼效果?請看下面的程序執行時序圖:

如上圖所示,操作1和操作2做了重排序。程序執行時,線程A首先寫標記變量flag,隨後線程B讀這個變量。由於條件判斷爲真,線程B將讀取變量a。此時,變量a還根本沒有被線程A寫入,在這裏多線程程序的語義被重排序破壞了!
紅色的虛箭線表示錯誤的讀操作,用綠色的虛箭線表示正確的讀操作。
下面再讓我們看看,當操作3和操作4重排序時會產生什麼效果(藉助這個重排序,可以順便說明控制依賴性)。下面是操作3和操作4重排序後,程序的執行時序圖:

在程序中,操作3和操作4存在控制依賴關係。當代碼中存在控制依賴性時,會影響指令序列執行的並行度。爲此,編譯器和處理器會採用猜測(Speculation)執行來克服控制相關性對並行度的影響。以處理器的猜測執行爲例,執行線程B的處理器可以提前讀取並計算a*a,然後把計算結果臨時保存到一個名爲重排序緩衝(reorder buffer ROB)的硬件緩存中。當接下來操作3的條件判斷爲真時,就把該計算結果寫入變量i中。
從圖中我們可以看出,猜測執行實質上對操作3和4做了重排序。重排序在這裏破壞了多線程程序的語義!
在單線程程序中,對存在控制依賴的操作重排序,不會改變執行結果(這也是as-if-serial語義允許對存在控制依賴的操作做重排序的原因);但在多線程程序中,對存在控制依賴的操作重排序,可能會改變程序的執行結果。
多線程之間如何實現通訊
什麼是多線程之間通訊?
多線程之間通訊,其實就是多個線程在操作同一個資源,但是操作的動作不同。
wait、notify方法
1.因爲涉及到對象鎖,wait、notify一定要在synchronized裏面進行使用。
2.wait必須暫定當前正在執行的線程,並釋放資源鎖,讓其他線程可以有機會運行
3. notify/notifyall: 喚醒鎖池中的線程,使之運行
注意:一定要在線程同步中使用,並且是同一個鎖的資源
wait與sleep區別
對於sleep()方法,我們首先要知道該方法是屬於Thread類中的。而wait()方法,則是屬於Object類中的。
sleep()方法導致了程序暫停執行指定的時間,讓出cpu給其他線程,但是他的監控狀態依然保持者,當指定的時間到了又會自動恢復運行狀態。也就是在調用sleep()方法的過程中,線程不會釋放對象鎖。
而當調用wait()方法的時候,線程會放棄對象鎖,進入等待此對象的等待鎖定池,只有針對此對象調用notify()方法後本線程才進入對象鎖定池準備,獲取對象鎖後才能進入運行狀態。
Lock鎖
在 jdk1.5 之後,併發包中新增了 Lock 接口(以及相關實現類)用來實現鎖功能,Lock 接口提供了與 synchronized 關鍵字類似的同步功能,但需要在使用時手動獲取鎖和釋放鎖。
Lock寫法
|
Lock lock = new ReentrantLock(); lock.lock(); try{ //可能會出現線程安全的操作 }finally{ //一定在finally中釋放鎖 //也不能把獲取鎖在try中進行,因爲有可能在獲取鎖的時候拋出異常 lock.ublock(); }
|
Lock與synchronized 關鍵字的區別
Lock 接口可以嘗試非阻塞地獲取鎖,當前線程嘗試獲取鎖。如果這一時刻鎖沒有被其他線程獲取到,則成功獲取並持有鎖。
Lock 接口能被中斷地獲取鎖 與 synchronized 不同,獲取到鎖的線程能夠響應中斷,當獲取到的鎖的線程被中斷時,中斷將會被異常拋出,同時鎖會被釋放。
Lock 接口在指定的截止時間之前獲取鎖,如果截止時間到了依舊無法獲取鎖,則返回。
併發包
(計數器)CountDownLatch
CountDownLatch 類位於java.util.concurrent包下,利用它可以實現類似計數器的功能。比如有一個任務A,它要等待其他4個任務執行完畢之後才能執行,此時就可以利用CountDownLatch來實現這種功能了。CountDownLatch是通過一個計數器來實現的,計數器的初始值爲線程的數量。每當一個線程完成了自己的任務後,計數器的值就會減1。當計數器值到達0時,它表示所有的線程已經完成了任務,然後在閉鎖上等待的線程就可以恢復執行任務。
|
public static void main(String[] args) throws InterruptedException { CountDownLatch countDownLatch = new CountDownLatch(2); new Thread(new Runnable() {
@Override public void run() { System.out.println(Thread.currentThread().getName() + ",子線程開始執行..."); countDownLatch.countDown(); System.out.println(Thread.currentThread().getName() + ",子線程結束執行..."); } }).start();
new Thread(new Runnable() {
@Override public void run() { System.out.println(Thread.currentThread().getName() + ",子線程開始執行..."); countDownLatch.countDown();//計數器值每次減去1 System.out.println(Thread.currentThread().getName() + ",子線程結束執行..."); } }).start(); countDownLatch.await();// 減去爲0,恢復任務繼續執行 System.out.println("兩個子線程執行完畢...."); System.out.println("主線程繼續執行....."); for (int i = 0; i <10; i++) { System.out.println("main,i:"+i); } } |
(屏障)CyclicBarrier
CyclicBarrier初始化時規定一個數目,然後計算調用了CyclicBarrier.await()進入等待的線程數。當線程數達到了這個數目時,所有進入等待狀態的線程被喚醒並繼續。
CyclicBarrier就象它名字的意思一樣,可看成是個障礙, 所有的線程必須到齊後才能一起通過這個障礙。
CyclicBarrier初始時還可帶一個Runnable的參數, 此Runnable任務在CyclicBarrier的數目達到後,所有其它線程被喚醒前被執行。
|
class Writer extends Thread { private CyclicBarrier cyclicBarrier; public Writer(CyclicBarrier cyclicBarrier){ this.cyclicBarrier=cyclicBarrier; } @Override public void run() { System.out.println("線程" + Thread.currentThread().getName() + ",正在寫入數據"); try { Thread.sleep(3000); } catch (Exception e) { // TODO: handle exception } System.out.println("線程" + Thread.currentThread().getName() + ",寫入數據成功.....");
try { cyclicBarrier.await(); } catch (Exception e) { } System.out.println("所有線程執行完畢.........."); }
}
public class Test001 {
public static void main(String[] args) { CyclicBarrier cyclicBarrier=new CyclicBarrier(5); for (int i = 0; i < 5; i++) { Writer writer = new Writer(cyclicBarrier); writer.start(); } }
}
|
(計數信號量)Semaphore
Semaphore是一種基於計數的信號量。它可以設定一個閾值,基於此,多個線程競爭獲取許可信號,做自己的申請後歸還,超過閾值後,線程申請許可信號將會被阻塞。Semaphore可以用來構建一些對象池,資源池之類的,比如數據庫連接池,我們也可以創建計數爲1的Semaphore,將其作爲一種類似互斥鎖的機制,這也叫二元信號量,表示兩種互斥狀態。它的用法如下:
availablePermits函數用來獲取當前可用的資源數量
wc.acquire(); //申請資源
wc.release();// 釋放資源
|
// 創建一個計數閾值爲5的信號量對象 // 只能5個線程同時訪問 Semaphore semp = new Semaphore(5);
try { // 申請許可 semp.acquire(); try { // 業務邏輯 } catch (Exception e) {
} finally { // 釋放許可 semp.release(); } } catch (InterruptedException e) {
} |
併發隊列
在併發隊列上JDK提供了兩套實現,一個是以ConcurrentLinkedQueue爲代表的高性能隊列非阻塞,一個是以BlockingQueue接口爲代表的阻塞隊列,無論哪種都繼承自Queue。

阻塞隊列與非阻塞隊
阻塞隊列與普通隊列的區別在於,當隊列是空的時,從隊列中獲取元素的操作將會被阻塞,或者當隊列是滿時,往隊列裏添加元素的操作會被阻塞。試圖從空的阻塞隊列中獲取元素的線程將會被阻塞,直到其他的線程往空的隊列插入新的元素。同樣,試圖往已滿的阻塞隊列中添加新元素的線程同樣也會被阻塞,直到其他的線程使隊列重新變得空閒起來,如從隊列中移除一個或者多個元素,或者完全清空隊列。
1.ArrayDeque, (數組雙端隊列)
2.PriorityQueue, (優先級隊列)
3.ConcurrentLinkedQueue, (基於鏈表的併發隊列)
4.DelayQueue, (延期阻塞隊列)(阻塞隊列實現了BlockingQueue接口)
5.ArrayBlockingQueue, (基於數組的併發阻塞隊列)
6.LinkedBlockingQueue, (基於鏈表的FIFO阻塞隊列)
7.LinkedBlockingDeque, (基於鏈表的FIFO雙端阻塞隊列)
8.PriorityBlockingQueue, (帶優先級的無界阻塞隊列)
9.SynchronousQueue (併發同步阻塞隊列)
ConcurrentLinkedDeque
ConcurrentLinkedQueue : 是一個適用於高併發場景下的隊列,通過無鎖的方式,實現了高併發狀態下的高性能,通常ConcurrentLinkedQueue性能好於BlockingQueue.它是一個基於鏈接節點的無界線程安全隊列。該隊列的元素遵循先進先出的原則。頭是最先加入的,尾是最近加入的,該隊列不允許null元素。ConcurrentLinkedQueue重要方法:add 和offer() 都是加入元素的方法(在ConcurrentLinkedQueue中這倆個方法沒有任何區別)poll() 和peek() 都是取頭元素節點,區別在於前者會刪除元素,後者不會。
|
ConcurrentLinkedDeque q = new ConcurrentLinkedDeque(); q.offer("張三"); q.offer("李四"); q.offer("錢五"); q.offer("趙六"); //從頭獲取元素,刪除該元素 System.out.println(q.poll()); //從頭獲取元素,不刪除該元素 System.out.println(q.peek()); //獲取總長度 System.out.println(q.size()); |
BlockingQueue
阻塞隊列(BlockingQueue)是一個支持兩個附加操作的隊列。這兩個附加的操作是:
1. 隊列爲空時,獲取元素的線程會等待隊列變爲非空;
2. 當隊列滿時,存儲元素的線程會等待隊列可用;
在Java中,BlockingQueue的接口位於java.util.concurrent 包中(在Java5版本開始提供),由上面介紹的阻塞隊列的特性可知,阻塞隊列是線程安全的。在多線程領域,所謂阻塞,在某些情況下會掛起線程(即阻塞),一旦條件滿足,被掛起的線程又會自動被喚醒。
多線程環境中,通過隊列可以很容易實現數據共享,比如經典的“生產者”和“消費者”模型中,通過隊列可以很便利地實現兩者之間的數據共享。
假設我們有若干生產者線程,另外又有若干個消費者線程。如果生產者線程需要把準備好的數據共享給消費者線程,利用隊列的方式來傳遞數據,就可以很方便地解決他們之間的數據共享問題。但如果生產者和消費者在某個時間段內,萬一發生數據處理速度不匹配的情況呢?理想情況下,如果生產者產出數據的速度大於消費者消費的速度,並且當生產出來的數據累積到一定程度的時候,那麼生產者必須暫停等待一下(阻塞生產者線程),以便等待消費者線程把累積的數據處理完畢,反之亦然。
使用BlockingQueue模擬生產者與消費者
|
class ProducerThread implements Runnable { private BlockingQueue<String> blockingQueue; private AtomicInteger count = new AtomicInteger(); private volatile boolean FLAG = true;
public ProducerThread(BlockingQueue<String> blockingQueue) { this.blockingQueue = blockingQueue; }
@Override public void run() { System.out.println(Thread.currentThread().getName() + "生產者開始啓動...."); while (FLAG) { String data = count.incrementAndGet() + ""; try { boolean offer = blockingQueue.offer(data, 2, TimeUnit.SECONDS); if (offer) { System.out.println(Thread.currentThread().getName() + ",生產隊列" + data + "成功.."); } else { System.out.println(Thread.currentThread().getName() + ",生產隊列" + data + "失敗.."); } Thread.sleep(1000); } catch (Exception e) {
} } System.out.println(Thread.currentThread().getName() + ",生產者線程停止..."); }
public void stop() { this.FLAG = false; }
}
class ConsumerThread implements Runnable { private volatile boolean FLAG = true; private BlockingQueue<String> blockingQueue;
public ConsumerThread(BlockingQueue<String> blockingQueue) { this.blockingQueue = blockingQueue; }
@Override public void run() { System.out.println(Thread.currentThread().getName() + "消費者開始啓動...."); while (FLAG) { try { String data = blockingQueue.poll(2, TimeUnit.SECONDS); if (data == null || data == "") { FLAG = false; System.out.println("消費者超過2秒時間未獲取到消息."); return; } System.out.println("消費者獲取到隊列信息成功,data:" + data);
} catch (Exception e) { // TODO: handle exception } } }
}
public class Test0008 {
public static void main(String[] args) { BlockingQueue<String> blockingQueue = new LinkedBlockingQueue<>(3); ProducerThread producerThread = new ProducerThread(blockingQueue); ConsumerThread consumerThread = new ConsumerThread(blockingQueue); Thread t1 = new Thread(producerThread); Thread t2 = new Thread(consumerThread); t1.start(); t2.start(); //10秒後 停止線程.. try { Thread.sleep(10*1000); producerThread.stop(); } catch (Exception e) { // TODO: handle exception } }
} |
ArrayBlockingQueue
ArrayBlockingQueue是一個有邊界的阻塞隊列,它的內部實現是一個數組。有邊界的意思是它的容量是有限的,我們必須在其初始化的時候指定它的容量大小,容量大小一旦指定就不可改變。
ArrayBlockingQueue是以先進先出的方式存儲數據,最新插入的對象是尾部,最新移出的對象是頭部。下面
是一個初始化和使用ArrayBlockingQueue的例子:
|
<String> arrays = new ArrayBlockingQueue<String>(3); arrays.add("李四"); arrays.add("錢五"); arrays.add("趙六"); // 添加阻塞隊列 arrays.offer("張三", 1, TimeUnit.SECONDS); |
LinkedBlockingQueue
LinkedBlockingQueue阻塞隊列大小的配置是可選的,如果我們初始化時指定一個大小,它就是有邊界的,如果不指定,它就是無邊界的。說是無邊界,其實是採用了默認大小爲Integer.MAX_VALUE的容量 。它的內部實現是一個鏈表。
和ArrayBlockingQueue一樣,LinkedBlockingQueue 也是以先進先出的方式存儲數據,最新插入的對象是尾部,最新移出的對象是頭部。
PriorityBlockingQueue
PriorityBlockingQueue是一個沒有邊界的隊列,它的排序規則和java.util.PriorityQueue一樣。需要注意,PriorityBlockingQueue中允許插入null對象。
所有插入PriorityBlockingQueue的對象必須實現 java.lang.Comparable接口,隊列優先級的排序規則就是按照我們對這個接口的實現來定義的。
另外,我們可以從PriorityBlockingQueue獲得一個迭代器Iterator,但這個迭代器並不保證按照優先級順序進行迭代。
SynchronousQueue
SynchronousQueue隊列內部僅允許容納一個元素。當一個線程插入一個元素後會被阻塞,除非這個元素被另一個線程消費。
線程池
什麼是線程池
Java中的線程池是運用場景最多的併發框架,幾乎所有需要異步或併發執行任務的程序都可以使用線程池。在開發過程中,合理地使用線程池能夠帶來3個好處。
第一:降低資源消耗。通過重複利用已創建的線程降低線程創建和銷燬造成的消耗。線程是稀缺資源,如果無限制地創建,不僅會消耗系統資源,還會降低系統的穩定性。
第二:提高響應速度。當任務到達時,任務可以不需要等到線程創建就能立即執行。
第三:提高線程的可管理性。使用線程池可以進行統一分配、調優和監控。
線程池作用
線程池是爲突然大量爆發的線程設計的,通過有限的幾個固定線程爲大量的操作服務,減少了創建和銷燬線程所需的時間,從而提高效率。
線程池的分類
線程池四種創建方式
Executor框架的最頂層實現是ThreadPoolExecutor類, Java通過Executors(jdk1.5併發包)提供四種線程池,分別爲:
newCachedThreadPool創建一個可緩存線程池,如果線程池長度超過處理需要,可靈活回收空閒線程,若無可回收,則新建線程。
newFixedThreadPool 創建一個定長線程池,可控制線程最大併發數,超出的線程會在隊列中等待。
newScheduledThreadPool 創建一個定長線程池,支持定時及週期性任務執行。
newSingleThreadExecutor 創建一個單線程化的線程池,它只會用唯一的工作線程來執行任務,保證所有任務按照指定順序(FIFO, LIFO, 優先級)執行。
newCachedThreadPool
創建一個可緩存線程池,如果線程池長度超過處理需要,可靈活回收空閒線程,若無可回收,則新建線程。示例代碼如下:
|
// 無限大小線程池 jvm自動回收 ExecutorService newCachedThreadPool = Executors.newCachedThreadPool(); for (int i = 0; i < 10; i++) { final int temp = i; newCachedThreadPool.execute(new Runnable() {
@Override public void run() { try { Thread.sleep(100); } catch (Exception e) { // TODO: handle exception } System.out.println(Thread.currentThread().getName() + ",i:" + temp);
} }); } |
總結: 線程池爲無限大,當執行第二個任務時第一個任務已經完成,會複用執行第一個任務的線程,而不用每次新建線程。
newFixedThreadPool
創建一個定長線程池,可控制線程最大併發數,超出的線程會在隊列中等待。示例代碼如下:
|
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(5); for (int i = 0; i < 10; i++) { final int temp = i; newFixedThreadPool.execute(new Runnable() {
@Override public void run() { System.out.println(Thread.currentThread().getId() + ",i:" + temp);
} }); } |
總結:因爲線程池大小爲3,每個任務輸出index後sleep 2秒,所以每兩秒打印3個數字。定長線程池的大小最好根據系統資源進行設置。如Runtime.getRuntime().availableProcessors()
newScheduledThreadPool
創建一個定長線程池,支持定時及週期性任務執行。延遲執行示例代碼如下:
|
ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(5); for (int i = 0; i < 10; i++) { final int temp = i; newScheduledThreadPool.schedule(new Runnable() { public void run() { System.out.println("i:" + temp); } }, 3, TimeUnit.SECONDS); } |
表示延遲3秒執行。
newSingleThreadExecutor
創建一個單線程化的線程池,它只會用唯一的工作線程來執行任務,保證所有任務按照指定順序(FIFO, LIFO, 優先級)執行。示例代碼如下:
|
ExecutorService newSingleThreadExecutor = Executors.newSingleThreadExecutor(); for (int i = 0; i < 10; i++) { final int index = i; newSingleThreadExecutor.execute(new Runnable() {
@Override public void run() { System.out.println("index:" + index); try { Thread.sleep(200); } catch (Exception e) { // TODO: handle exception } } }); } |
注意: 結果依次輸出,相當於順序執行各個任務。
線程池原理剖析
提交一個任務到線程池中,線程池的處理流程如下:
1、判斷線程池裏的核心線程是否都在執行任務,如果不是(核心線程空閒或者還有核心線程沒有被創建)則創建一個新的工作線程來執行任務。如果核心線程都在執行任務,則進入下個流程。
2、線程池判斷工作隊列是否已滿,如果工作隊列沒有滿,則將新提交的任務存儲在這個工作隊列裏。如果工作隊列滿了,則進入下個流程。
3、判斷線程池裏的線程是否都處於工作狀態,如果沒有,則創建一個新的工作線程來執行任務。如果已經滿了,則交給飽和策略來處理這個任務。
TOTO: 線程運行狀態圖片
自定義線程線程池
如果當前線程池中的線程數目小於corePoolSize,則每來一個任務,就會創建一個線程去執行這個任務;
如果當前線程池中的線程數目>=corePoolSize,則每來一個任務,會嘗試將其添加到任務緩存隊列當中,若添加成功,則該任務會等待空閒線程將其取出去執行;若添加失敗(一般來說是任務緩存隊列已滿),則會嘗試創建新的線程去執行這個任務;
如果隊列已經滿了,則在總線程數不大於maximumPoolSize的前提下,則創建新的線程
如果當前線程池中的線程數目達到maximumPoolSize,則會採取任務拒絕策略進行處理;
如果線程池中的線程數量大於 corePoolSize時,如果某線程空閒時間超過keepAliveTime,線程將被終止,直至線程池中的線程數目不大於corePoolSize;如果允許爲核心池中的線程設置存活時間,那麼核心池中的線程空閒時間超過keepAliveTime,線程也會被終止。
|
public class Test0007 {
public static void main(String[] args) { ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 2, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(3)); for (int i = 1; i <= 6; i++) { TaskThred t1 = new TaskThred("任務" + i); executor.execute(t1); } executor.shutdown(); } }
class TaskThred implements Runnable { private String taskName;
public TaskThred(String taskName) { this.taskName = taskName; }
@Override public void run() { System.out.println(Thread.currentThread().getName()+taskName); }
} |
合理配置線程池
CPU密集
CPU密集的意思是該任務需要大量的運算,而沒有阻塞,CPU一直全速運行。
CPU密集任務只有在真正的多核CPU上纔可能得到加速(通過多線程),而在單核CPU上,無論你開幾個模擬的多線程,該任務都不可能得到加速,因爲CPU總的運算能力就那些。
IO密集
IO密集型,即該任務需要大量的IO,即大量的阻塞。在單線程上運行IO密集型的任務會導致浪費大量的CPU運算能力浪費在等待。所以在IO密集型任務中使用多線程可以大大的加速程序運行,即時在單核CPU上,這種加速主要就是利用了被浪費掉的阻塞時間。
如何合理的設置線程池大小。
要想合理的配置線程池的大小,首先得分析任務的特性,可以從以下幾個角度分析:
1.任務的性質:CPU密集型任務、IO密集型任務、混合型任務。
2.任務的優先級:高、中、低。
3.任務的執行時間:長、中、短。
4.任務的依賴性:是否依賴其他系統資源,如數據庫連接等。
性質不同的任務可以交給不同規模的線程池執行。
對於不同性質的任務來說,CPU密集型任務應配置儘可能小的線程,如配置CPU個數+1的線程數,IO密集型任務應配置儘可能多的線程,因爲IO操作不佔用CPU,不要讓CPU閒下來,應加大線程數量,如配置兩倍CPU個數+1,而對於混合型的任務,如果可以拆分,拆分成IO密集型和CPU密集型分別處理,前提是兩者運行的時間是差不多的,如果處理時間相差很大,則沒必要拆分了。
若任務對其他系統資源有依賴,如某個任務依賴數據庫的連接返回的結果,這時候等待的時間越長,則CPU空閒的時間越長,那麼線程數量應設置得越大,才能更好的利用CPU。
當然具體合理線程池值大小,需要結合系統實際情況,在大量的嘗試下比較才能得出,以上只是前人總結的規律。
最佳線程數目 = ((線程等待時間+線程CPU時間)/線程CPU時間 )* CPU數目
比如平均每個線程CPU運行時間爲0.5s,而線程等待時間(非CPU運行時間,比如IO)爲1.5s,CPU核心數爲8,那麼根據上面這個公式估算得到:((0.5+1.5)/0.5)*8=32。這個公式進一步轉化爲:
最佳線程數目 = (線程等待時間與線程CPU時間之比 + 1)* CPU數目
可以得出一個結論:
線程等待時間所佔比例越高,需要越多線程。線程CPU時間所佔比例越高,需要越少線程。
以上公式與之前的CPU和IO密集型任務設置線程數基本吻合。
CPU密集型時,任務可以少配置線程數,大概和機器的cpu核數相當,這樣可以使得每個線程都在執行任務
IO密集型時,大部分線程都阻塞,故需要多配置線程數,2*cpu核數
操作系統之名稱解釋:
某些進程花費了絕大多數時間在計算上,而其他則在等待I/O上花費了大多是時間,
前者稱爲計算密集型(CPU密集型)computer-bound,後者稱爲I/O密集型,I/O-bound。
Java鎖的深度化
鎖作爲併發共享數據,保證一致性的工具,有很多種類型,如下:
悲觀鎖、樂觀鎖、排他鎖、重入鎖(遞歸鎖)
場景
當多個請求同時操作數據庫時,首先將訂單狀態改爲已支付,在金額加上200,在同時併發場景查詢條件下,會造成重複通知。
悲觀鎖與樂觀鎖
悲觀鎖:總是假設最壞的情況,每次取數據時都認爲其他線程會修改,所以都會加鎖(讀鎖、寫鎖、行鎖等),當其他線程想要訪問數據時,都需要阻塞掛起。可以依靠數據庫實現,如行鎖、讀鎖和寫鎖等,都是在操作之前加鎖,在Java中,synchronized的思想也是悲觀鎖。
樂觀鎖:總是認爲不會產生併發問題,每次去取數據的時候總認爲不會有其他線程對數據進行修改,因此不會上鎖,但是在更新時會判斷其他線程在這之前有沒有對數據進行修改,一般會使用版本號機制或CAS操作實現。
version方式:一般是在數據表中加上一個數據版本號version字段,表示數據被修改的次數,當數據被修改時,version值會加一。當線程A要更新數據值時,在讀取數據的同時也會讀取version值,在提交更新時,若剛纔讀取到的version值爲當前數據庫中的version值相等時才更新,否則重試更新操作,直到更新成功。
核心SQL語句
update table set x=x+1, version=version+1 where id=#{id} and version=#{version};
CAS操作方式:即compare and swap 或者 compare and set,涉及到三個操作數,數據所在的內存值,預期值,新值。當需要更新時,判斷當前內存值與之前取到的值是否相等,若相等,則用新值更新,若失敗則重試,一般情況下是一個自旋操作,即不斷的重試。
重入鎖
重入鎖,也叫做遞歸鎖,指的是同一線程外層函數獲得鎖之後,內層遞歸函數仍然有獲取該鎖的代碼,但不受影響。
在JAVA環境下 ReentrantLock(顯式鎖、輕量級鎖)和Synchronized (內置鎖、重量級鎖)都是 可重入鎖
|
public class Test implements Runnable { public synchronized void get() { System.out.println("name:" + Thread.currentThread().getName() + " get();"); set(); }
public synchronized void set() { System.out.println("name:" + Thread.currentThread().getName() + " set();"); }
@Override
public void run() { get(); }
public static void main(String[] args) { Test ss = new Test(); new Thread(ss).start(); new Thread(ss).start(); new Thread(ss).start(); new Thread(ss).start(); } } |
|
public class Test02 extends Thread { ReentrantLock lock = new ReentrantLock(); public void get() { lock.lock(); System.out.println(Thread.currentThread().getId()); set(); lock.unlock(); } public void set() { lock.lock(); System.out.println(Thread.currentThread().getId()); lock.unlock(); } @Override public void run() { get(); } public static void main(String[] args) { Test ss = new Test(); new Thread(ss).start(); new Thread(ss).start(); new Thread(ss).start(); } } |
讀寫鎖
相比Java中的鎖(Locks in Java)裏Lock實現,讀寫鎖更復雜一些。假設你的程序中涉及到對一些共享資源的讀和寫操作,且寫操作沒有讀操作那麼頻繁。在沒有寫操作的時候,兩個線程同時讀一個資源沒有任何問題,所以應該允許多個線程能在同時讀取共享資源。但是如果有一個線程想去寫這些共享資源,就不應該再有其它線程對該資源進行讀或寫(讀-讀能共存,讀-寫不能共存,寫-寫不能共存)。這就需要一個讀/寫鎖來解決這個問題。Java5在java.util.concurrent包中已經包含了讀寫鎖。儘管如此,我們還是應該瞭解其實現背後的原理。
|
public class Cache { static Map<String, Object> map = new HashMap<String, Object>(); static ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); static Lock r = rwl.readLock(); static Lock w = rwl.writeLock();
// 獲取一個key對應的value public static final Object get(String key) { r.lock(); try { System.out.println("正在做讀的操作,key:" + key + " 開始"); Thread.sleep(100); Object object = map.get(key); System.out.println("正在做讀的操作,key:" + key + " 結束"); System.out.println(); return object; } catch (InterruptedException e) {
} finally { r.unlock(); } return key; }
// 設置key對應的value,並返回舊有的value public static final Object put(String key, Object value) { w.lock(); try {
System.out.println("正在做寫的操作,key:" + key + ",value:" + value + "開始."); Thread.sleep(100); Object object = map.put(key, value); System.out.println("正在做寫的操作,key:" + key + ",value:" + value + "結束."); System.out.println(); return object; } catch (InterruptedException e) {
} finally { w.unlock(); } return value; }
// 清空所有的內容 public static final void clear() { w.lock(); try { map.clear(); } finally { w.unlock(); } }
public static void main(String[] args) { new Thread(new Runnable() {
@Override public void run() { for (int i = 0; i < 10; i++) { Cache.put(i + "", i + ""); }
} }).start(); new Thread(new Runnable() {
@Override public void run() { for (int i = 0; i < 10; i++) { Cache.get(i + ""); }
} }).start(); } } |
CAS無鎖機制
(1)與鎖相比,使用比較交換(下文簡稱CAS)會使程序看起來更加複雜一些。但由於其非阻塞性,它對死鎖問題天生免疫,並且,線程間的相互影響也遠遠比基於鎖的方式要小。更爲重要的是,使用無鎖的方式完全避免了鎖競爭帶來的系統開銷和線程間頻繁調度帶來的開銷,因此,它要比基於鎖的方式擁有更優越的性能。
(2)無鎖的好處:
第一,在高併發的情況下,它比有鎖的程序擁有更好的性能;
第二,它天生就是死鎖免疫的。
就憑藉這兩個優勢,就值得我們冒險嘗試使用無鎖的併發。
(3)CAS算法的過程是這樣:它包含三個參數CAS(V,E,N): V表示要更新的變量,E表示預期值,N表示新值。僅當V值等於E值時,纔會將V的值設爲N,如果V值和E值不同,則說明已經有其他線程做了更新,則當前線程什麼都不做。最後,CAS返回當前V的真實值。
(4)CAS操作是抱着樂觀的態度進行的,它總是認爲自己可以成功完成操作。當多個線程同時使用CAS操作一個變量時,只有一個會勝出,併成功更新,其餘均會失敗。失敗的線程不會被掛起,僅是被告知失敗,並且允許再次嘗試,當然也允許失敗的線程放棄操作。基於這樣的原理,CAS操作即使沒有鎖,也可以發現其他線程對當前線程的干擾,並進行恰當的處理。
(5)簡單地說,CAS需要你額外給出一個期望值,也就是你認爲這個變量現在應該是什麼樣子的。如果變量不是你想象的那樣,那說明它已經被別人修改過了。你就重新讀取,再次嘗試修改就好了。
(6)在硬件層面,大部分的現代處理器都已經支持原子化的CAS指令。在JDK 5.0以後,虛擬機便可以使用這個指令來實現併發操作和併發數據結構,並且,這種操作在虛擬機中可以說是無處不在。
|
/** * Atomically increments by one the current value. * * @return the updated value */ public final int incrementAndGet() { for (;;) { //獲取當前值 int current = get(); //設置期望值 int next = current + 1; //調用Native方法compareAndSet,執行CAS操作 if (compareAndSet(current, next)) //成功後纔會返回期望值,否則無線循環 return next; } } |
自旋鎖
自旋鎖是採用讓當前線程不停地的在循環體內執行實現的,當循環的條件被其他線程改變時 才能進入臨界區。如下
|
private AtomicReference<Thread> sign = new AtomicReference<>(); public void lock() { Thread current = Thread.currentThread(); while (!sign.compareAndSet(null, current)) { } } public void unlock() { Thread current = Thread.currentThread(); sign.compareAndSet(current, null); } |
|
public class Test implements Runnable { static int sum; private SpinLock lock;
public Test(SpinLock lock) { this.lock = lock; }
/** * @param args * @throws InterruptedException */ public static void main(String[] args) throws InterruptedException { SpinLock lock = new SpinLock(); for (int i = 0; i < 100; i++) { Test test = new Test(lock); Thread t = new Thread(test); t.start(); }
Thread.currentThread().sleep(1000); System.out.println(sum); }
@Override public void run() { this.lock.lock(); this.lock.lock(); sum++; this.lock.unlock(); this.lock.unlock(); }
} |
當一個線程 調用這個不可重入的自旋鎖去加鎖的時候沒問題,當再次調用lock()的時候,因爲自旋鎖的持有引用已經不爲空了,該線程對象會誤認爲是別人的線程持有了自旋鎖
使用了CAS原子操作,lock函數將owner設置爲當前線程,並且預測原來的值爲空。unlock函數將owner設置爲null,並且預測值爲當前線程。
當有第二個線程調用lock操作時由於owner值不爲空,導致循環一直被執行,直至第一個線程調用unlock函數將owner設置爲null,第二個線程才能進入臨界區。
由於自旋鎖只是將當前線程不停地執行循環體,不進行線程狀態的改變,所以響應速度更快。但當線程數不停增加時,性能下降明顯,因爲每個線程都需要執行,佔用CPU時間。如果線程競爭不激烈,並且保持鎖的時間段。適合使用自旋鎖。
分佈式鎖
如果想在不同的jvm中保證數據同步,使用分佈式鎖技術。
有數據庫實現、緩存實現、Zookeeper分佈式鎖
Callable
在Java中,創建線程一般有兩種方式,一種是繼承Thread類,一種是實現Runnable接口。然而,這兩種方式的缺點是在線程任務執行結束後,無法獲取執行結果。我們一般只能採用共享變量或共享存儲區以及線程通信的方式實現獲得任務結果的目的。
不過,Java中,也提供了使用Callable和Future來實現獲取任務結果的操作。Callable用來執行任務,產生結果,而Future用來獲得結果。
Callable接口與Runnable接口是否相似,查看源碼,可知Callable接口的定義如下:
|
@FunctionalInterface public interface Callable<V> { /** * Computes a result, or throws an exception if unable to do so. * * @return computed result * @throws Exception if unable to compute a result */ V call() throws Exception; } |
可以看到,與Runnable接口不同之處在於,call方法帶有泛型返回值V。
Future常用方法
V get() :獲取異步執行的結果,如果沒有結果可用,此方法會阻塞直到異步計算完成。
V get(Long timeout , TimeUnit unit) :獲取異步執行結果,如果沒有結果可用,此方法會阻塞,但是會有時間限制,如果阻塞時間超過設定的timeout時間,該方法將拋出異常。
boolean isDone() :如果任務執行結束,無論是正常結束或是中途取消還是發生異常,都返回true。
boolean isCanceller() :如果任務完成前被取消,則返回true。
boolean cancel(boolean mayInterruptRunning) :如果任務還沒開始,執行cancel(...)方法將返回false;如果任務已經啓動,執行cancel(true)方法將以中斷執行此任務線程的方式來試圖停止任務,如果停止成功,返回true;當任務已經啓動,執行cancel(false)方法將不會對正在執行的任務線程產生影響(讓線程正常執行到完成),此時返回false;當任務已經完成,執行cancel(...)方法將返回false。mayInterruptRunning參數表示是否中斷執行中的線程。
通過方法分析我們也知道實際上Future提供了3種功能:
(1)能夠中斷執行中的任務
(2)判斷任務是否執行完成
(3)獲取任務執行完成後額結果。
我們通過簡單的例子來體會使用Callable和Future來獲取任務結果的用法。
|
public class TestMain { public static void main(String[] args) throws InterruptedException, ExecutionException { ExecutorService executor = Executors.newCachedThreadPool(); Future<Integer> future = executor.submit(new AddNumberTask()); System.out.println(Thread.currentThread().getName() + "線程執行其他任務"); Integer integer = future.get(); System.out.println(integer); // 關閉線程池 if (executor != null) executor.shutdown(); }
}
class AddNumberTask implements Callable<Integer> {
public AddNumberTask() {
}
@Override public Integer call() throws Exception { System.out.println("####AddNumberTask###call()"); Thread.sleep(5000); return 5000; }
} |
Future模式
Future模式的核心在於:去除了主函數的等待時間,並使得原本需要等待的時間段可以用於處理其他業務邏輯
Futrure模式:對於多線程,如果線程A要等待線程B的結果,那麼線程A沒必要等待B,直到B有結果,可以先拿到一個未來的Future,等B有結果是再取真實的結果。
在多線程中經常舉的一個例子就是:網絡圖片的下載,剛開始是通過模糊的圖片來代替最後的圖片,等下載圖片的線程下載完圖片後在替換。而在這個過程中可以做一些其他的事情。

首先客戶端向服務器請求RealSubject,但是這個資源的創建是非常耗時的,怎麼辦呢?這種情況下,首先返回Client一個FutureSubject,以滿足客戶端的需求,於此同時呢,Future會通過另外一個Thread 去構造一個真正的資源,資源準備完畢之後,在給future一個通知。如果客戶端急於獲取這個真正的資源,那麼就會阻塞客戶端的其他所有線程,等待資源準備完畢。
公共數據接口,FutureData和RealData都要實現。
|
public interface Data { public abstract String getRequest(); } |
FutureData,當有線程想要獲取RealData的時候,程序會被阻塞。等到RealData被注入纔會使用getReal()方法。
|
public class FurureData implements Data {
public volatile static boolean ISFLAG = false; private RealData realData;
public synchronized void setRealData(RealData realData) { // 如果已經獲取到結果,直接返回 if (ISFLAG) { return; } // 如果沒有獲取到數據,傳遞真是對象 this.realData = realData; ISFLAG = true; // 進行通知 notify(); }
@Override public synchronized String getRequest() { while (!ISFLAG) { try { wait(); } catch (Exception e) {
} } // 獲取到數據,直接返回 return realData.getRequest(); }
} |
真實數據RealData
|
public class RealData implements Data { private String result;
public RealData(String data) { System.out.println("正在使用data:" + data + "網絡請求數據,耗時操作需要等待."); try { Thread.sleep(3000); } catch (Exception e) {
} System.out.println("操作完畢,獲取結果..."); result = "餘勝軍"; }
@Override public String getRequest() { return result; }
|
FutureClient 客戶端
|
public class FutureClient {
public Data request(String queryStr) { FurureData furureData = new FurureData(); new Thread(new Runnable() {
@Override public void run() { RealData realData = new RealData(queryStr); furureData.setRealData(realData); } }).start(); return furureData;
}
} |
調用者:
|
public class Main {
public static void main(String[] args) { FutureClient futureClient = new FutureClient(); Data request = futureClient.request("請求參數."); System.out.println("請求發送成功!"); System.out.println("執行其他任務..."); String result = request.getRequest(); System.out.println("獲取到結果..." + result); }
} |
調用者請求資源,client.request("name"); 完成對數據的準備
當要獲取資源的時候,data.getResult() ,如果資源沒有準備好isReady = false;那麼就會阻塞該線程。直到資源獲取然後該線程被喚醒。
原子類
java.util.concurrent.atomic包:原子類的小工具包,支持在單個變量上解除鎖的線程安全編程
原子變量類相當於一種泛化的 volatile 變量,能夠支持原子的和有條件的讀-改-寫操作。AtomicInteger 表示一個int類型的值,並提供了 get 和 set 方法,這些 Volatile 類型的int變量在讀取和寫入上有着相同的內存語義。它還提供了一個原子的 compareAndSet 方法(如果該方法成功執行,那麼將實現與讀取/寫入一個 volatile 變量相同的內存效果),以及原子的添加、遞增和遞減等方法。AtomicInteger 表面上非常像一個擴展的 Counter 類,但在發生競爭的情況下能提供更高的可伸縮性,因爲它直接利用了硬件對併發的支持。
爲什麼會有原子類
CAS:Compare and Swap,即比較再交換。
jdk5增加了併發包java.util.concurrent.*,其下面的類使用CAS算法實現了區別於synchronouse同步鎖的一種樂觀鎖。JDK 5之前Java語言是靠synchronized關鍵字保證同步的,這是一種獨佔鎖,也是是悲觀鎖。
如果同一個變量要被多個線程訪問,則可以使用該包中的類
AtomicBoolean
AtomicInteger
AtomicLong
AtomicReference
Disruptor併發框架
什麼是Disruptor
Martin Fowler在自己網站上寫了一篇LMAX架構的文章,在文章中他介紹了LMAX是一種新型零售金融交易平臺,它能夠以很低的延遲產生大量交易。這個系統是建立在JVM平臺上,其核心是一個業務邏輯處理器,它能夠在一個線程裏每秒處理六百萬訂單。業務邏輯處理器完全是運行在內存中,使用事件源驅動方式。業務邏輯處理器的核心是Disruptor。
Disruptor它是一個開源的併發框架,並獲得2011 Duke’s 程序框架創新獎, Disruptor是一個高性能的異步處理框架,能夠在無鎖的情況下實現網絡的Queue併發操作。可以認爲是最快的消息框架(輕量的JMS),也可以認爲是一個觀察者模式的實現,或者事件監聽模式的實現,也可以理解爲他是一種高效的"生產者-消費者"模型。
Disruptor使用觀察者模式, 主動將消息發送給消費者, 而不是等消費者從隊列中取; 在無鎖的情況下, 實現queue(環形, RingBuffer)的併發操作, 性能遠高於BlockingQueue
Disruptor的設計方案
Disruptor通過以下設計來解決隊列速度慢的問題:
環形數組結構:爲了避免垃圾回收,採用數組而非鏈表。同時,數組對處理器的緩存機制更加友好。
元素位置定位:數組長度2^n,通過位運算,加快定位的速度。下標採取遞增的形式。不用擔心index溢出的問題。index是long類型,即使100萬QPS的處理速度,也需要30萬年才能用完。
無鎖設計:實現低延遲的細節就是在Disruptor中利用無鎖的算法,所有內存的可見性和正確性都是利用內存屏障或者CAS操作。使用CAS來保證多線程安全,與大部分併發隊列使用的鎖相比,CAS顯然要快很多。CAS是CPU級別的指令,更加輕量,不必像鎖一樣需要操作系統提供支持,所以每次調用不需要在用戶態與內核態之間切換,也不需要上下文切換。每個生產者或者消費者線程,會先申請可以操作的元素在數組中的位置,申請到之後,直接在該位置寫入或者讀取數據。
只有一個用例中鎖是必須的,那就是BlockingWaitStrategy(阻塞等待策略),唯一的實現方法就是使用Condition實現消費者在新事件到來前等待。許多低延遲系統使用忙等待去避免Condition的抖動,然而在系統忙等待的操作中,性能可能會顯著降低,尤其是在CPU資源嚴重受限的情況下,例如虛擬環境下的WEB服務器。
Disruptor實現生產與消費
Pom Maven依賴信息
|
<dependencies> <dependency> <groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> <version>3.2.1</version> </dependency> </dependencies> |
首先聲明一個Event來包含需要傳遞的數據:
|
//定義事件event 通過Disruptor 進行交換的數據類型。 public class LongEvent {
private Long value;
public Long getValue() { return value; }
public void setValue(Long value) { this.value = value; }
} |
需要讓Disruptor爲我們創建事件,我們同時還聲明瞭一個EventFactory來實例化Event對象。
|
public class LongEventFactory implements EventFactory<LongEvent> {
public LongEvent newInstance() {
return new LongEvent(); }
} |
事件消費者,也就是一個事件處理器。這個事件處理器簡單地把事件中存儲的數據打印到終端:
|
public class LongEventHandler implements EventHandler<LongEvent> {
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) throws Exception { System.out.println("消費者:"+event.getValue()); }
} |
定義生產這發送事件
|
public class LongEventProducer {
public final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer) { this.ringBuffer = ringBuffer; }
public void onData(ByteBuffer byteBuffer) { // 1.ringBuffer 事件隊列 下一個槽 long sequence = ringBuffer.next(); Long data = null; try { //2.取出空的事件隊列 LongEvent longEvent = ringBuffer.get(sequence); data = byteBuffer.getLong(0); //3.獲取事件隊列傳遞的數據 longEvent.setValue(data); try { Thread.sleep(10); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } finally { System.out.println("生產這準備發送數據"); //4.發佈事件 ringBuffer.publish(sequence);
} }
} |
main函數執行調用
|
public class DisruptorMain {
public static void main(String[] args) { // 1.創建一個可緩存的線程 提供線程來出發Consumer 的事件處理 ExecutorService executor = Executors.newCachedThreadPool(); // 2.創建工廠 EventFactory<LongEvent> eventFactory = new LongEventFactory(); // 3.創建ringBuffer 大小 int ringBufferSize = 1024 * 1024; // ringBufferSize大小一定要是2的N次方 // 4.創建Disruptor Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(eventFactory, ringBufferSize, executor, ProducerType.SINGLE, new YieldingWaitStrategy()); // 5.連接消費端方法 disruptor.handleEventsWith(new LongEventHandler()); // 6.啓動 disruptor.start(); // 7.創建RingBuffer容器 RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); // 8.創建生產者 LongEventProducer producer = new LongEventProducer(ringBuffer); // 9.指定緩衝區大小 ByteBuffer byteBuffer = ByteBuffer.allocate(8); for (int i = 1; i <= 100; i++) { byteBuffer.putLong(0, i); producer.onData(byteBuffer); } //10.關閉disruptor和executor disruptor.shutdown(); executor.shutdown(); }
} |
什麼是ringbuffer
它是一個環(首尾相接的環),你可以把它用做在不同上下文(線程)間傳遞數據的buffer。
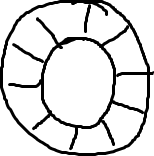
基本來說,ringbuffer擁有一個序號,這個序號指向數組中下一個可用的元素。(校對注:如下圖右邊的圖片表示序號,這個序號指向數組的索引4的位置。)
隨着你不停地填充這個buffer(可能也會有相應的讀取),這個序號會一直增長,直到繞過這個環。

要找到數組中當前序號指向的元素,可以通過mod操作:
以上面的ringbuffer爲例(java的mod語法):12 % 10 = 2。很簡單吧。 事實上,上圖中的ringbuffer只有10個槽完全是個意外。如果槽的個數是2的N次方更有利於基於二進制
優點
之所以ringbuffer採用這種數據結構,是因爲它在可靠消息傳遞方面有很好的性能。這就夠了,不過它還有一些其他的優點。
首先,因爲它是數組,所以要比鏈表快,而且有一個容易預測的訪問模式。(數組內元素的內存地址的連續性存儲的)。這是對CPU緩存友好的,也就是說,在硬件級別,數組中的元素是會被預加載的,因此在ringbuffer當中,cpu無需時不時去主存加載數組中的下一個元素。(校對注:因爲只要一個元素被加載到緩存行,其他相鄰的幾個元素也會被加載進同一個緩存行)
其次,你可以爲數組預先分配內存,使得數組對象一直存在(除非程序終止)。這就意味着不需要花大量的時間用於垃圾回收。此外,不像鏈表那樣,需要爲每一個添加到其上面的對象創造節點對象—對應的,當刪除節點時,需要執行相應的內存清理操作。
RingBuffer底層實現
RingBuffer是一個首尾相連的環形數組,所謂首尾相連,是指當RingBuffer上的指針越過數組是上界後,繼續從數組頭開始遍歷。因此,RingBuffer中至少有一個指針,來表示RingBuffer中的操作位置。另外,指針的自增操作需要做併發控制,Disruptor和本文的OptimizedQueue都使用CAS的樂觀併發控制來保證指針自增的原子性,關於樂觀併發控制之後會着重介紹。
Disruptor中的RingBuffer上只有一個指針,表示當前RingBuffer上消息寫到了哪裏,此外,每個消費者會維護一個sequence表示自己在RingBuffer上讀到哪裏,從這個角度講,Disruptor中的RingBuffer上實際有消費者數+1個指針。由於我們要實現的是一個單消息單消費的阻塞隊列,只要維護一個讀指針(對應消費者)和一個寫指針(對應生產者)即可,無論哪個指針,每次讀寫操作後都自增一次,一旦越界,即從數組頭開始繼續讀寫
Disruptor的核心概念
先從瞭解 Disruptor 的核心概念開始,來了解它是如何運作的。下面介紹的概念模型,既是領域對象,也是映射到代碼實現上的核心對象。
RingBuffer
如其名,環形的緩衝區。曾經 RingBuffer 是 Disruptor 中的最主要的對象,但從3.0版本開始,其職責被簡化爲僅僅負責對通過 Disruptor 進行交換的數據(事件)進行存儲和更新。在一些更高級的應用場景中,Ring Buffer 可以由用戶的自定義實現來完全替代。
SequenceDisruptor
通過順序遞增的序號來編號管理通過其進行交換的數據(事件),對數據(事件)的處理過程總是沿着序號逐個遞增處理。一個 Sequence 用於跟蹤標識某個特定的事件處理者( RingBuffer/Consumer )的處理進度。雖然一個 AtomicLong 也可以用於標識進度,但定義 Sequence 來負責該問題還有另一個目的,那就是防止不同的 Sequence 之間的CPU緩存僞共享(Flase Sharing)問題。(注:這是 Disruptor 實現高性能的關鍵點之一,網上關於僞共享問題的介紹已經汗牛充棟,在此不再贅述)。
Sequencer
Sequencer 是 Disruptor 的真正核心。此接口有兩個實現類 SingleProducerSequencer、MultiProducerSequencer ,它們定義在生產者和消費者之間快速、正確地傳遞數據的併發算法。
Sequence Barrier
用於保持對RingBuffer的 main published Sequence 和Consumer依賴的其它Consumer的 Sequence 的引用。 Sequence Barrier 還定義了決定 Consumer 是否還有可處理的事件的邏輯。
Wait Strategy
定義 Consumer 如何進行等待下一個事件的策略。 (注:Disruptor 定義了多種不同的策略,針對不同的場景,提供了不一樣的性能表現)
Event
在 Disruptor 的語義中,生產者和消費者之間進行交換的數據被稱爲事件(Event)。它不是一個被 Disruptor 定義的特定類型,而是由 Disruptor 的使用者定義並指定。
EventProcessor
EventProcessor 持有特定消費者(Consumer)的 Sequence,並提供用於調用事件處理實現的事件循環(Event Loop)。
EventHandler
Disruptor 定義的事件處理接口,由用戶實現,用於處理事件,是 Consumer 的真正實現。
Producer
即生產者,只是泛指調用 Disruptor 發佈事件的用戶代碼,Disruptor 沒有定義特定接口或類型。
RingBuffer——Disruptor底層數據結構實現,核心類,是線程間交換數據的中轉地;
Sequencer——序號管理器,負責消費者/生產者各自序號、序號柵欄的管理和協調;
Sequence——序號,聲明一個序號,用於跟蹤ringbuffer中任務的變化和消費者的消費情況;
SequenceBarrier——序號柵欄,管理和協調生產者的遊標序號和各個消費者的序號,確保生產者不會覆蓋消費者未來得及處理的消息,確保存在依賴的消費者之間能夠按照正確的順序處理;
EventProcessor——事件處理器,監聽RingBuffer的事件,並消費可用事件,從RingBuffer讀取的事件會交由實際的生產者實現類來消費;它會一直偵聽下一個可用的序號,直到該序號對應的事件已經準備好。
EventHandler——業務處理器,是實際消費者的接口,完成具體的業務邏輯實現,第三方實現該接口;代表着消費者。
Producer——生產者接口,第三方線程充當該角色,producer向RingBuffer寫入事件。