




06、共享池(shared pool)
共享池是系統全局區 (SGA) 的組成部分,負責緩存各種類型的程序數據。例如,共享池存儲已解析的SQL,PL/SQL代碼,系統參數和數據字典信息。共享池⼏乎涉及數據庫中發⽣的每個操作。例如,如果⽤戶執⾏SQL語句,則Oracle數據庫將訪問共享池。
共享池分爲⼏個⼦組件:
•庫⾼速緩存 (Library cache):是⼀種共享池內存結構,⽤於存儲可執⾏的 SQL和PL/SQL代碼。該緩存包含共享的SQL和PL/SQL區域以及控制結構,例如鎖和庫緩存句柄。當執⾏SQL語句時,數據庫嘗試重⽤以前執⾏的代碼。如果庫⾼速緩存中存在SQL語句的已解析表示形式並且可以共享,則數據庫將重⽤代碼。此操作稱爲軟解析或庫⾼速緩存命中。否則,數據庫必須構建應⽤程序代碼的新的可執⾏版本,這稱爲硬解析或庫⾼速緩存未命中。
•保留池 (Reserved pool):是共享池中的⼀個內存區域,Oracle數據庫可使⽤ 該內存區域來分配連續的⼤塊內存。數據庫從共享池中按照Chunk⽅式分配內存。Chunk允許將⼤型對象(超過5 KB)加載到緩存中,⽽⽆需單個連續區域。這樣,數據庫減少了由於碎⽚⽽耗盡連續內存的可能性。
•數據字典⾼速緩存 (Data dictionary cache):存儲有關數據庫對象的信息(即字典數據)。此緩存也稱爲⾏緩存,因爲它將數據保存爲⾏⽽不是緩衝區。
•服務器結果緩存 (Server result cache):是共享池中的⼀個內存池,並保存結果集。服務器結果緩存包含SQL查詢結果緩存和PL/SQL函數結果緩存,它們共享相同的基礎結構。SQL查詢結果緩存存儲查詢和查詢⽚段的結果。⼤多數應⽤程序都受益於這種性能改進。PL/SQL函數結果緩存存儲函數結果集。結果緩存的良好候 選者是經常調⽤的函數,這些函數依賴於相對靜態的數據。
•其他組件 (Other components):包括隊列,鎖存器,信息⽣命週期管理 (ILM) 位圖表,活動會話歷史記錄 (ASH) 緩衝區和其他次要內存結構。排隊是共享 的內存結構(鎖),⽤於序列化對數據庫資源的訪問。它們可以與會話或事務相關 聯。例如:控制⽂件事務,數據⽂件,實例恢復,介質恢復,事務恢復,作業隊列等。鎖存器⽤作低級序列化控制機制,⽤於保護SGA中的共享數據結構免於同時訪問。例如:⾏⾼速緩存對象,庫⾼速緩存pin和⽇志⽂件並⾏寫⼊。
注意:更多詳細信息,請看如下內容:Shared Pool.
07、⼤池(Large Pool)
⼤池是數據庫管理員可以配置的可選內存區域,可以爲以下各項提供⼤內存分配:
•⽤戶全局區域 (UGA):共享服務器和Oracle XA接⼝的會話內存(⽤於事務與多個數據庫交互)
•I/O 緩衝區 (I/O Buffer Area):I/O服務器進程,並⾏查詢操作中使⽤的消息緩衝區,Recovery Manager (RMAN) I/O從屬進程的緩衝區,以及存儲⾼級排隊內存表。
•延遲插⼊池 (Deferred Inserts Pool):快速提取功能可將數據庫中定義爲MEMOPTIMIZE FOR WRITE的表進⾏⾼頻單⾏數據插⼊。快速攝取的插⼊物也稱 爲延遲插⼊物。它們初在⼤緩衝池中緩衝,然後在每個對象每個會話每次寫⼊1MB或60秒後由空間管理協調器 (SMCO) 和Wxxx從屬後臺進程異步寫⼊磁盤。在SMCO後臺進程進⾏掃描之前,任何會話(包括寫⼊的會話)都⽆法讀取該緩衝池中緩衝的任⼀數據,即使已提交的會話。該池在⼤型池中被初始化是在第⼀⾏數據 插⼊memoptimized 表時進⾏。當有⾜夠的空間時,將從⼤型池中分配2G。如果⼤型池中沒有⾜夠的空間,則會在內部發現並⾃動清除ORA-4031,然後使⽤⼀半的 請求內存⼤⼩重試分配。如果⼤型池中仍然沒有⾜夠的空間,則使⽤512M和256M 重試分配,然後禁⽤該功能,直到重新啓動實例。初始化池後,⼤⼩將保持不變。它不能增⻓或收縮。
•可⽤內存
⼤型池與共享池中的保留空間不同,共享池中的保留空間與從共享池分配的其他 內存使⽤相同的近少使⽤ (LRU) 列表。⼤池沒有LRU列表。內存已分配,在使⽤完之前⽆法釋放。
來⾃⽤戶的請求是單個API調⽤,屬於⽤戶的SQL語句。在專⽤服務器環境中,⼀個服務器進程處理單個客戶端進程的請求。每個服務器進程都使⽤系統資源,包括CPU週期和內存。在共享服務器環境中,將發⽣以下操作:
1.客戶端應⽤程序向數據庫實例發送請求,並且分派進程接收該請求。
-
分派進程將請求放在⼤池中的請求隊列上。
-
下⼀個可⽤的共享服務器進程將處理該請求。共享服務器進程檢查公共請求 隊列中是否有新請求,並以先進先出的⽅式接收新請求。⼀個共享服務器進 程在隊列中接收⼀個請求。
-
共享服務器進程對數據庫進⾏所有必要的調⽤以完成請求。⾸先,共享服務器進程訪問共享池中的庫緩存以驗證請求的項⽬;例如,它檢查表是否存在,⽤戶是否具有正確的特權等等。接下來,共享服務器進程訪問緩衝區⾼速緩存以檢索數據。如果數據不存在,則共享服務器進程將訪問磁盤。不同的共享服務器進程可以處理每個數據庫調⽤。因此,解析查詢,獲取第⼀⾏,獲取下⼀⾏以及關閉結果集的請求可能分別由不同的共享服務器進程處理。由於不同的共享服務器進程可能會處理每個數據庫調⽤,因此⽤戶全局區域 (UGA) 必須是共享內存區域,因爲UGA包含有關每個客戶端會話的信 息。反過來說,UGA包含有關每個客戶端會話的信息,並且必須對所有共享服務器進程可⽤,因爲任何共享服務器進程都可以處理任何會話的數據庫調⽤。
-
請求完成後,共享服務器進程將響應放置在⼤型池中的呼叫分派進程的響應隊列上。每個分派進程都有⾃⼰的響應隊列。
-
響應隊列將響應發送到分派進程。
- 分派進程將完成的請求返回到適當的客戶端應⽤程序。
注意:更多詳細信息,請看如下內容:Large Pool.
08、數據庫⾼速緩衝區(Database Buffer Cache)
數據庫緩衝區⾼速緩存,也稱爲緩衝區⾼速緩存,是系統全局區域 (SGA) 中的存儲區域,⽤於存儲從數據⽂件讀取的數據塊的副本。緩衝區是數據庫塊⼤⼩的內存 塊。每個緩衝區都有⼀個稱爲數據庫緩衝區地址 (DBA) 的地址。同時連接到數據庫實例的所有⽤戶共享對緩衝區⾼速緩存的訪問。緩衝區⾼速緩存的⽬標是優化物理I/O, 並將經常訪問的塊保留在緩衝區⾼速緩存中,並將不經常訪問的塊寫⼊磁盤。
Oracle數據庫⽤戶進程第⼀次需要特定數據時,它將在數據庫緩衝區⾼速緩存中搜索數據。如果進程發現緩存中已存在的數據(緩存命中),則可以直接從內存中讀取數據。如果該進程在緩存中找不到數據(緩存未命中),則它必須在訪問數據之前 將數據塊從磁盤上的數據⽂件複製到緩存中的緩衝區中。通過緩存命中訪問數據⽐通 過緩存未命中訪問數據更快。
⾼速緩存中的緩衝區由複雜算法管理,該算法使⽤近少使⽤ (LRU) 列表和 Touch Count算法的組合。LRU有助於確保近使⽤的塊傾向於保留在內存中,以 ⼤程度地減少磁盤訪問。
數據庫⾼速緩衝區包括以下內容:
•默認池 (Default pool):是通常緩存塊的位置。默認塊⼤⼩爲8 KB。除⾮您⼿動配置單獨的池,否則默認池是唯⼀的緩衝池。其他池的可選配置對默認池⽆效。
•保留池 (Keep pool):適⽤於經常訪問但由於空間不⾜⽽在默認池中過期的塊。保留緩衝池的⽬的是在內存中保留指定的對象,從⽽避免I/O操作。
•回收池 (Recycle pool):⽤於不經常使⽤的塊。回收池可防⽌指定的對象佔⽤緩存中不必要的空間。
•⾮默認緩衝池 (Non-default buffer pools):適⽤於使⽤2 KB,4 KB,16 KB 和32 KB⾮標準塊⼤⼩的表空間。每個⾮默認塊⼤⼩都有其⾃⼰的池。Oracle數據庫以與默認池相同的⽅式管理這些池中的塊。
•數據庫智能閃存緩存 (Flash cache):使您可以使⽤閃存設備來增加緩衝區緩 存的有效⼤⼩,⽽⽆需添加更多主內存。閃存緩存可以通過將數據庫緩存的需頻繁 訪問的數據存儲到閃存中⽽不是從磁盤讀取數據來提⾼數據庫性能。當數據庫請求 數據時,系統⾸先在數據庫緩衝區⾼速緩存中查找。如果找不到數據,則系統將在 數據庫智能閃存緩存中查找。如果它在那⾥找不到數據,則只會在磁盤存儲中查 找。您必須在Oracle Real Application Clusters環境中的所有實例上配置閃存緩存, 或者不配置任何節點的閃存存儲。
•最近最少使⽤列表(LRU):包含指向髒緩衝區和⾮髒緩衝區的指針。LRU 列表有⼀個熱端和⼀個冷端。冷緩衝區是近未使⽤過的緩衝區。熱緩衝區經常被 訪問並且近已經被使⽤。從概念上講,只有⼀個LRU,但是對於數據併發,數據 庫實際上使⽤了多個LRU。
•檢查點隊列 (Checkpoint queue):檢查點隊列是⼀個鏈表結構,是由緩衝區 頭部結構構成;當數據塊被修改後,緩衝區通過此鏈表結構來跟蹤數據塊的修改。鏈表的順序是根據早應⽤於該數據塊的RBA(Redo Block Address)地址排序得到的。
•Flash緩衝區 (Flash Buffer Area):由DEFAULT Flash LRU鏈和KEEP Flash LRU鏈組成。如果沒有數據庫智能閃存緩存,則當進程嘗試訪問某個塊並且該塊在 緩衝區緩存中不存在時,該塊將⾸先從磁盤讀⼊內存(物理讀取)。當內存中緩衝 區⾼速緩存已滿時,將根據近少使⽤ (LRU) 機制將緩衝區從內存中逐出。使⽤ Database Smart Flash Cache,當⼲淨的內存中緩衝區過期時,該緩衝區的內容將通過Database Writer進程 (DBWn) 在後臺寫⼊閃存中,並且緩衝區頭作爲元數據保留在內存中DEFAULT閃存或KEEP閃存LRU列表,具體取決於FLASH_CACHE對象屬性的值。KEEP閃存LRU列表⽤於將緩衝區頭保留在單獨的列表上,以防⽌常規緩衝區頭替換它們。因此,屬於指定爲KEEP的對象的閃存緩衝區標頭傾向於在閃存緩存中保留更⻓時間。如果將FLASH_CACHE對象屬性設置爲NONE,則系統不會在閃存緩存或內存中保留相應的緩衝區。當再次訪問已過期的內存緩衝區時,系統將檢查閃存緩存。如果找到了緩衝區,它將從閃存緩存中讀回它,這僅花費從磁 盤讀取的時間的⼀⼩部分。跨實時應⽤程序羣集 (RAC) 的閃存緩存緩衝區的⼀致性 與緩存融合的維護⽅式相同。因爲閃存⾼速緩存是擴展⾼速緩存,並且直接路徑I/O 完全繞過了緩衝區⾼速緩存,所以此功能不⽀持直接路徑I/O。請注意,系統不會將 髒緩衝區放⼊閃存緩存中,因爲它可能必須將緩衝區讀取到內存中才能對它們進⾏ 檢查點,因爲寫⼊閃存緩存不會計⼊檢查點。
注意:更多詳細信息,請看如下內容:Database Buffer Cache.
09、內存中列式存儲區(In-Memory Area)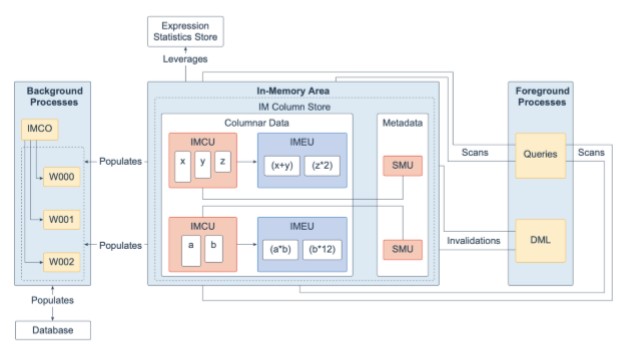
In-Memory存儲區是⼀個可選的SGA組件,其中包含內存中列存儲(IM列存 儲),該存儲區使⽤針對快速掃描進⾏了優化的列格式將表和分區存儲在內存中。IM 列存儲使數據能夠以傳統的⾏格式(在緩衝區⾼速緩存中)和列格式同時在SGA中填充。數據庫透明地將在線事務處理 (OLTP) 查詢(例如主鍵查找)發送到緩衝區⾼速緩存,並將分析和報告查詢發送到IM列存儲。在獲取數據時,Oracle數據庫還可以從同⼀查詢中的兩個內存區域讀取數據。雙格式體系結構不會使內存需求加倍。緩衝區⾼速緩存經過優化,可以以⽐數據庫⼩得多的⼤⼩運⾏。
您應該僅在IM列存儲中填充關鍵的數據。要將對象添加到IM列存儲中,請在創建或更改對象時爲該對象打開INMEMORY屬性。您可以在表空間(對於表空間中的所 有新表和視圖),表,(⼦)分區,物化視圖或對象內的列⼦集上指定此屬性。
IM列存儲以優化的存儲單元(⽽不是傳統的Oracle數據塊)管理數據和元數據。內存中壓縮單元 (IMCU) 是⼀種壓縮的只讀存儲單元,其中包含⼀個或多個列的數 據。快照元數據單元 (SMU) 包含相關IMCU的元數據和事務信息。每個IMCU都映射到 ⼀個單獨的SMU。
表達式統計信息存儲 (ESS) 是⼀個存儲有關表達式評估的統計信息的存儲庫。ESS駐留在SGA中,並且也保留在磁盤上。啓⽤IM列存儲後,數據庫會將ESS⽤於其 內存中表達式(IM表達式)功能。內存中表達單元 (IMEU) 是⽤於存儲實現的IM表達式和⽤戶定義的虛擬列的存儲容器。請注意,ESS獨⽴於IM列存儲。ESS是數據庫的永久組件,不能禁⽤。
從概念上講,IMEU是其⽗IMCU的邏輯擴展。就像IMCU可以包含多個列⼀樣,IMEU可以包含多個虛擬列。每個IMEU都恰好映射到⼀個IMCU,映射到同⼀⾏集。IMEU包含與其關聯的IMCU中包含的數據的表達結果。填充IMCU後,還將填充關聯 的IMEU。
典型的IM表達式包含⼀列或多列(可能帶有常量),並且與表中的⾏具有⼀對⼀的映射關係。例如,⼀個EMPLOYEES表的IMCU包含Weekly_salary列的1-1000⾏。對於此IMCU中存儲的⾏,IMEU計算⾃動檢測到的IM表達式weekly_salary 52,並將 ⽤戶定義的虛擬列Quarterly_salary定義爲weekly_salary 12。IMCU中的第三⾏下映 射到IMEU中的第三⾏下。
In-Memory區細分爲兩個池:⼀個1MB列式數據池,⽤於存儲填充到內存中的實 際列格式數據 (IMCU和IMEU),以及⼀個64K元數據池,⽤於存儲有關對象的元數 據。填充到IM列存儲中。這兩個庫的相對⼤⼩由內部啓發算法確定。In-Memory區中 的⼤部分內存都分配給1MB池。內存區域的⼤⼩由初始化參數INMEMORY_SIZE(默認值爲0)控制,並且⼩⼤⼩必須爲100MB。從Oracle Database 12.2開始,您可以通過ALTER SYSTEM命令將INMEMORY_SIZE參數增加⾄少128MB,來動態增加內存 區域的⼤⼩。請注意,⽆法動態縮⼩內存區域的⼤⼩。
In-Memory表在⾸次訪問表數據或數據庫啓動時會獲取在IM列存儲中分配的IMCU。通過從磁盤格式轉換爲新的內存列式格式,可以創建表的內存副本。每次實例重新啓動時都會完成此轉換,因爲IM列存儲副本僅駐留在內存中。完成此轉換後,表 的內存版本逐漸可⽤於查詢。如果對錶進⾏了部分轉換,則查詢能夠使⽤部分內存版本並轉到磁盤進⾏其餘操作,⽽不必等待整個表都被轉換。
爲了響應查詢和數據操作語⾔ (DML),服務器進程掃描列數據並更新SMU元數據。後臺進程將磁盤中的⾏數據填充到IM列存儲中。In-Memory協調進程 (IMCO) 是啓動後臺填充和重新填充列式數據的後臺進程。空間管理協調進程 (SMCO) 和空間管理⼯作進程 (Wnnn) 是後臺進程,它們代表IMCO實際填充和重新填充數據。DML塊更改將寫⼊緩衝區⾼速緩存,然後再寫⼊磁盤。然後,後臺進程根據元數據失效和查詢請求將磁盤中的⾏數據重新填充到IM列存儲中。
您可以啓⽤ In-Memory 快速啓動功能,以將IM列存儲中的列數據以壓縮列格式寫回到數據庫中的表空間。此功能使數據庫啓動更快。請注意,此功能不適⽤於 IMEU,它們總是從IMCU動態填充。
注意:更多詳細信息,請看如下內容:Introduction to Oracle Database In-Memory.
10、數據庫數據⽂件(Database Data Files)
數據庫是⼀組存儲⽤戶數據和元數據的物理⽂件。元數據由有關數據庫服務器的結構,配置和控制信息組成。您可以將數據庫設計爲多租戶容器數據庫 (CDB) 或⾮容器數據庫 (non-CDB)(20c中只⽀持多租戶結構)。
CDB由⼀個CDB根容器(也稱爲根),唯⼀的⼀個種⼦可插⼊數據庫(種⼦ PDB),零個或多個⽤戶創建的可插拔數據庫(簡稱爲PDB)以及零個或多個應⽤程序容器組成。整個CDB稱爲系統容器。對於⽤戶或應⽤程序,PDB在邏輯上顯示爲單 獨的數據庫。
CDB根容器名爲CDB $ ROOT,包含多個數據⽂件,控制⽂件,重做⽇志⽂件, 閃回⽇志和歸檔的重做⽇志⽂件。數據⽂件存儲與所有PDB共享的Oracle提供的元數 據和普通⽤戶(每個容器中已知的⽤戶)。
種⼦PDB名爲PDB $ SEED,是系統提供的PDB模板,其中包含可⽤於創建新 PDB的多個數據⽂件。
常規PDB包含多個數據⽂件,這些⽂件包含⽀持應⽤程序所需的數據和代碼。例 如,⼈⼒資源應⽤程序。⽤戶僅與PDB交互,⽽不與種⼦PDB或根容器交互。您可以在CDB中創建多個PDB。多租戶體系結構的⽬標之⼀是每個PDB與應⽤程序具有⼀對 ⼀的關係。
應⽤程序容器是CDB中⽤於存儲應⽤程序數據的PDB的可選集合。創建應⽤程序 容器的⽬的是擁有獨⼀的主應⽤程序定義。CDB中可以有多個應⽤程序容器。
數據庫分爲稱爲表空間的邏輯存儲單元,這些邏輯存儲單元共同存儲所有數據庫 數據。每個表空間由⼀個或多個數據⽂件構成。根容器和常規PDB具有SYSTEM, SYSAUX,USERS,TEMP和UNDO表空間(在常規PDB中爲可選)。種⼦PDB具有 SYSTEM,SYSAUX,TEMP和可選的UNDO表空間。
注意:更多詳細信息,請看如下內容:Introduction to the Multitenant Architecture.
文章正在更新,敬請期待下文~