




常见的排序算法有如下8种,插入排序,希尔排序,归并排序,冒泡排序,快速排序,选择排序,堆排序,基数排序。
我把这8种算法相似的归到了一起,然后分成了五类,如下所示:
1、插入排序(稳定的)---〉希尔排序(从插入衍生出来,不稳定的)--〉归并排序(归并内部用到了插入排序的方式,稳定的)
2、冒泡排序(稳定的)---〉快速排序(从冒泡而来,递归实现,不稳定的);
3、选择排序(不稳定的);
4、堆排序(用到二叉树,不稳定的);
5、基数排序(稳定的)
稳定和不稳定的定义和区别:
排序算法的稳定性,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。举个例子,如果Ai= Aj, Ai原来在Aj位置前,排序后Ai还要在Aj位置前。
说一下稳定性的好处。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。另外,如果排序算法稳定,对基于比较的排序算法而言,元素交换的次数可能会少一些。
每种算法都有它特定的使用场合,很难通用。因此,我们很有必要对所有常见的排序算法进行归纳。
8种排序算法的时间复杂度和空间复杂度:
|
排序法 |
最差时间分析 |
平均时间复杂度 |
稳定度 |
复杂性 |
空间复杂度 |
|
插入排序 |
O(n2) |
O(n2) |
稳定 |
简单 |
O(1) |
|
希尔排序 |
O |
O |
不稳定 |
较复杂 |
O(1) |
|
归并排序 |
O(n*log2n) |
O(n*log2n) |
稳定 |
较复杂 |
O(n) |
|
冒泡排序 |
O(n2) |
O(n2) |
稳定 |
简单 |
O(1) |
|
快速排序 |
O(n2) |
O(n*log2n) |
不稳定 |
较复杂 |
O(log2n)~O(n) |
|
选择排序 |
O(n2) |
O(n2) |
不稳定 |
简单 |
O(1) |
|
堆排序 |
O(n*log2n) |
O(n*log2n) |
不稳定 |
较复杂 |
O(1) |
|
基数排序 |
O(d(n+r)) |
O(d(n+r)) |
稳定 |
较复杂 |
由上表可知,稳定排序和不稳定排序各自有4种,稳定排序的为插入排序,归并排序,冒泡排序和基数排序,不稳定的排序为希尔排序,快速排序,选择排序,堆排序4种。其中简单排序为插入排序,冒泡排序和选择排序,其它都为较复杂的排序方法。
注意:下面的有些图片和思想来自于博客:http://blog.csdn.net/whuslei/article/details/6442755,这里标注一下。
一、直接插入排序(插入排序,稳定,简单)。
1、思想。
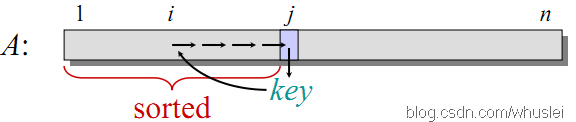
直接插入排序,就像名字那样是一种插入排序方法。如下图所示,每次从原来序列中选择一个元素K插入到之前已排好序的部分A[1…i]中,可以从原序列的第一个元素着手,插入过程中K依次由后向前与A[1…i]中的元素进行比较。若发现A[x]>=K,则将K插入到A[x]的后面,插入前需要移动元素。

2、算法时间复杂度。
最好的情况下:正序有序(从小到大),这样只需要比较n次,不需要移动。因此时间复杂度为O(n)
最坏的情况下:逆序有序,这样每一个元素就需要比较n次,共有n个元素,因此实际复杂度为O(n2)
平均情况下:O(n2)
3、代码。
voidinsertsort(int *pData,int left,int right)
{
int i,j;
int temp;
for(i=left+1;i<right;i++)
{
temp = pData[i];
j = i;
while(--j>=left &&pData[j]>temp)
{
pData[j+1] = pData[j];
}
pData[j+1] =temp;
}
}
4、稳定性和复杂度。
在插入排序中,K1是已排序部分中的元素,当K2和K1比较时,直接插到K1的后面(没有必要插到K1的前面,这样做还需要移动),因此,插入排序是稳定的。
此算法比较简单。
二、希尔排序(插入排序,不稳定,较复杂)
1、思想。
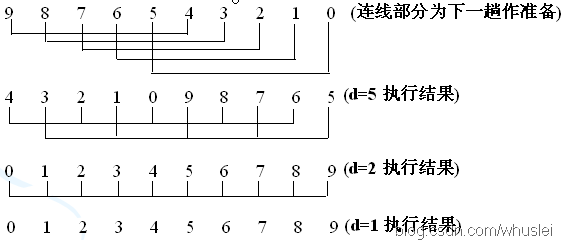
希尔排序也是一种插入排序方法,实际上是一种分组插入方法。先定一个小于n的整数d1作为第一个增量,把表的全部记录分成d1个组,所有距离为d1的倍数的记录放在同一个组中,在各组内进行直接插入排序;然后,取第二个增量d2(<d1),重复上述的分组和排序,直至所取的增量dt=1(dt<dt-1<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
例如:将 n 个记录分成 d 个子序列:

说明:依次可以将d分为d=5,d=2,d=1,然后组内使用直接插入排序进行排序。
2、时间复杂度。
最好情况:由于希尔排序的好坏和步长d的选择有很多关系,因此,目前还没有得出最好的步长如何选择(现在有些比较好的选择了,但不确定是否是最好的)。所以,不知道最好的情况下的算法时间复杂度。
最坏情况下:O(N*logN),最坏的情况下和平均情况下差不多。
平均情况下:O(N*logN)
3、代码。
voidshellsort(int *pData,int left,int right)
{
int i,j,gap;
int temp;
for(gap=right/2;gap>0;gap/=2)
{
for(i=gap;i<right;i++)
{
temp = pData[i];
for(j=i-gap;(j>=0)&&pData[j]>temp;j-=gap)
{
pData[j+gap] =pData[j];
}
pData[j+gap] = temp;
}
}
}
4、稳定性。
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
此算法比较复杂。
三、归并排序(插入排序,稳定,较复杂)
1、思想。
首先选择2个为一组,组内进行排序,然后第2趟是4个为一组,依次类推,再次翻倍,8个一组,每组使用插入排序的方法。

2、算法时间复杂度
最好的情况下:一趟归并需要n次,总共需要logN次,因此为O(N*logN)
最坏的情况下,接近于平均情况下,为O(N*logN)
3、代码。
非递归方法:
void mergesort3(int *list,int length)
{
inti, left_min, left_max, right_min, right_max, next;
int *tmp =(int*)malloc(sizeof(int) * length);
if (tmp == NULL)
{
fputs("Error: out of memory\n", stderr);
abort();
}
for (i = 1; i < length; i *=2)
for(left_min = 0; left_min < length - i; left_min = right_max)
{
right_min = left_max = left_min + i;
right_max = left_max + i;
if (right_max > length)
right_max = length;
next = 0;
while (left_min < left_max && right_min <right_max)
tmp[next++] = list[left_min] >list[right_min] ? list[right_min++] : list[left_min++];
while (left_min < left_max)
list[--right_min] = list[--left_max];
while (next > 0)
list[--right_min] = tmp[--next];
}
free(tmp);
}
递归方法:
void merges(int *pData,int *Des,int first,intmid,int last)
{
int i = first;
int j = mid + 1;
int k = first;
while(i<=mid&&j<=last)
{
if(pData[i]<pData[j])
Des[k++] = pData[i++];
else
Des[k++] = pData[j++];
}
while(i<=mid)
{
Des[k++] = pData[i++];
}
while(j<=last)
{
Des[k++] = pData[j++];
}
for(k=first;k<=last;k++)
pData[k] = Des[k];
}
4、稳定性
归并排序最大的特色就是它是一种稳定的排序算法。归并过程中是不会改变元素的相对位置的。
此算法比较复杂。
四、冒泡排序 (交换排序,稳定,简单)
1、思想。
通过无序区中相邻记录关键字间的比较和位置的交换,使关键字最小的记录如气泡般逐渐往上“漂浮”直至“水面”。

2、时间复杂度
最好情况下:正序有序,则只需要比较n次。故,为O(n)
最坏情况下:逆序有序,则需要比较(n-1)+(n-2)+……+1,故,为O(N*N)
3、代码。
void bubblesort(int *pData,int left,intright)
{
inti,j;
inttemp;
for(i=left;i<right-1;i++)
{
for(j=left;j<right-i-1;j++)
{
if(pData[j+1]<pData[j])
{
temp= pData[j+1];
pData[j+1] = pData[j];
pData[j]= temp;
}
}
}
}
4、稳定性 。
排序过程中只交换相邻两个元素的位置。因此,当两个数相等时,是没必要交换两个数的位置的。所以,它们的相对位置并没有改变,冒泡排序算法是稳定的!
此算法简单。
五、快速排序 (交换排序,不稳定,较复杂)
1、思想。
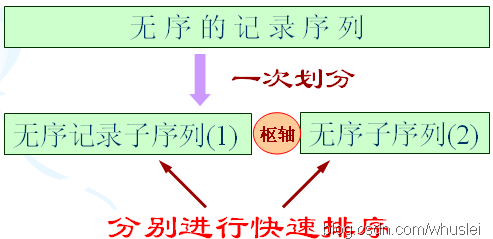
它是由冒泡排序改进而来的。在待排序的n个记录中任取一个记录(通常取第一个记录),把该记录放入适当位置后,数据序列被此记录划分成两部分。所有关键字比该记录关键字小的记录放置在前一部分,所有比它大的记录放置在后一部分,并把该记录排在这两部分的中间(称为该记录归位),这个过程称作一趟快速排序。

说明:最核心的思想是将小的部分放在左边,大的部分放到右边,实现分割。
2、算法复杂度 。
最好的情况下:因为每次都将序列分为两个部分(一般二分都复杂度都和logN相关),故为 O(N*logN)
最坏的情况下:基本有序时,退化为冒泡排序,几乎要比较N*N次,故为O(N*N)
3、代码。
游标为最左边元素:
voidquicksort(int *pData,int left,int right)
{
int i,j,middle,temp;
middle = pData[left];
i = left + 1;
j = right - 1;
do{
while( i<right && pData[i]<middle)
i++;
while( j>left && pData[j]>middle)
j--;
if(i >= j)
break;
temp = pData[i];
pData[i] = pData[j];
pData[j] = temp;
i++;
j--;
}while(i<=j);
pData[left] = pData[j];
pData[j] = middle;
if(left<j-1)
quicksort(pData,left,j);
if(right>j+1)
quicksort(pData,j+1,right);
}
4、稳定性
由于每次都需要和中轴元素交换,因此原来的顺序就可能被打乱。所以说,快速排序是不稳定的。
此算法较复杂。
六、直接选择排序(选择排序,不稳定,简单)
1、思想。
首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。以此类推,直到所有元素均排序完毕。具体做法是:选择最小的元素与未排序部分的首部交换,使得序列的前面为有序。

2、时间复杂度。
最好情况下:交换0次,但是每次都要找到最小的元素,因此大约必须遍历N*N次,因此为O(N*N)。减少了交换次数!
最坏情况下:平均情况下:O(N*N)
3、代码。
void selectsort(int *pData,int left,intright)
{
inti,j,temp;
inttb;
for(i=left;i<right-1;i++)
{
temp= i;
for(j=i+1;j<right;j++)
{
if(pData[j]<pData[temp])
{
temp= j;
}
}
if(i!= temp )
{
tb= pData[temp];
pData[temp]= pData[i];
pData[i]= tb;
}
}
}
4、稳定性 。
由于每次都是选取未排序序列A中的最小元素x与A中的第一个元素交换,很可能破坏了元素间的相对位置,因此选择排序是不稳定的!
此算法较复杂。
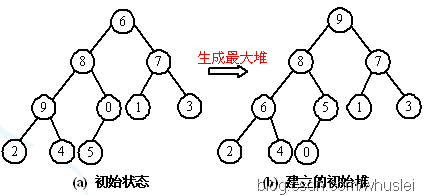
七、堆排序(不稳定,较复杂)
1、思想。
利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或者最小)的记录。也就是说,以最大堆为例,根节点为最大元素,较小的节点偏向于分布在堆底附近。

2、算法复杂度
最坏情况下,接近于最差情况下:O(N*logN),因此它是一种效果不错的排序算法。
3、代码
void HeapAdjust(int array[], int i, intnLength)
{
intnchild;
intntemp;
while(i>=0)
{
nchild= 2 * i + 1;
ntemp= array[i];
if(array[nchild]<ntemp)
{
ntemp= array[nchild];
array[nchild]= array[i];
array[i]= ntemp;
}
if(nchild < nLength - 1)
{
nchild++;
if(array[nchild]<ntemp)
{
ntemp= array[nchild];
array[nchild]= array[i];
array[i]= ntemp;
}
}
i--;
}
}
// 堆排序算法
void HeapSort(int array[],int length)
{
inti,temp;
for(int nL = length; nL>0;nL--)
{
i= nL/2 - 1;
HeapAdjust(array,i,nL);
temp= array[0];
array[0]= array[nL-1];
array[nL-1]= temp;
}
}
4、稳定性 。
堆排序需要不断地调整堆,因此它是一种不稳定的排序。
此算法较复杂。
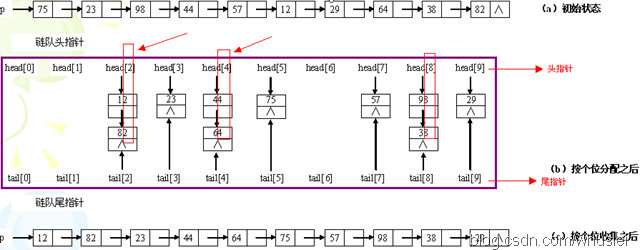
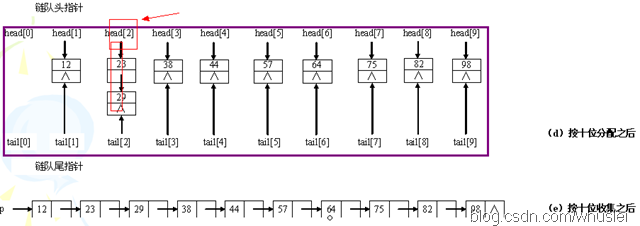
八、基数排序(稳定,较复杂)
1、思想。
它是一种非比较排序。它是根据位的高低进行排序的,也就是先按个位排序,然后依据十位排序……以此类推。示例如下:


2、算法的时间复杂度。
分配需要O(n),收集为O(r),其中r为分配后链表的个数,以r=10为例,则有0~9这样10个链表来将原来的序列分类。而d,也就是位数(如最大的数是1234,位数是4,则d=4),即"分配-收集"的趟数。因此时间复杂度为O(d*(n+r))。
3、代码。
const int base=10;
struct wx
{
intnum;
wx*next;
wx()
{
next=NULL;
}
};
wx *headn,*curn,*box[base],*curbox[base];
void basesort(int t)
{
int i,k=1,r,bn;
// k,r 分别表示10的幂次方,用来得到相应位上的单个数字,比如 k=10,r=100,数字207,则 十位上 0 = //(207/r)%10
for(i=1;i<=t;i++)
{
k*=base;
}
r=k*base;
//curbox和box中的指针指向相同的位置,当curbox中有新元素时,curbox指向会发生变化,形成box元素为//头指针,curbox元素相当于滑动指针,这样可以通过比较两者的不同来判断指针的走向。
for(i=0;i<base;i++)
{
curbox[i]=box[i];
}
for(curn=headn->next;curn!=NULL;curn=curn->next)
{
bn=(curn->num%r)/k; // bn表示元素相应位上的值,
curbox[bn]->next=curn; //curbox[i]的next指向相应位为i的元素
curbox[bn]=curbox[bn]->next; //此时curbox[i]向后移位,以box[i]为首的链表长度增加
}
curn=headn;
for(i=0;i<base;i++)
{
if(curbox[i]!=box[i])
{
curn->next=box[i]->next;
curn=curbox[i]; //curn此时指向了在box中具有相同值的链表的最后一个,例如 123, //33,783,67,56,在3开头的 元素链表中,此时cur指向了783。
}
}
curn->next=NULL;
}
void printwx()
{
for(curn=headn->next;curn!=NULL;curn=curn->next)
{
cout<<curn->num<<'';
}
cout<<endl;
}
int main()
{
inti,n,z=0,maxn=0;
curn=headn=newwx;
cin>>n;
for(i=0;i<base;i++)
{
curbox[i]=box[i]=newwx;
}
for(i=1;i<=n;i++)
{
curn=curn->next=newwx;
cin>>curn->num;
maxn=max(maxn,curn->num);
}
while(maxn/base>0)
{
maxn/=base;
z++;
}
for(i=0;i<=z;i++)
{
basesort(i);
}
printwx();
return0;
}
4、稳定性。
基数排序过程中不改变元素的相对位置,因此是稳定的。
此算法较复杂。
附录:
本篇文章主要参考了博客http://blog.csdn.net/whuslei/article/details/6442755,作者对排序总结的非常详细,大家感兴趣可以去阅读原文。
另外,http://www.blogjava.net/todayx-org/archive/2012/01/08/368091.html总结的也不错,其中有GIF动态图可以清晰的浏览到算法是如何实现的。
提前声明一下,面试知识点这个系列的文章,有很多借鉴了网上的一些文章,因为我的本意也不是完全原创,而是基于原创进行整理,难免会引用到别人的图或文字。
整理这些知识点时,我会尽量将自己理解消化调后总结,然后表述出来,但为了使大家理解更深刻,不可避免也会引用到别人的内容。当引用到别人写的内容时,我也会尽量注明出处,如果引用的内容忘了或者没有标记原来出处,如涉及到侵权,还请联系我修改。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
欢迎您扫一扫上面的微信公众号,订阅我的个人公众号!
本公众号将以推送Android各种碎片化小知识或小技巧,以及整理Android面试知识点为主,也会不定期将开发老司机日常工作中踩过的坑,平时自学的一些知识总结出来进行分享。每天一点干货小知识把你的碎片时间充分利用起来。