




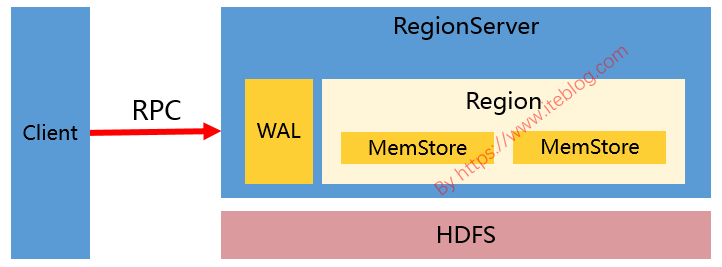
接觸過 HBase 的同學應該對 HBase 寫數據的過程比較熟悉(不熟悉也沒關係)。HBase 寫數據(比如 put、delete)的時候,都是寫 WAL(假設 WAL 沒有被關閉) ,然後將數據寫到一個稱爲 MemStore 的內存結構裏面的,如下圖:
但是,MemStore 畢竟是內存裏面的數據結構,寫到這裏面的數據最終還是需要持久化到磁盤的,生成 HFile。如下圖:
如果想及時瞭解Spark、Hadoop或者Hbase相關的文章,歡迎關注微信公共帳號:iteblog_hadoop

理解 MemStore 的刷寫對優化 MemStore 有很重要的意義,大部分人遇到的性能問題都是寫操作被阻塞(Block)了,無法寫入HBase。本文基於 HBase 2.0.2,並對 MemStore 的 Flush 進行說明,包括哪幾種條件會觸發 Memstore Flush 及目前常見的刷寫策略(FlushPolicy)。
文章目錄
什麼時候觸發 MemStore Flush
有很多情況會觸發 MemStore 的 Flush 操作,所以我們最好需要了解每種情況在什麼時候觸發 Memstore Flush。總的來說,主要有以下幾種情況會觸發 Memstore Flush:
- Region 中所有 MemStore 佔用的內存超過相關閾值
- 整個 RegionServer 的 MemStore 佔用內存總和大於相關閾值
- WAL數量大於相關閾值
- 定期自動刷寫
- 數據更新超過一定閾值
- 手動觸發刷寫
下面對這幾種刷寫進行簡要說明。
Region 中所有 MemStore 佔用的內存超過相關閾值
當一個 Region 中所有 MemStore 佔用的內存(包括 OnHeap + OffHeap)大小超過刷寫閾值的時候會觸發一次刷寫,這個閾值由 hbase.hregion.memstore.flush.size 參數控制,默認爲128MB。我們每次調用 put、delete 等操作都會檢查的這個條件的。
但是如果我們的數據增加得很快,達到了 hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier 的大小,hbase.hregion.memstore.block.multiplier 默認值爲4,也就是128*4=512MB的時候,那麼除了觸發 MemStore 刷寫之外,HBase 還會在刷寫的時候同時阻塞所有寫入該 Store 的寫請求!這時候如果你往對應的 Store 寫數據,會出現 RegionTooBusyException 異常。
整個 RegionServer 的 MemStore 佔用內存總和大於相關閾值
HBase 爲 RegionServer 的 MemStore 分配了一定的寫緩存,大小等於 hbase_heapsize(RegionServer 佔用的堆內存大小)* hbase.regionserver.global.memstore.size。hbase.regionserver.global.memstore.size的默認值是 0.4,也就是說寫緩存大概佔用 RegionServer 整個 JVM 內存使用量的 40%。
如果整個 RegionServer 的 MemStore 佔用內存總和大於 hbase.regionserver.global.memstore.size.lower.limit * hbase.regionserver.global.memstore.size * hbase_heapsize 的時候,將會觸發 MemStore 的刷寫。其中 hbase.regionserver.global.memstore.size.lower.limit 的默認值爲 0.95。
舉個例子,如果我們 HBase 堆內存總共是 32G,按照默認的比例,那麼觸發 RegionServer 級別的 Flush 是 RS 中所有的 MemStore 佔用內存爲:32 * 0.4 * 0.95 = 12.16G。
注意:0.99.0 之前 hbase.regionserver.global.memstore.size 是 hbase.regionserver.global.memstore.upperLimit 參數;hbase.regionserver.global.memstore.size.lower.limit 是 hbase.regionserver.global.memstore.lowerLimit,參見 HBASE-5349
RegionServer 級別的 Flush 策略是每次找到 RS 中佔用內存最大的 Region 對他進行刷寫,這個操作是循環進行的,直到總體內存的佔用低於全局 MemStore 刷寫下
限(hbase.regionserver.global.memstore.size.lower.limit * hbase.regionserver.global.memstore.size * hbase_heapsize)纔會停止。
需要注意的是,如果達到了 RegionServer 級別的 Flush,那麼當前 RegionServer 的所有寫操作將會被阻塞,而且這個阻塞可能會持續到分鐘級別。
WAL數量大於相關閾值
WAL(Write-ahead log,預寫日誌)用來解決宕機之後的操作恢復問題的。數據到達 Region 的時候是先寫入 WAL,然後再被寫到 Memstore 的。如果 WAL 的數量越來越大,這就意味着 MemStore 中未持久化到磁盤的數據越來越多。當 RS 掛掉的時候,恢復時間將會變成,所以有必要在 WAL 到達一定的數量時進行一次刷寫操作。這個閾值(maxLogs)的計算公式如下:
|
|
也就是說,如果設置了 hbase.regionserver.maxlogs,那就是這個參數的值;否則是 max(32, hbase_heapsize * hbase.regionserver.global.memstore.size * 2 / logRollSize)。如果某個 RegionServer 的 WAL 數量大於 maxLogs 就會觸發 MemStore 的刷寫。
WAL 數量觸發的刷寫策略是,找到最舊的 un-archived WAL 文件,並找到這個 WAL 文件對應的 Regions, 然後對這些 Regions 進行刷寫。
定期自動刷寫
如果我們很久沒有對 HBase 的數據進行更新,這時候就可以依賴定期刷寫策略了。RegionServer 在啓動的時候會啓動一個線程 PeriodicMemStoreFlusher 每隔 hbase.server.thread.wakefrequency 時間去檢查屬於這個 RegionServer 的 Region 有沒有超過一定時間都沒有刷寫,這個時間是由 hbase.regionserver.optionalcacheflushinterval 參數控制的,默認是 3600000,也就是1小時會進行一次刷寫。如果設定爲0,則意味着關閉定時自動刷寫。
爲了防止一次性有過多的 MemStore 刷寫,定期自動刷寫會有 0 ~ 5 分鐘的延遲,具體參見 PeriodicMemStoreFlusher 類的實現。
數據更新超過一定閾值
如果 HBase 的某個 Region 更新的很頻繁,而且既沒有達到自動刷寫閥值,也沒有達到內存的使用限制,但是內存中的更新數量已經足夠多,比如超過 hbase.regionserver.flush.per.changes 參數配置,默認爲30000000,那麼也是會觸發刷寫的。
手動觸發刷寫
除了 HBase 內部一些條件觸發的刷寫之外,我們還可以通過執行相關命令或 API 來觸發 MemStore 的刷寫操作。比如調用可以調用 Admin 接口提供的方法:
|
|
分別對某張表、某個 Region 或者某個 RegionServer 進行刷寫操作。也可以在 Shell 中通過執行 flush 命令:
|
|
需要注意的是,以上所有條件觸發的刷寫操作最後都會檢查對應的 HStore 包含的 StoreFiles 文件超過 hbase.hstore.blockingStoreFiles 參數配置的個數,默認值是16。如果滿足這個條件,那麼當前刷寫會被推遲到 hbase.hstore.blockingWaitTime 參數設置的時間後再刷寫。在阻塞刷寫的同時,HBase 還會請求 Split 或 Compaction 操作。
什麼操作會觸發 MemStore 刷寫
我們常見的 put、delete、append、increment、調用 flush 命令、Region 分裂、Region Merge、bulkLoad HFiles 以及給表做快照操作都會對上面的相關條件做檢查,以便判斷要不要做刷寫操作。
MemStore 刷寫策略(FlushPolicy)
在 HBase 1.1 之前,MemStore 刷寫是 Region 級別的。就是說,如果要刷寫某個 MemStore ,MemStore 所在的 Region 中其他 MemStore 也是會被一起刷寫的!這會造成一定的問題,比如小文件問題,具體參見 《爲什麼不建議在 HBase 中使用過多的列族》。針對這個問題,HBASE-10201/HBASE-3149引入列族級別的刷寫。我們可以通過 hbase.regionserver.flush.policy 參數選擇不同的刷寫策略。
目前 HBase 2.0.2 的刷寫策略全部都是實現 FlushPolicy 抽象類的。並且自帶三種刷寫策略:FlushAllLargeStoresPolicy、FlushNonSloppyStoresFirstPolicy 以及 FlushAllStoresPolicy。
FlushAllStoresPolicy
這種刷寫策略實現最簡單,直接返回當前 Region 對應的所有 MemStore。也就是每次刷寫都是對 Region 裏面所有的 MemStore 進行的,這個行爲和 HBase 1.1 之前是一樣的。
FlushAllLargeStoresPolicy
在 HBase 2.0 之前版本是 FlushLargeStoresPolicy,後面被拆分成分 FlushAllLargeStoresPolicy和FlushNonSloppyStoresFirstPolicy,參見 HBASE-14920。
這種策略會先判斷 Region 中每個 MemStore 的使用內存(OnHeap + OffHeap)是否大於某個閥值,大於這個閥值的 MemStore 將會被刷寫。閥值的計算是由 hbase.hregion.percolumnfamilyflush.size.lower.bound、hbase.hregion.percolumnfamilyflush.size.lower.bound.min 以及 hbase.hregion.memstore.flush.size 參數決定的。計算邏輯如下:
|
|
計算邏輯上面已經很清晰的描述了。hbase.hregion.percolumnfamilyflush.size.lower.bound.min 默認值爲 16MB,而 hbase.hregion.percolumnfamilyflush.size.lower.bound 沒有設置。
比如當前表有3個列族,其他用默認的值,那麼 flushSizeLowerBound = max((long)128 / 3, 16) = 42。
如果當前 Region 中沒有 MemStore 的使用內存大於上面的閥值,FlushAllLargeStoresPolicy 策略就退化成 FlushAllStoresPolicy 策略了,也就是會對 Region 裏面所有的 MemStore 進行 Flush。
FlushNonSloppyStoresFirstPolicy
HBase 2.0 引入了 in-memory compaction,參見 HBASE-13408。如果我們對相關列族 hbase.hregion.compacting.memstore.type 參數的值不是 NONE,那麼這個 MemStore 的 isSloppyMemStore 值就是 true,否則就是 false。
FlushNonSloppyStoresFirstPolicy 策略將 Region 中的 MemStore 按照 isSloppyMemStore 分到兩個 HashSet 裏面(sloppyStores 和 regularStores)。然後
- 判斷
regularStores裏面是否有 MemStore 內存佔用大於相關閥值的 MemStore ,有的話就會對這些 MemStore 進行刷寫,其他的不做處理,這個閥值計算和FlushAllLargeStoresPolicy的閥值計算邏輯一致。 - 如果
regularStores裏面沒有 MemStore 內存佔用大於相關閥值的 MemStore,這時候就開始在sloppyStores裏面尋找是否有 MemStore 內存佔用大於相關閥值的 MemStore,有的話就會對這些 MemStore 進行刷寫,其他的不做處理。 - 如果上面
sloppyStores和regularStores都沒有滿足條件的 MemStore 需要刷寫,這時候就FlushNonSloppyStoresFirstPolicy策略久退化成FlushAllStoresPolicy策略了。
刷寫的過程
MemStore 的刷寫過程很複雜,很多操作都可能觸發,但是這些條件觸發的刷寫最終都是調用 HRegion 類中的 internalFlushcache 方法。
|
|
從上面的實現可以看出,Flush 操作主要分以下幾步做的
- prepareFlush 階段:刷寫的第一步是對 MemStore 做 snapshot,爲了防止刷寫過程中更新的數據同時在 snapshot 和 MemStore 中而造成後續處理的困難,所以在刷寫期間需要持有 updateLock 。持有了 updateLock 之後,這將阻塞客戶端的寫操作。所以只在創建 snapshot 期間持有 updateLock,而且 snapshot 的創建非常快,所以此鎖期間對客戶的影響一般非常小。對 MemStore 做 snapshot 是
internalPrepareFlushCache裏面進行的。 - flushCache 階段:如果創建快照沒問題,那麼返回的
result.result將爲 null。這時候我們就可以進行下一步internalFlushCacheAndCommit。其實internalFlushCacheAndCommit裏面包含兩個步驟:flushCache和commit階段。flushCache 階段其實就是將prepareFlush階段創建好的快照寫到臨時文件裏面,臨時文件是存放在對應 Region 文件夾下面的.tmp目錄裏面。 - commit 階段:將
flushCache階段生產的臨時文件移到(rename)對應的列族目錄下面,並做一些清理工作,比如刪除第一步生成的 snapshot。