




1摘要
分類在搜索引擎中的應用非常廣泛,這種分類屬性可以方便在rank過程中針對不同類別實現不同的策略,來更好滿足用戶需求。本人接觸分類時間並不長,在剛用SVM做分類的時候對一個現象一直比較困惑,看到大家將各種不同類型特徵,拼接在一起,組成龐大的高維特徵向量,送給SVM,得到想要的分類準確率,一直不明白這些特徵中,到底是哪些特徵在起作用,哪些特徵組合在一起纔是最佳效果,也不明白爲啥這些特徵就能夠直接拼在一起,是否有更好的拼接方式?後來瞭解到核函數以及多核學習的一些思想,臨時抱佛腳看了點,對上面的疑問也能夠作一定解釋,正好拿來和大家一起探討探討,也望大家多多指點。本文探討的問題所列舉的實例主要是圍繞項目中的圖像分類展開,涉及SVM在分類問題中的特徵融合問題。擴展開來對其他類型分類問題,理論上也適用。
關鍵詞: SVM 特徵融合 核函數 多核學習
2基本概念闡述
SVM:支持向量機,目前在分類中得到廣泛的應用
特徵融合:主要用來描述各種不同的特徵融合方式,常見的方式有前期融合,就是前面所描述的將各個特徵拼接在一起,後期融合本文後面會提到
核函數:SVM遇到線性不可分問題時,可以通過核函數將向量映射到高維空間,在高維空間線性可分
多核學習:在利用SVM進行訓練時,會涉及核函數的選擇問題,譬如線性核,rbf核等等,多核即爲融合幾種不同的核來訓練。
3應用背景
在圖片搜索中,會出現這樣的一類badcase,圖像的內容和描述圖像的文本不一致,經常會有文本高相關,而圖像完全不一致的情況。解決這類問題的一個思路就是綜合利用圖像的內容分類屬性和文本的query分類屬性,看兩者的匹配程度做相應策略。
4分類方法的選取
下面就可以談到本文的重點啦,那是如何對圖像分類的呢?
對分類熟悉的同學,馬上可能要說出,這還不easy,抽取各種特徵,然後一拼接,隨便找個分類器,設定幾個參數,馬上分類模型文件就出來啦,80%準確率沒問題。
那這個方法確實不錯也可行,但是有沒有可以改進的地方呢?
這裏可能先要說明下圖像分類的一些特殊性。
圖像的分類問題跟一般的分類問題方法本質上沒太大差異,主要差異體現在特徵的抽取上以及特徵的計算時間上。
圖像特徵的抽取分爲兩部分,一部分是針對通用圖像的特徵,還有一部分則是針對特定類別抽取的特徵。這些特徵與普通的文本特徵不一致的地方在於,一個圖像特徵由於存在分塊、採樣、小波變換等,可能維度就已經很高。譬如常見的MPEG-7標準中提到的一些特徵,邊緣直方圖150維,顏色自相關特徵512維等。在分類過程中,如果將這些特徵拼接在一起直接就可能過千維,但是實際在標註樣本時,人工標註的正負樣本也才幾千張,所以在選擇分類器時,挑選svm,該分類器由於可以在衆多分類面中選擇出最優分界面,以及在小樣本的學習中加入懲罰因子產生一定軟邊界,可以有效規避overfitting。
在特徵的計算時間上,由於圖像處理涉及的矩陣計算過多,一個特徵的計算時間慢的可以達到0.3秒,所以如何挑選出既有效又快速的特徵也非常重要。
5兩種特徵融合方式的比較
那剛纔的方法有什麼問題呢?
仔細想想,大致存在以下幾點問題:
1. 你所提取的所有特徵,全部串在一起,一定合適麼?如果我想知道哪些特徵組合在一起效果很好,該怎麼辦?
2. 用svm進行學習時,不同的特徵最適合的核函數可能不一樣,那我全部特徵向量串在一起,我該如何選擇核函數呢?
3. 參數的選取。不同的特徵即使使用相同的核,可能最適合的參數也不一樣,那麼如何解決呢?
4. 全部特徵都計算,計算時間的花銷也是挺大的
對於剛纔的問題,如果用前期融合,可能是用下面方式來解決:
1. 根據經驗,覺得在樣本中可能表現不錯的特徵加進來,至於組合麼,全部串在一起,或者選幾個靠譜的串一起,慢慢試驗,慢慢調,看哪些特徵有改進就融合在一起
2. 也是根據經驗,選取普遍表現不錯的RBF核,總之結果應該不會差
3. 交叉驗證是用來幹嘛的?驗證調優參數唄,全部特徵融合在一起,再來調,儘管驗證時間長,不要緊,反正模型是離線訓練的,多調會也沒關係。
那是否有更好的選擇方案呢?
多核學習(MKL)可能是個不錯的選擇,該方法屬於後期融合的一種,通過對不同的特徵採取不同的核,對不同的參數組成多個核,然後訓練每個核的權重,選出最佳核函數組合來進行分類。
先看下簡單的理論描述:
普通SVM的分類函數可表示爲:

其中![]() 爲待優化參數,物理意義即爲支持向量樣本權重,
爲待優化參數,物理意義即爲支持向量樣本權重,![]() 用來表示訓練樣本屬性,正樣本或者負樣本,爲計算內積的核函數,
用來表示訓練樣本屬性,正樣本或者負樣本,爲計算內積的核函數,![]() 爲待優化參數。
爲待優化參數。
其優化目標函數爲:
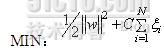
其中![]() 用來描述分界面到支持向量的寬度,
用來描述分界面到支持向量的寬度,![]() 越大,則分界面寬度越小。C用來描述懲罰因子,而
越大,則分界面寬度越小。C用來描述懲罰因子,而![]() 則是用來解決不可分問題而引入的鬆弛項。
則是用來解決不可分問題而引入的鬆弛項。
在優化該類問題時,引入拉格朗日算子,該類優化問題變爲:

其中待優化參數![]() 在數學意義上即爲每個約束條件的拉格朗日系數。
在數學意義上即爲每個約束條件的拉格朗日系數。
而MKL則可認爲是針對SVM的改進版,其分類函數可描述爲:
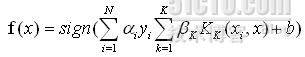
其中,![]() 表示第K個核函數,
表示第K個核函數,![]() 則爲對應的核函數權重。
則爲對應的核函數權重。
其對應的優化函數可以描述爲:
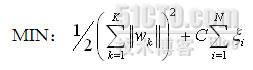
在優化該類問題時,會兩次引入拉格朗日系數,![]() 參數與之前相同,可以理解爲樣本權重,而
參數與之前相同,可以理解爲樣本權重,而![]() 則可理解爲核函數的權重,其數學意義即爲對每個核函數引入的拉格朗日系數。具體的優化過程就不描述了,不然就成翻譯論文啦~,大家感興趣的可以看後面的參考文檔。
則可理解爲核函數的權重,其數學意義即爲對每個核函數引入的拉格朗日系數。具體的優化過程就不描述了,不然就成翻譯論文啦~,大家感興趣的可以看後面的參考文檔。
通過對比可知,MKL的優化參數多了一層![]() 其物理意義即爲在該約束條件下每個核的權重。
其物理意義即爲在該約束條件下每個核的權重。
Svm的分類函數形似上是類似於一個神經網絡,輸出由中間若干節點的線性組合構成,而多核學習的分類函數則類似於一個比svm更高一級的神經網絡,其輸出即爲中間一層核函數的輸出的線性組合。其示意圖如下:

在上圖中,左圖爲普通SVM示例,而全圖則爲MKL示例。其中

爲訓練樣本,而
爲不同的核函數,
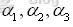
爲支持向量權重(假設三個訓練樣本均爲支持向量),

爲核權重,y爲最終輸出分類結果。
6實驗過程:
以實際對地圖類別的分類爲例,目前用於分類的特徵有A,B,C,D,E,F,G(分別用字母代表某特徵),這些特徵每個的維數平均幾百維。
準備工作:
1. 人工標註地圖類別正負樣本,本次標註正樣本176張,負樣本296張
2. 提取正負訓練樣本圖片的A~G各個特徵
3. 歸一化特徵
4. 爲每個特徵配置對應的核函數,以及參數
工具:
Shogun工具盒:http://www.shogun-toolbox.org/,其中關於該工具的下載,安裝,使用實例都有詳細說明。該工具除了提供多核學習接口之外,幾乎包含所有機器學習的工具,而且有多種語言源碼,非常方便使用。
結果測試:
經過大約5分鐘左右的訓練,輸出訓練模型文件,以及包含的核函數權重、準確率。
在該實例中,7個特徵分別用七個核,其權重算出來爲:
0.048739 0.085657 0.00003 0.331335 0.119006 0.00000 0.415232,
最終在測試樣本上準確率爲:91.6%
爲了節省特徵抽取的時間,考慮去掉權重較小的特徵A、C、F,
拿剩下4個核訓練,幾分鐘後,得到核函數權重如下:
0.098070 0.362655 0.169014 0.370261,
最終在測試樣本上準確率爲:91.4%
在這次訓練中,就可以節約抽取A、C、F特徵的訓練時間,並且很快知道哪些特徵組合在一起會有較好的結果。
實驗的幾點說明:
1. 該類別的分類,因爲樣本在幾百的時候就已經達到不錯效果,所以選取數目較少。
2. 該實驗是針對每個特徵選擇一個核,且每個核配置固定參數,實際中如果時間允許,可以考慮每個特徵選不同核,同一核可以選取不同參數,這樣可以得到稍微更好的結果。
參考文章:
Large Scale Multiple Kernel Learning
SimpleMKL
Representing shape with a spatial pyramid kernel
參考代碼:http://www.shogun-toolbox.org/doc/cn/current/libshogun_examples.html,
7個人經驗與總結:
1. 多核學習在解釋性上比傳統svm要強。多核學習可以明顯的看到各個子核中哪些核在起作用,哪些核在一起合作效果比較好。
2. 關於參數優化。曾經做過實驗,關於同一特徵選用同一核,但是不同參數,組合成多個核,也可以提升分類準確率。
3. 多核學習相比前期特徵融合在性能上會有3%~5%左右的提升。
4. 通過特徵選擇,可以節約特徵計算時間。
by wenshilei