





朋友扔過來一張圖片,說在整理試題答案,但是試題是圖片,想從網上搜索答案一個一個敲太累了,能不能將圖片裏的文字提取出來?
我一看這是典型的OCR識別啊,直接祭出神器Tesseract.
tesseract -l chi_sim 4.png stdout
目
二 畫 口 “ 口 出再對比原圖一看
哦,不,是不是差的有點兒多?
怎麼辦呢?tesseract識別不利,肯定是咱玩的不溜,爲了識別幾張圖,再進行一通識別訓練是不是有點兒浪費時間?現在都2020年了,各大廠商都提供這種文字識別服務,像我知道的百度都號稱50000次/天免費,就它了,開幹
第一步 登陸 https://login.bce.baidu.com/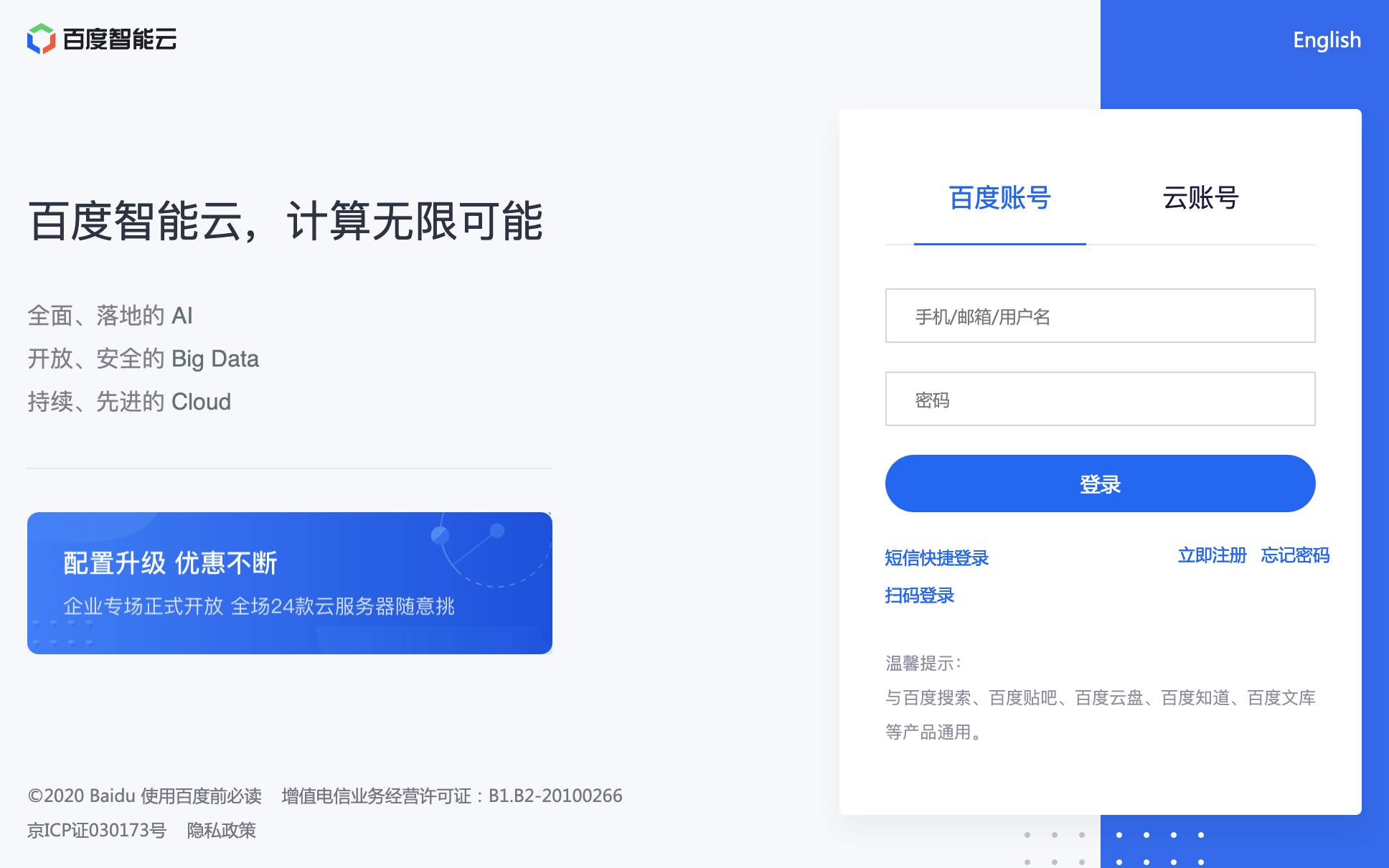
需要百度帳號,是偷是搶,各憑本事吧.
第二步 找到文字識別服務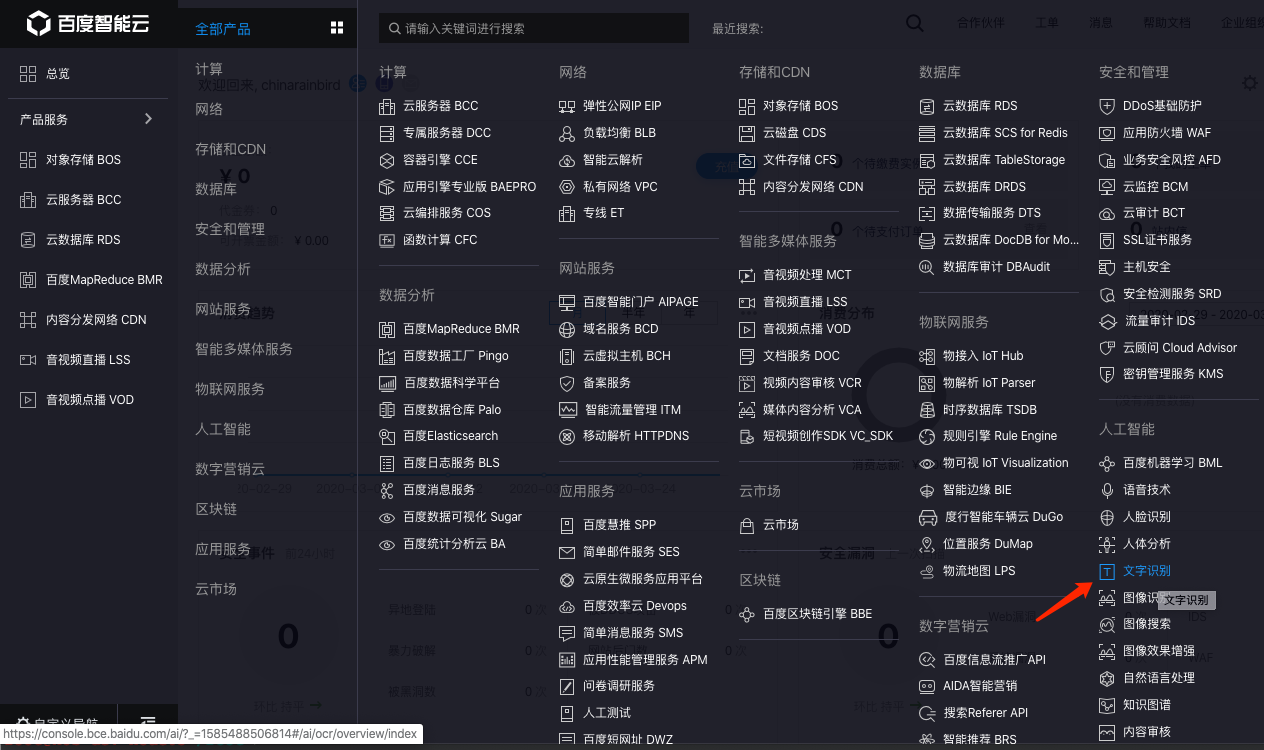
乖乖,這大廠,就是不一樣,產品真多.
第三步 創建一個應用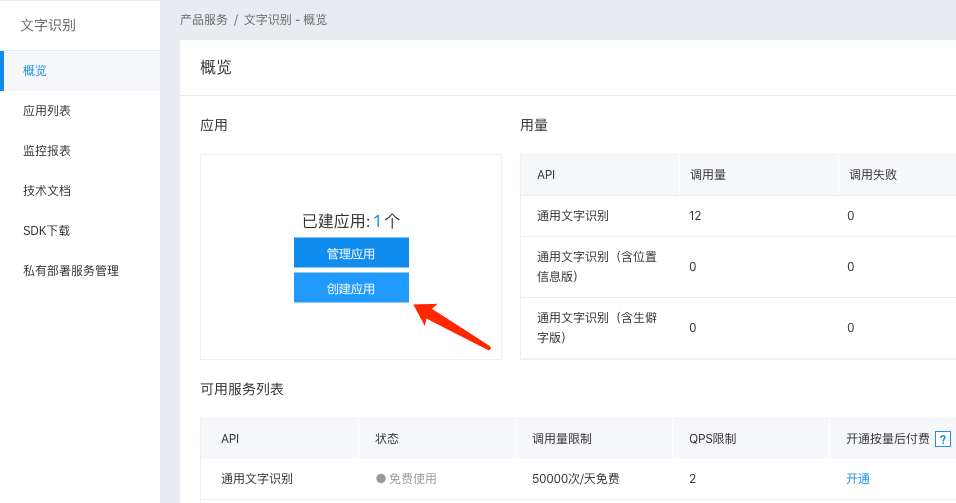
立即創建
第四步 拿到AppID,API Key,Secret Key
下面是見證五行代碼的時刻了
第一步 安裝百度Python SDK
pip install baidu-aip第二步 替換之前拿到 AppID,API Key,Secret Key並修改圖片地址
from aip import AipOcr
APP_ID = 'xxx'
API_KEY = 'xxx'
SECRET_KEY = 'xxx'
IMAGE_URL='~/4.png'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
with open(IMAGE_URL, 'rb') as fp:
res = client.basicGeneral(fp.read())
for words_arr in res.get('words_result'):
print(words_arr['words'].replace('.口','.').replace('.回','.'))第三步 run
$ python ocr-baidu.py
4、知覺的特性包括()
A.整體性
B.選擇性
C.恆常性
D.間接性
E.理解性
5、注意的功能有()
A.調節功能
B.維持功能
C.抑制功能
D.選擇功能
E.啓動功能
嗯 對比圖片,比較完美, 收工!
that's all