




一、優化方向
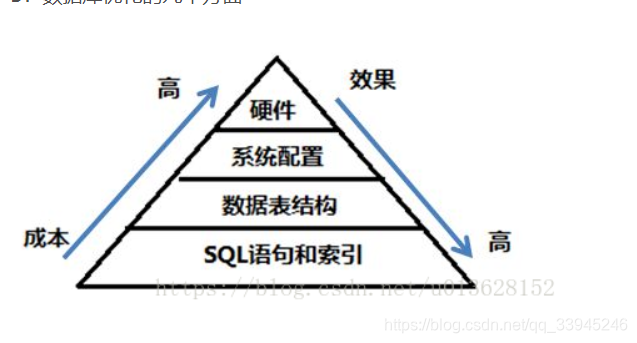](https://pic1.xuehuaimg.com/proxy/csdn/https://img-blog.csdnimg.cn/20200306094952583.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMzOTQ1MjQ2,size_16,color_FFFFFF,t_70)
可以看出來,數據結構、SQL、索引是成本最低,且效果最好的優化手段。
數據庫優化從以下幾個方面優化:
-
數據庫設計—三大範式、字段、表結構
-
數據庫索引
-
存儲過程 (模塊化編程,可以提高速度)
-
分表分庫 (水平分割,垂直分割)
-
主從複製、讀寫分離
-
SQL 調優
-
對 MySQL 配置優化 (配置最大併發數 my.ini, 調整緩存大小)
-
定時清除不需要的數據,定時進行碎片整理
二、具體優化方案
(一)數據庫設計—三大範式、字段、表結構
1.根據數據庫三範式來進行表結構的設計。設計表結構時,就需要考慮如何設計才能更有效的查詢。
- 第一範式:數據表中每個字段都必須是不可拆分的最小單元,也就是確保每一列的原子性;
- 第二範式:滿足一範式後,表中每一列必須有唯一性,都必須依賴於主鍵;
- 第三範式:滿足二範式後,表中的每一列只與主鍵直接相關而不是間接相關 (外鍵也是直接相關),字段沒有冗餘。
2.其他:
- 儘量使用 TINYINT、SMALLINT、MEDIUM_INT 作爲整數類型而非 INT,如果非負則加上 UNSIGNED
- VARCHAR 的長度只分配真正需要的空間
- 儘量使用整數代替字符串類型
- 單表不要有太多字段,建議在 20 以內
- 避免使用 NULL 字段,很難查詢優化且佔用額外索引空間
- 不建議使用 select * from t ,用具體的字段列表代替 “*”,不要返回用不到的任何字段。儘量避免向客戶 端返回大數據量,若數據量過大,應該考慮相應需求是否合理
- 表與表之間通過一個冗餘字段來關聯,要比直接使用 JOIN 有更好的性能
- select count (*) from table;這樣不帶任何條件的 count 會引起全表掃描
(二)索引
索引也算數據庫設計的一部分
1.一般來說,應該在這些列上創建索引:
- 在經常需要搜索的列上,可以加快搜索的速度;
- 在作爲主鍵的列上,強制該列的唯一性和組織表中數據的排列結構;
- 在經常用在連接的列上,這些列主要是一些外鍵,可以加快連接的速度;
- 在經常需要根據範圍進行搜索的列上創建索引,因爲索引已經排序,其指定的範圍是連續的;
- 在經常需要**排序的列(group by 或者 order by)**上創建索引,因爲索引已經排序,這樣查詢可以利用索引的排序,加快排序查詢時間;
- 在經常使用在 WHERE 子句中的列上面創建索引,加快條件的判斷速度。
總結就是:唯一、不爲空、經常被查詢的字段
2.對於有些列不應該創建索引:
- 對於那些在查詢中很少使用或者參考的列不應該創建索引。
- 對於那些只有很少數據值的列也不應該增加索引。
- 對於那些定義爲 text, image 和 bit 這種數據量很大的數據類型的列不應該增加索引。
- 當修改性能遠遠大於檢索性能時,不應該創建索引。修改性能和檢索性能是互相矛盾的。當增加索引時,會提高檢索性能,但是會降低修改性能。當減少索引時,會提高修改性能,降低檢索性能。因此,當修改性能遠遠大於檢索性能時,不應該創建索引。
3.索引失效
在以下這些情況種,執行引擎將放棄使用索引而進行全表掃描
-
在 where 子句中使用**!= 或 <> 操作符**
-
在 where 子句中使用 or 來連接條件,當連接的字段有字段沒有索引時,將導致所有字段的索引失效
-
在 where 子句字段進行 null 值判斷,
-
在 where 子句中 like 的模糊匹配以 % 開頭
-
在 where 子句中對索引進行表達式運算或函數操作
-
如果執行引擎估計使用全表掃描要比使用索引快,則不使用索引
(三)主從複製
1.定義:
在實際的生產環境中,對數據庫的讀和寫都在同一個數據庫服務器中,是不能滿足實際需求的。無論是在安全性、高可用性還是高併發等各個方面都是完全不能滿足實際需求的。因此,通過主從複製的方式來同步數據,再通過讀寫分離來提升數據庫的併發負載能力。
作用:數據庫備份,讀寫分離,高可用,集羣.
2.過程:
-
在每個事務更新數據完成之前,master 在二進制日誌記錄這些改變。寫入二進制日誌完成後,master 通知存儲引擎提交事務。
-
Slave 將 master 的 binary log 複製到其中繼日誌。首先 slave 開始一個工作線程(I/O),I/O 線程在 master 上打開一個普通的連接,然後開始 binlog dump process。binlog dump process 從 master 的二進制日誌中讀取事件,如果已經跟上 master,它會睡眠並等待 master 產生新的事件,I/O 線程將這些事件寫入中繼日誌。
-
Sql slave thread(sql 從線程)處理該過程的最後一步,sql 線程從中繼日誌讀取事件,並重放其中的事件而更新 slave 數據,使其與 master 中的數據一致,只要該線程與 I/O 線程保持一致,中繼日誌通常會位於 os 緩存中,所以中繼日誌的開銷很小。
(四)分庫分表
主從複製中,從數據庫可以通過增加數量不斷擴張,但是主數據庫不能輕易增加,這個時候可以考慮分表分庫。
1.分表方式
水平分割(按行)、垂直分割 (按列)
- 垂直拆分:垂直拆分就是要把表按模塊劃分到不同的數據庫中,數據庫按模塊和功能把表劃分出來,趨向於服務化
- 水平拆分:水平拆分就是要把一個表按照一定的規則把數據劃分到不同的表或數據庫中。比如按時間,賬號規則,年份,取模算法等.
2.分表場景
- 根據經驗,mysql 表數據一般達到百萬級別,查詢效率就會很低。
- 一張表的某些字段值比較大並且很少使用。可以將這些字段隔離成單獨一張表,通過外鍵關聯,例如考試成績,我們通常關注分數,不關注考試詳情。
3.水平分表策略
- 按時間分表:當數據有很強的實效性,例如微博的數據,可以按月分割。
- 按區間分表:例如用戶表 1 到一百萬用一張表,一百萬到兩百萬用一張表。
- hash 分表:通過一個原始目標 id 或者是名稱按照一定的 hash 算法計算出數據存儲的表名。
4.分表缺點:
- 分頁查詢困難
- 查詢非常受限
(五)SQL調優
SQL最常見的方式是,由自帶的慢查詢日誌或者開源的慢查詢系統定位到具體的出問題的 SQL,然後使用 explain、profile 等工具來逐步調優,最後經過測試達到效果後上線。
1.開啓慢查詢
(1)定義:
MySQL 默認設置 10s 沒有返回結果的,屬於慢查詢,並存到日誌中 (在 my.ini 可以指定慢查詢日誌目錄).
(2)開啓慢查詢
-
slow_query_log 慢查詢開啓狀態。
-
slow_query_log_file 慢查詢日誌存放的位置(這個目錄需要 MySQL 的運行帳號的可寫權限,一般設置爲 MySQL 的數據存放目錄)。
-
long_query_time 查詢超過多少秒才記錄。
以上三個參數可以在數據庫的配置文件中設定開啓,也可以在在mysql命令行通過set命令開啓。
當在配置文件中開啓慢查詢日誌記錄之後,就會在指定的存放目錄生成日誌文件。
2.分析慢查詢—explain
當我們獲得慢查詢的日誌之後,查看日誌,觀察那些語句執行是慢查詢,在該語句之前加上explain再次執行,explain 會在查詢上設置一個標誌,當執行查詢時,這個標誌會使其返回關於在執行計劃中每一步的信息,而不是執行該語句。它會返回一行或多行信息,顯示出執行該計劃中的每一部分和執行次序.
explain通常用於查看索引是否生效
顯示字段如下:
| id | SELECT 識別符。這是 SELECT 的查詢序列號 |
| select_type |
SELECT 類型,可以爲以下任何一種:
|
| table |
輸出的行所引用的表 |
| type |
聯接類型。下面給出各種聯接類型,按照從最佳類型到最壞類型進行排序:
|
| possible_keys |
指出 MySQL 能使用哪個索引在該表中找到行 |
| key | 顯示 MySQL 實際決定使用的鍵 (索引)。如果沒有選擇索引,鍵是 NULL。 |
| key_len | 顯示 MySQL 決定使用的鍵長度。如果鍵是 NULL, 則長度爲 NULL。 |
| ref | 顯示使用哪個列或常數與 key 一起從表中選擇行。 |
| rows | 顯示 MySQL 認爲它執行查詢時必須檢查的行數。多行之間的數據相乘可以估算要處理的行數。 |
| filtered | 顯示了通過條件過濾出的行數的百分比估計值。 |
| Extra |
該列包含 MySQL 解決查詢的詳細信息
|