




算法簡介
手寫數字識別是KNN算法一個特別經典的實例,其數據源獲取方式有兩種,一種是來自MNIST數據集,另一種是從UCI歐文大學機器學習存儲庫中下載,本文基於後者講解該例。
基本思想就是利用KNN算法推斷出如下圖一個32x32的二進制矩陣代表的數字是處於0-9之間哪一個數字。
數據集包括兩部分,一部分是訓練數據集,共有1934個數據;另一部分是測試數據集,共有946個數據。所有數據命名格式都是統一的,例如數字5的第56個樣本——5_56.txt,這樣做爲了方便提取出樣本的真實標籤。
數據的格式也有兩種,一種是像上圖一樣由0、1組成的文本文件;另一種則是手寫數字圖片,需要對圖片做一些處理,轉化成像上圖一樣的格式,下文皆有介紹。
算法步驟
- 收集數據:公開數據源
- 分析數據,構思如何處理數據
- 導入訓練數據,轉化爲結構化的數據格式
- 計算距離(歐式距離)
- 導入測試數據,計算模型準確率
- 手寫數字,實際應用模型
由於所有數據皆由0和1構成,所以不需要數據標準化和歸一化這一步驟
算法實現
處理數據
在計算兩個樣本之間的距離時,每一個屬性是一一對應的,所以這裏將32x32的數字矩陣轉化成1x1024數字矩陣,方便計算樣本之間距離。
#處理文本文件
def img_deal(file):
#創建一個1*1024的一維零矩陣
the_matrix = np.zeros((1,1024))
fb = open(file)
for i in range(32):
#逐行讀取
lineStr = fb.readline()
for j in range(32):
#將32*32=1024個元素賦值給一維零矩陣
the_matrix[0,32*i+j] = int(lineStr[j])
return the_matrix計算歐式距離
numpy有一個tile方法,可以將一個一維矩陣橫向複製若干次,縱向複製若干次,所以將一個測試數據經過tile方法處理後再減去訓練數據,得到新矩陣後,再將該矩陣中每一條數據(橫向)平方加和並開根號後即可得到測試數據與每一條訓練數據之間的距離。
下一步將所有距離升序排列,取到前K個,並在這個範圍裏,每個數字類別的個數,並返回出現次數較多那個數字類別的標籤。
def classify(test_data,train_data,label,k):
Size = train_data.shape[0]
#將測試數據每一行復制Size次減去訓練數據,橫向複製Size次,縱向複製1次
the_matrix = np.tile(test_data,(Size,1)) - train_data
#將相減得到的結果平方
sq_the_matrix = the_matrix ** 2
#平方加和,axis = 1 代表橫向
all_the_matrix = sq_the_matrix.sum(axis = 1)
#結果開根號得到最終距離
distance = all_the_matrix ** 0.5
#將距離由小到大排序,給出結果爲索引
sort_distance = distance.argsort()
dis_Dict = {}
#取到前k個
for i in range(k):
#獲取前K個標籤
the_label = label[sort_distance[i]]
#將標籤的key和value傳入字典
dis_Dict[the_label] = dis_Dict.get(the_label,0)+1
#將字典按value值的大小排序,由大到小,即在K範圍內,篩選出現次數最多幾個標籤
sort_Count = sorted(dis_Dict.items(), key=operator.itemgetter(1), reverse=True)
#返回出現次數最多的標籤
return sort_Count[0][0]測試數據集應用
首先要對訓練數據集處理,listdir方法是返回一個文件夾下所有的文件,隨後生成一個行數爲文件個數,列數爲1024的訓練數據矩陣,並且將訓練數據集中每條數據的真實標籤切割提取存入至labels列表中,即計算距離classify函數中傳入的label。
labels = []
#listdir方法是返回一個文件夾中包含的文件
train_data = listdir('trainingDigits')
#獲取該文件夾中文件的個數
m_train=len(train_data)
#生成一個列數爲train_matrix,行爲1024的零矩陣
train_matrix = np.zeros((m_train,1024))
for i in range(m_train):
file_name_str = train_data[i]
file_str = file_name_str.split('.')[0]
#切割出訓練集中每個數據的真實標籤
file_num = int(file_str.split('_')[0])
labels.append(file_num)
#將所有訓練數據集中的數據都傳入到train_matrix中
train_matrix[i,:] = img_deal('trainingDigits/%s'%file_name_str)然後對測試訓練數據集做與上述一樣的處理,並將測試數據矩陣TestClassify、訓練數據矩陣train_matrix、訓練數據真實標籤labels、K共4個參數傳入計算距離classify函數中,最後計算出模型準確率並輸出預測錯誤的數據。
error = []
test_matrix = listdir('testDigits')
correct = 0.0
m_test = len(test_matrix)
for i in range(m_test):
file_name_str = test_matrix[i]
file_str = file_name_str.split('.')[0]
#測試數據集每個數據的真實結果
file_num = int(file_str.split('_')[0])
TestClassify = img_deal('testDigits/%s'%file_name_str)
classify_result = classify(TestClassify,train_matrix,labels,3)
print('預測結果:%s\t真實結果:%s'%(classify_result,file_num))
if classify_result == file_num:
correct += 1.0
else:
error.append((file_name_str,classify_result))
print("正確率:{:.2f}%".format(correct / float(m_test) * 100))
print(error)
print(len(error))代碼運行部分截圖如下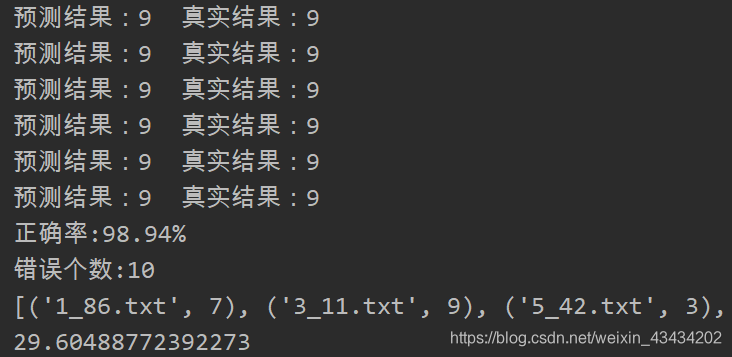
當K = 3時,準確率達到了98.94%,對於這個模型而言,準確率是十分可觀的,但運行效率卻比較低,接近30秒的運行時間。因爲每個測試數據都要與近2000個訓練數據進行距離計算,而每次計算又包含1024個維度浮點運算,高次數多維度的計算是導致模型運行效率低的主要原因。
K值
下圖是K值與模型準確率的關係變化圖,K = 3時,模型準確率達到峯值,隨着K增大,準確率越來越小,所以這份數據的噪聲還是比較小的。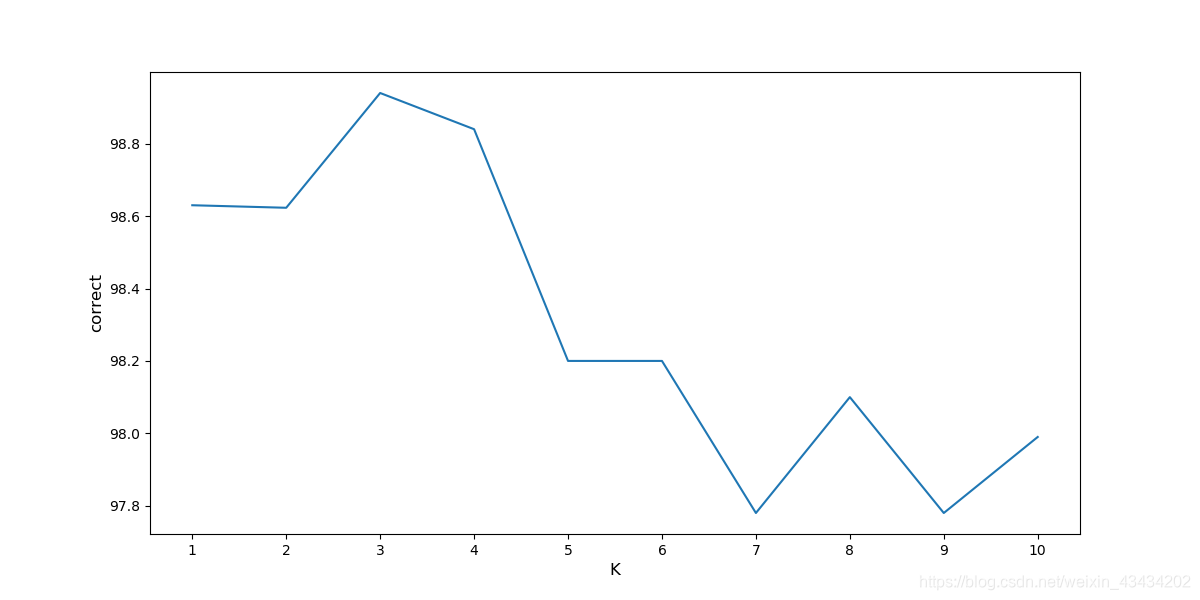
手寫數字測試
建模完成了,模型的準確率也不錯,爲何自己手寫的數字測試一下呢?所以偶就手動寫了幾個數字
正常拍出的圖片是RGB彩色圖片,並且像素也各不相同,所以需要對圖片做兩項處理:轉化成黑白圖片、將像素轉化爲32x32,這樣才符合我們上文算法的要求;對於像素點,數值一般位於0-255,255代表白、0代表黑,但因爲手寫數字像素點顏色並不規範,所以我們設置一個閾值用以判斷黑白之分。
圖片轉文本代碼如下:
def pic_txt():
for i in range(0,10):
img = Image.open('.\handwritten\%s.png'%i)
#將圖片像素更改爲32X32
img = img.resize((32,32))
#將彩色圖片變爲黑白圖片
img = img.convert('L')
#保存
path = '.\handwritten\%s_new.jpg'%i
img.save(path)
for i in range(0,10):
fb = open('.\hand_written\%s_handwritten.txt'%i,'w')
new_img = Image.open('.\handwritten\%s_new.jpg'%i)
#讀取圖片的寬和高
width,height = new_img.size
for i in range(height):
for j in range(width):
# 獲取像素點
color = new_img.getpixel((j, i))
#像素點較高的爲圖片中的白色
if color>170:
fb.write('0')
else:
fb.write('1')
fb.write('\n')
fb.close()整體代碼運行截圖如下: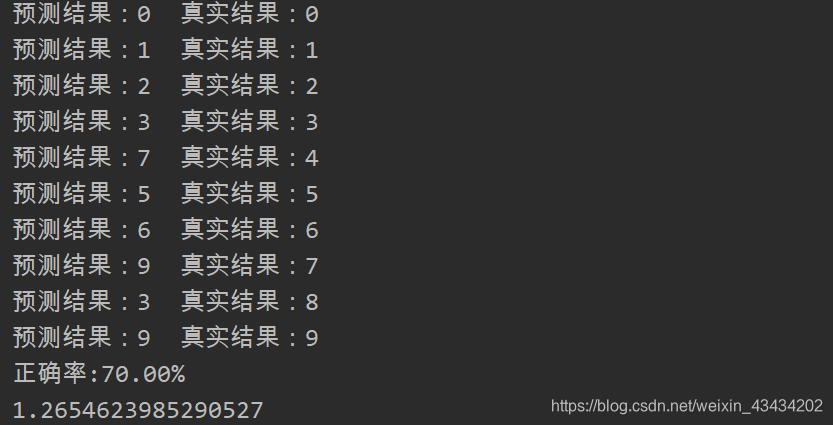
正確率爲70%,畢竟測試數據很少,10個數字中4、7、8三個數字預測錯誤,還算可觀;由於光線問題,有幾個數字左下角會有一些黑影,也會對測試結果產生一定的影響,若避免類似情況,並且多增加一些測試數據,正確率定會得到提升的。
公衆號【奶糖貓】後臺回覆“手寫數字”即可獲取源碼和數據供參考,感謝閱讀。