區別於正則,通配符一般用戶命令行bash環境
- “ * ” 代表任意一個或者多個字符(一般代表所有字符)

- “?” 代表任意一個字符(注意按問好的個數匹配多少個字符)
![linux 正則表達式,sed使用]()
- “;” 兩個命令之間的分隔符

- “#” 配置問漸漸註釋
- “|” 管道
- “~” 用戶家目錄
- “-” 上一次目錄
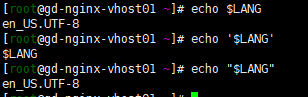
- “$” 變量符
- “/” 路徑分隔符號,也是根的意思
- “>” 或者 1> 重定向,覆蓋原有數據內容
- ">>" 追加重定向,追加內容文件尾部。
- “<” 輸入重定向
- “<<” 追加重定向
- ‘ ’ 單引號,不具有變量置換功能,輸出時所見即所得。
![linux 正則表達式,sed使用]()
- " " 雙引號,具有變量直換功能,解析變量後輸入 結果,不加引號相當於雙引號。
` tab 上面的引號,兩個`中間爲命令,會先執行,等價$()。- “{}” 中間爲命令區塊組合或被哦人能夠序列
- “!” 邏輯運算種的“非”(not)
- “&&” and當前一個指令執行成功時,執行後一個指令
- “||” or當前一個指令執行失敗時,執行後一個指令
- .. 上一個目錄
- . 當前目錄
正則表達式
linux 正則表達式一般以行爲單位處理的。正則表達式和我們常用的通配符特殊字符是有本質的區別。
1,基礎正則第一波字符說明
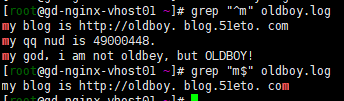
1)“^”,^word 匹配以word開頭的內容。 vi/vim 編輯器裏 ^ 代表一行的開頭
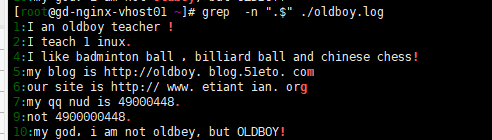
2)"$" ,word$匹配以word結尾的內容。vi/vim 編輯器裏¥代表一行的結尾
3)“^$” 表示空行
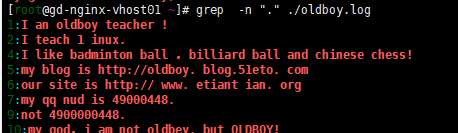
示例:(注意紅色的是匹配的字符,匹配一個字符但是grep打印一行出來)![linux 正則表達式,sed使用]()
grep -n 打印出匹配的行,grep -v 排除匹配, -o 只輸出匹配到的內容 不按行輸出了![linux 正則表達式,sed使用]()
2,基礎正則第二波字符說明:
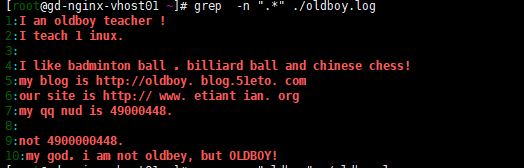
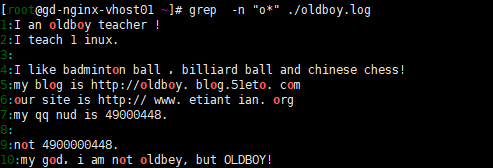
4)"." 代表且只代表任意一個字符。
5) "\" 轉移符號,. 就只代表點本身,讓着有特殊身份意義的字符脫掉馬甲,還原原型。
6)“*”重複 0個或多個前面的一個字符,例如*o 匹配沒有o,有1個o或者多個oooo.
7) "." 匹配所有字符。 延申.以任意多個字符開頭。.$以任意多個字符結尾。
示例:
匹配任意字符(注意其中沒有空行)![linux 正則表達式,sed使用]()
匹配任意所有字符.![linux 正則表達式,sed使用]()
匹配包含oldb.y 的中間的任意字符![linux 正則表達式,sed使用]()
匹配任意一個字符結尾![linux 正則表達式,sed使用]()
匹配以.結尾的字符![linux 正則表達式,sed使用]()
匹配o 0個或者多個ooo 注意空行也匹配了 其實就是所有 但是意義不同![linux 正則表達式,sed使用]()
3,基礎正則第三波字符說明
8)[abc] 匹配字符集合內的任意一個字符[a-zA-Z],[0-9]
9)[^abc] 匹配不包含^後的任意一個字符的內容 或a 或b 或c(注意中括號裏^爲取反,注意與中括號外面的區別 外面是^ 以什麼開頭)
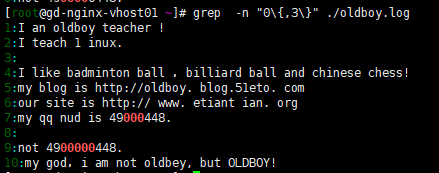
10)a{n,m} 重複n到m次,前一個重複的字符。如果用egrep/sed -r 可以去掉斜線 或者-E ERE 模式
a{n,} 重複至少n次,前一個重複的字符。
a{n} 重複n次,前一個重複的字符。
a{,m} 最多m次
示例重複3次![linux 正則表達式,sed使用]()
重複至少3次![linux 正則表達式,sed使用]()
重複最多3次(注意0次也包含在內)![linux 正則表達式,sed使用]()
grep 一般常用參數:
-i 忽略大小寫的不同,所以大小寫視爲相同
-n 匹配的內容在其行首顯示行號
-v 反向選擇,即顯示沒有‘搜索字符串的那一行’內容的那一行
-E 擴展的grep,即egrep
擴張正則表達式
使用的命令:grep -E 以及egrep
瞭解即可
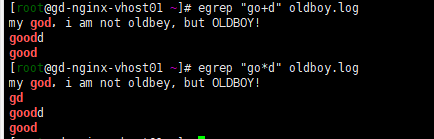
1)+ 表示重複“一個或者一個以上”前面的字符(是0或者多個)
2)?表示重複“0個或一個”前面的字符
3)| 表示同時過濾多個字符串
4)()分組過濾,後向引用。
示例:重複0 一個或者多個( 可以包含0個) +![linux 正則表達式,sed使用]()
重複0個或者1個前面一個字符 ?(. 是有且只有一個)![linux 正則表達式,sed使用]()
過濾多個篩選條件 |![linux 正則表達式,sed使用]()
![linux 正則表達式,sed使用]()
元字符
LINUX企業級正則實戰:
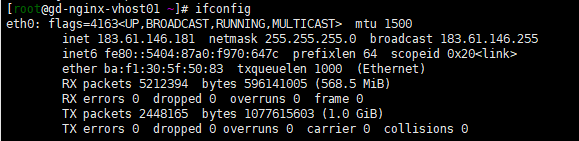
1,取系統IP
第一種方法:()不用正則ifconfig eth0 | sed -n '2p' | sed 's#^.*inet##g' |sed 's#n.*##g' | sed 's#^ ##' ##sed -n '2p' 打印出第二行 sed 's#^.*inet##g' 匹配替換到 inet sed 's#n.*##g' 匹配 取消netmask 以後的數據 sed 's#^ ##' 去除空格 注意 ^.*inet ^.* 表示任意字符開頭 匹配到 inet爲止![linux 正則表達式,sed使用]()
第二種方法
sed -nr 's#支持正則的位置##gp' file(s前的2爲行號)
sed - n 's#()()#\1\2#gp' file 當前面匹配的部分用小括號的時候,第一個括號內容,可以在後面部分1\輸出。同理 \2 也一樣
示例I an oldboy teacher ! sed -nr '1s#^.*n (.*) t.*$#\1#gp' ./oldboy.log ##-r 開啓正則 1s 第一行 ^.*n 以任意字符開頭到n空格結尾(.*) 表示裏面匹配的內容oldboy teacher 過濾以空格t.* 任意字符結尾 \1 引用(.*)的配置匹配內容輸出取IP
![linux 正則表達式,sed使用]()
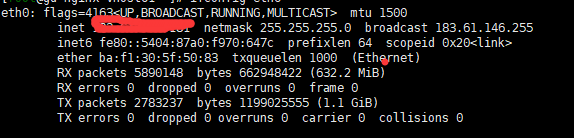
ifconfig eth0 | sed -n -r '2s#^.*et (.*) n.*$#\1#gp'示例取644
![linux 正則表達式,sed使用]()
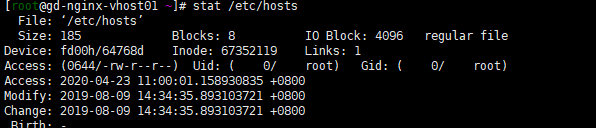
stat /etc/hosts | sed -nr '4s#^.*\(0(.*)/-.*$#\1#gp'