




常見的排序算法有如下8種,插入排序,希爾排序,歸併排序,冒泡排序,快速排序,選擇排序,堆排序,基數排序。
我把這8種算法相似的歸到了一起,然後分成了五類,如下所示:
1、插入排序(穩定的)---〉希爾排序(從插入衍生出來,不穩定的)--〉歸併排序(歸併內部用到了插入排序的方式,穩定的)
2、冒泡排序(穩定的)---〉快速排序(從冒泡而來,遞歸實現,不穩定的);
3、選擇排序(不穩定的);
4、堆排序(用到二叉樹,不穩定的);
5、基數排序(穩定的)
穩定和不穩定的定義和區別:
排序算法的穩定性,通俗地講就是能保證排序前2個相等的數其在序列的前後位置順序和排序後它們兩個的前後位置順序相同。舉個例子,如果Ai= Aj, Ai原來在Aj位置前,排序後Ai還要在Aj位置前。
說一下穩定性的好處。排序算法如果是穩定的,那麼從一個鍵上排序,然後再從另一個鍵上排序,第一個鍵排序的結果可以爲第二個鍵排序所用。基數排序就是這樣,先按低位排序,逐次按高位排序,低位相同的元素其順序再高位也相同時是不會改變的。另外,如果排序算法穩定,對基於比較的排序算法而言,元素交換的次數可能會少一些。
每種算法都有它特定的使用場合,很難通用。因此,我們很有必要對所有常見的排序算法進行歸納。
8種排序算法的時間複雜度和空間複雜度:
|
排序法 |
最差時間分析 |
平均時間複雜度 |
穩定度 |
複雜性 |
空間複雜度 |
|
插入排序 |
O(n2) |
O(n2) |
穩定 |
簡單 |
O(1) |
|
希爾排序 |
O |
O |
不穩定 |
較複雜 |
O(1) |
|
歸併排序 |
O(n*log2n) |
O(n*log2n) |
穩定 |
較複雜 |
O(n) |
|
冒泡排序 |
O(n2) |
O(n2) |
穩定 |
簡單 |
O(1) |
|
快速排序 |
O(n2) |
O(n*log2n) |
不穩定 |
較複雜 |
O(log2n)~O(n) |
|
選擇排序 |
O(n2) |
O(n2) |
不穩定 |
簡單 |
O(1) |
|
堆排序 |
O(n*log2n) |
O(n*log2n) |
不穩定 |
較複雜 |
O(1) |
|
基數排序 |
O(d(n+r)) |
O(d(n+r)) |
穩定 |
較複雜 |
由上表可知,穩定排序和不穩定排序各自有4種,穩定排序的爲插入排序,歸併排序,冒泡排序和基數排序,不穩定的排序爲希爾排序,快速排序,選擇排序,堆排序4種。其中簡單排序爲插入排序,冒泡排序和選擇排序,其它都爲較複雜的排序方法。
注意:下面的有些圖片和思想來自於博客:http://blog.csdn.net/whuslei/article/details/6442755,這裏標註一下。
一、直接插入排序(插入排序,穩定,簡單)。
1、思想。
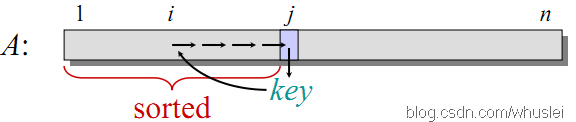
直接插入排序,就像名字那樣是一種插入排序方法。如下圖所示,每次從原來序列中選擇一個元素K插入到之前已排好序的部分A[1…i]中,可以從原序列的第一個元素着手,插入過程中K依次由後向前與A[1…i]中的元素進行比較。若發現A[x]>=K,則將K插入到A[x]的後面,插入前需要移動元素。

2、算法時間複雜度。
最好的情況下:正序有序(從小到大),這樣只需要比較n次,不需要移動。因此時間複雜度爲O(n)
最壞的情況下:逆序有序,這樣每一個元素就需要比較n次,共有n個元素,因此實際複雜度爲O(n2)
平均情況下:O(n2)
3、代碼。
voidinsertsort(int *pData,int left,int right)
{
int i,j;
int temp;
for(i=left+1;i<right;i++)
{
temp = pData[i];
j = i;
while(--j>=left &&pData[j]>temp)
{
pData[j+1] = pData[j];
}
pData[j+1] =temp;
}
}
4、穩定性和複雜度。
在插入排序中,K1是已排序部分中的元素,當K2和K1比較時,直接插到K1的後面(沒有必要插到K1的前面,這樣做還需要移動),因此,插入排序是穩定的。
此算法比較簡單。
二、希爾排序(插入排序,不穩定,較複雜)
1、思想。
希爾排序也是一種插入排序方法,實際上是一種分組插入方法。先定一個小於n的整數d1作爲第一個增量,把表的全部記錄分成d1個組,所有距離爲d1的倍數的記錄放在同一個組中,在各組內進行直接插入排序;然後,取第二個增量d2(<d1),重複上述的分組和排序,直至所取的增量dt=1(dt<dt-1<…<d2<d1),即所有記錄放在同一組中進行直接插入排序爲止。
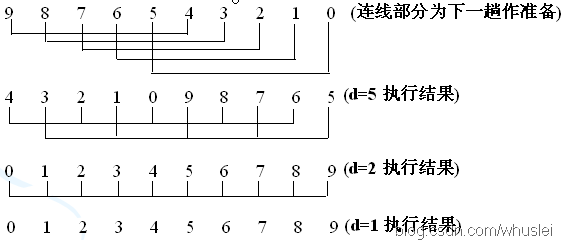
例如:將 n 個記錄分成 d 個子序列:

說明:依次可以將d分爲d=5,d=2,d=1,然後組內使用直接插入排序進行排序。
2、時間複雜度。
最好情況:由於希爾排序的好壞和步長d的選擇有很多關係,因此,目前還沒有得出最好的步長如何選擇(現在有些比較好的選擇了,但不確定是否是最好的)。所以,不知道最好的情況下的算法時間複雜度。
最壞情況下:O(N*logN),最壞的情況下和平均情況下差不多。
平均情況下:O(N*logN)
3、代碼。
voidshellsort(int *pData,int left,int right)
{
int i,j,gap;
int temp;
for(gap=right/2;gap>0;gap/=2)
{
for(i=gap;i<right;i++)
{
temp = pData[i];
for(j=i-gap;(j>=0)&&pData[j]>temp;j-=gap)
{
pData[j+gap] =pData[j];
}
pData[j+gap] = temp;
}
}
}
4、穩定性。
由於多次插入排序,我們知道一次插入排序是穩定的,不會改變相同元素的相對順序,但在不同的插入排序過程中,相同的元素可能在各自的插入排序中移動,最後其穩定性就會被打亂,所以shell排序是不穩定的。
此算法比較複雜。
三、歸併排序(插入排序,穩定,較複雜)
1、思想。
首先選擇2個爲一組,組內進行排序,然後第2趟是4個爲一組,依次類推,再次翻倍,8個一組,每組使用插入排序的方法。

2、算法時間複雜度
最好的情況下:一趟歸併需要n次,總共需要logN次,因此爲O(N*logN)
最壞的情況下,接近於平均情況下,爲O(N*logN)
3、代碼。
非遞歸方法:
void mergesort3(int *list,int length)
{
inti, left_min, left_max, right_min, right_max, next;
int *tmp =(int*)malloc(sizeof(int) * length);
if (tmp == NULL)
{
fputs("Error: out of memory\n", stderr);
abort();
}
for (i = 1; i < length; i *=2)
for(left_min = 0; left_min < length - i; left_min = right_max)
{
right_min = left_max = left_min + i;
right_max = left_max + i;
if (right_max > length)
right_max = length;
next = 0;
while (left_min < left_max && right_min <right_max)
tmp[next++] = list[left_min] >list[right_min] ? list[right_min++] : list[left_min++];
while (left_min < left_max)
list[--right_min] = list[--left_max];
while (next > 0)
list[--right_min] = tmp[--next];
}
free(tmp);
}
遞歸方法:
void merges(int *pData,int *Des,int first,intmid,int last)
{
int i = first;
int j = mid + 1;
int k = first;
while(i<=mid&&j<=last)
{
if(pData[i]<pData[j])
Des[k++] = pData[i++];
else
Des[k++] = pData[j++];
}
while(i<=mid)
{
Des[k++] = pData[i++];
}
while(j<=last)
{
Des[k++] = pData[j++];
}
for(k=first;k<=last;k++)
pData[k] = Des[k];
}
4、穩定性
歸併排序最大的特色就是它是一種穩定的排序算法。歸併過程中是不會改變元素的相對位置的。
此算法比較複雜。
四、冒泡排序 (交換排序,穩定,簡單)
1、思想。
通過無序區中相鄰記錄關鍵字間的比較和位置的交換,使關鍵字最小的記錄如氣泡般逐漸往上“漂浮”直至“水面”。

2、時間複雜度
最好情況下:正序有序,則只需要比較n次。故,爲O(n)
最壞情況下:逆序有序,則需要比較(n-1)+(n-2)+……+1,故,爲O(N*N)
3、代碼。
void bubblesort(int *pData,int left,intright)
{
inti,j;
inttemp;
for(i=left;i<right-1;i++)
{
for(j=left;j<right-i-1;j++)
{
if(pData[j+1]<pData[j])
{
temp= pData[j+1];
pData[j+1] = pData[j];
pData[j]= temp;
}
}
}
}
4、穩定性 。
排序過程中只交換相鄰兩個元素的位置。因此,當兩個數相等時,是沒必要交換兩個數的位置的。所以,它們的相對位置並沒有改變,冒泡排序算法是穩定的!
此算法簡單。
五、快速排序 (交換排序,不穩定,較複雜)
1、思想。
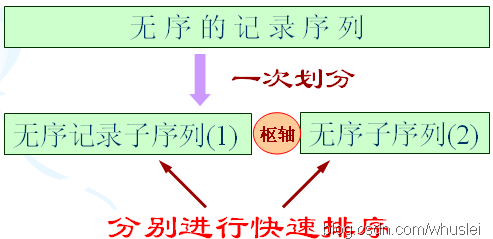
它是由冒泡排序改進而來的。在待排序的n個記錄中任取一個記錄(通常取第一個記錄),把該記錄放入適當位置後,數據序列被此記錄劃分成兩部分。所有關鍵字比該記錄關鍵字小的記錄放置在前一部分,所有比它大的記錄放置在後一部分,並把該記錄排在這兩部分的中間(稱爲該記錄歸位),這個過程稱作一趟快速排序。

說明:最核心的思想是將小的部分放在左邊,大的部分放到右邊,實現分割。
2、算法複雜度 。
最好的情況下:因爲每次都將序列分爲兩個部分(一般二分都複雜度都和logN相關),故爲 O(N*logN)
最壞的情況下:基本有序時,退化爲冒泡排序,幾乎要比較N*N次,故爲O(N*N)
3、代碼。
遊標爲最左邊元素:
voidquicksort(int *pData,int left,int right)
{
int i,j,middle,temp;
middle = pData[left];
i = left + 1;
j = right - 1;
do{
while( i<right && pData[i]<middle)
i++;
while( j>left && pData[j]>middle)
j--;
if(i >= j)
break;
temp = pData[i];
pData[i] = pData[j];
pData[j] = temp;
i++;
j--;
}while(i<=j);
pData[left] = pData[j];
pData[j] = middle;
if(left<j-1)
quicksort(pData,left,j);
if(right>j+1)
quicksort(pData,j+1,right);
}
4、穩定性
由於每次都需要和中軸元素交換,因此原來的順序就可能被打亂。所以說,快速排序是不穩定的。
此算法較複雜。
六、直接選擇排序(選擇排序,不穩定,簡單)
1、思想。
首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然後,再從剩餘未排序元素中繼續尋找最小元素,然後放到排序序列末尾。以此類推,直到所有元素均排序完畢。具體做法是:選擇最小的元素與未排序部分的首部交換,使得序列的前面爲有序。

2、時間複雜度。
最好情況下:交換0次,但是每次都要找到最小的元素,因此大約必須遍歷N*N次,因此爲O(N*N)。減少了交換次數!
最壞情況下:平均情況下:O(N*N)
3、代碼。
void selectsort(int *pData,int left,intright)
{
inti,j,temp;
inttb;
for(i=left;i<right-1;i++)
{
temp= i;
for(j=i+1;j<right;j++)
{
if(pData[j]<pData[temp])
{
temp= j;
}
}
if(i!= temp )
{
tb= pData[temp];
pData[temp]= pData[i];
pData[i]= tb;
}
}
}
4、穩定性 。
由於每次都是選取未排序序列A中的最小元素x與A中的第一個元素交換,很可能破壞了元素間的相對位置,因此選擇排序是不穩定的!
此算法較複雜。
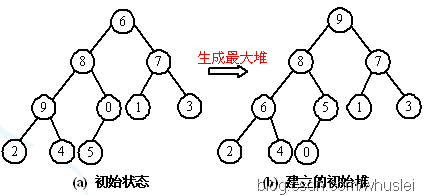
七、堆排序(不穩定,較複雜)
1、思想。
利用完全二叉樹中雙親節點和孩子節點之間的內在關係,在當前無序區中選擇關鍵字最大(或者最小)的記錄。也就是說,以最大堆爲例,根節點爲最大元素,較小的節點偏向於分佈在堆底附近。

2、算法複雜度
最壞情況下,接近於最差情況下:O(N*logN),因此它是一種效果不錯的排序算法。
3、代碼
void HeapAdjust(int array[], int i, intnLength)
{
intnchild;
intntemp;
while(i>=0)
{
nchild= 2 * i + 1;
ntemp= array[i];
if(array[nchild]<ntemp)
{
ntemp= array[nchild];
array[nchild]= array[i];
array[i]= ntemp;
}
if(nchild < nLength - 1)
{
nchild++;
if(array[nchild]<ntemp)
{
ntemp= array[nchild];
array[nchild]= array[i];
array[i]= ntemp;
}
}
i--;
}
}
// 堆排序算法
void HeapSort(int array[],int length)
{
inti,temp;
for(int nL = length; nL>0;nL--)
{
i= nL/2 - 1;
HeapAdjust(array,i,nL);
temp= array[0];
array[0]= array[nL-1];
array[nL-1]= temp;
}
}
4、穩定性 。
堆排序需要不斷地調整堆,因此它是一種不穩定的排序。
此算法較複雜。
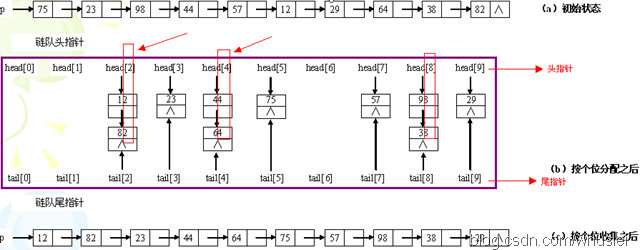
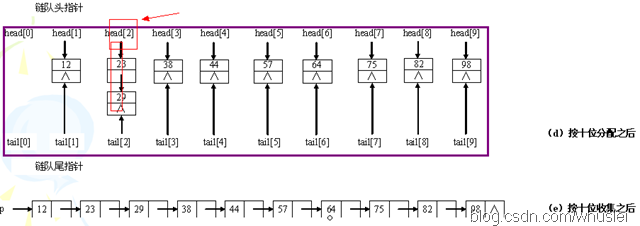
八、基數排序(穩定,較複雜)
1、思想。
它是一種非比較排序。它是根據位的高低進行排序的,也就是先按個位排序,然後依據十位排序……以此類推。示例如下:


2、算法的時間複雜度。
分配需要O(n),收集爲O(r),其中r爲分配後鏈表的個數,以r=10爲例,則有0~9這樣10個鏈表來將原來的序列分類。而d,也就是位數(如最大的數是1234,位數是4,則d=4),即"分配-收集"的趟數。因此時間複雜度爲O(d*(n+r))。
3、代碼。
const int base=10;
struct wx
{
intnum;
wx*next;
wx()
{
next=NULL;
}
};
wx *headn,*curn,*box[base],*curbox[base];
void basesort(int t)
{
int i,k=1,r,bn;
// k,r 分別表示10的冪次方,用來得到相應位上的單個數字,比如 k=10,r=100,數字207,則 十位上 0 = //(207/r)%10
for(i=1;i<=t;i++)
{
k*=base;
}
r=k*base;
//curbox和box中的指針指向相同的位置,當curbox中有新元素時,curbox指向會發生變化,形成box元素爲//頭指針,curbox元素相當於滑動指針,這樣可以通過比較兩者的不同來判斷指針的走向。
for(i=0;i<base;i++)
{
curbox[i]=box[i];
}
for(curn=headn->next;curn!=NULL;curn=curn->next)
{
bn=(curn->num%r)/k; // bn表示元素相應位上的值,
curbox[bn]->next=curn; //curbox[i]的next指向相應位爲i的元素
curbox[bn]=curbox[bn]->next; //此時curbox[i]向後移位,以box[i]爲首的鏈表長度增加
}
curn=headn;
for(i=0;i<base;i++)
{
if(curbox[i]!=box[i])
{
curn->next=box[i]->next;
curn=curbox[i]; //curn此時指向了在box中具有相同值的鏈表的最後一個,例如 123, //33,783,67,56,在3開頭的 元素鏈表中,此時cur指向了783。
}
}
curn->next=NULL;
}
void printwx()
{
for(curn=headn->next;curn!=NULL;curn=curn->next)
{
cout<<curn->num<<'';
}
cout<<endl;
}
int main()
{
inti,n,z=0,maxn=0;
curn=headn=newwx;
cin>>n;
for(i=0;i<base;i++)
{
curbox[i]=box[i]=newwx;
}
for(i=1;i<=n;i++)
{
curn=curn->next=newwx;
cin>>curn->num;
maxn=max(maxn,curn->num);
}
while(maxn/base>0)
{
maxn/=base;
z++;
}
for(i=0;i<=z;i++)
{
basesort(i);
}
printwx();
return0;
}
4、穩定性。
基數排序過程中不改變元素的相對位置,因此是穩定的。
此算法較複雜。
附錄:
本篇文章主要參考了博客http://blog.csdn.net/whuslei/article/details/6442755,作者對排序總結的非常詳細,大家感興趣可以去閱讀原文。
另外,http://www.blogjava.net/todayx-org/archive/2012/01/08/368091.html總結的也不錯,其中有GIF動態圖可以清晰的瀏覽到算法是如何實現的。
提前聲明一下,面試知識點這個系列的文章,有很多借鑑了網上的一些文章,因爲我的本意也不是完全原創,而是基於原創進行整理,難免會引用到別人的圖或文字。
整理這些知識點時,我會盡量將自己理解消化調後總結,然後表述出來,但爲了使大家理解更深刻,不可避免也會引用到別人的內容。當引用到別人寫的內容時,我也會盡量註明出處,如果引用的內容忘了或者沒有標記原來出處,如涉及到侵權,還請聯繫我修改。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
歡迎您掃一掃上面的微信公衆號,訂閱我的個人公衆號!
本公衆號將以推送Android各種碎片化小知識或小技巧,以及整理Android面試知識點爲主,也會不定期將開發老司機日常工作中踩過的坑,平時自學的一些知識總結出來進行分享。每天一點乾貨小知識把你的碎片時間充分利用起來。