




Java集合
前言:
集合和數組都可以對多個數據進行存儲操作,簡稱Java容器
數組存儲的特點:
1.一旦初始化,長度不可變
2.一旦數組定義好,數據類型也就確定了
3.可以存儲有序可重複的數據,對於無序不可重複的需求不能滿足
4.數組提供的方法有限,對於添加、刪除、插入數據等操作不方便,效率也不高
5.沒有現成的方法獲取數組中實際有效的元素個數
而集合可以靈活的處理數組的一些缺點
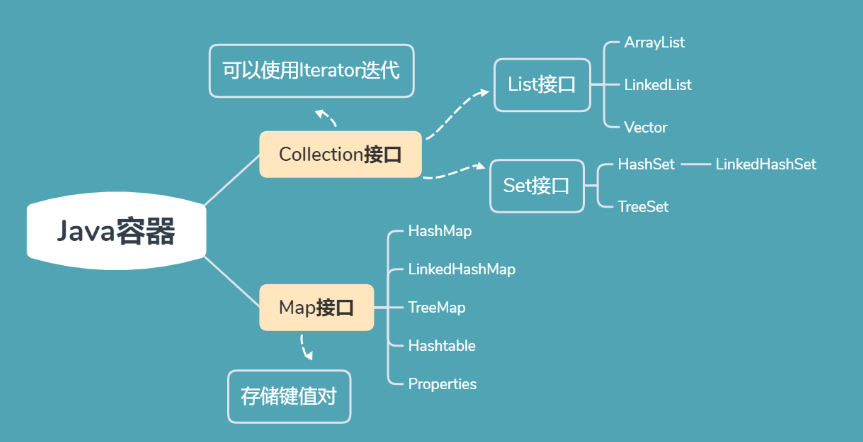
一、Collection接口
單列集合,用來存儲一個一個的對象
1.1 List接口
可以存儲有序的可重複的數據,是動態的數組,可以存儲null值
1. ArrayList
-
jdk1.2實現,底層數據結構:Object[] elementData.
-
線程不安全,但效率高,查找元素的操作方便
-
源碼分析
(1)jdk7: *初始化: ArrayList list=new ArrayList();//底層創建一個長度爲10的Object數組; *添加元素: add元素時,直接想數組的對應下標一次添加 list.add(123)===elementData[0]=new Integer(123) *擴容: 如果此次添加元素的操作導致底層數組容量不夠,則觸發擴容。擴容爲原來的1.5倍。並將原數組的內容複製到新數組 oldCapacity + (oldCapacity >> 1) *注意: 儘量使用帶參數的構造器,指明初始化容量,儘量避免擴容,因爲擴容用到Arrays.copyOf(),這個操作代價很高 ArrayList list=new ArrayList(int capacity);(2)jdk1.8 *初始化: ArrayList list=new ArrayList();//底層創建一個長度爲0的數組Object *添加元素: 第一次調用add()時,底層才創建長度爲10的數組,並將數據加入的數組中 list.add(123) *擴容: 與jdk7無異總結: jdk7中的ArrayList的對象的創建類似於單例模式的餓漢式, jdk8中的ArrayList的對象的創建類似於單例模式的懶漢式,延遲數組創建,節省內存
2. LinkedList
-
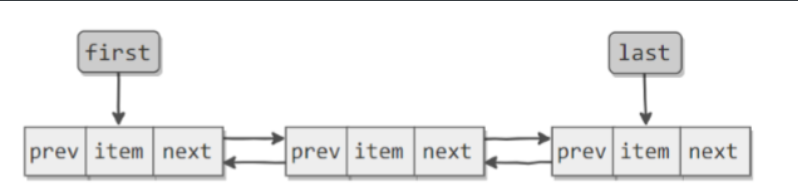
jdk 1.2實現,底層數據結構:雙向鏈表
//節點Node類 private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } } //LinkedList 內部聲明瞭Node類型的兩個屬性first和last,默認爲null transient Node<E> first; transient Node<E> last;
-
線程不安全,對於頻繁的插入和刪除操作效率較高
-
源碼分析
*初始化: LinkedList lis=new LinkedList();//內部聲明瞭Node類型的兩個屬性first和last,默認爲null *添加元素: list.add(123);//將123封裝到Node中,創建了Node對象 其中,Node類的定義體現了LinkedList的雙向鏈表的說法
3.Vector
-
jdk1.0實現,List接口的古老實現類,底層數據結構:Object[] elementData
-
線程安全,但效率不高
public synchronized boolean isEmpty() { return elementCount == 0; } -
源碼分析:
*初始化: jdk7和jdk8中通過Vector()構造器創建對象時,底層都創建了長度爲10的數組 *擴容: 默認擴容爲原來的數組長度的2倍
4.List接口常用方法
* 增:add(Object obj)
* 刪:remove(int index)/remove(Object obj)--remove(new Integer(2))
* 改:set(int index,Object ele)
* 查:indexOf(Obj obj)/lastIndexOf(Obj obj)/get(int index)
* 插:add(int index,Object obj)
* 長度:int size();
* 遍歷:
Iterator 迭代器方式(hasnext(),next()){next:先下移指針,再返回元素。開始是在第一個元素的前一位置}
foreach()
普通的循環5.怎樣得到一個下線程安全的List
1.使用Vector--不建議,同步的,訪問速度慢,開銷大
2.Collections.synchronizedList(list)
List<String> list = new ArrayList<>();
List<String> synList = Collections.synchronizedList(list);
3.concurrent併發包下的CopyOnWriteArrayList<>()
List<String> list = new CopyOnWriteArrayList<>();
6.CopyOnWriteArrayList
1.讀寫分離:
寫操作在一個複製的數組進行,讀操作還是在原數組進行,互不影響
寫操作需要加鎖,防止併發寫入時導致寫入數據丟失
寫操作結束後要把原始數組指向新的複製數組
2.特點:寫時複製,讀寫分離。在寫的時候,允許讀操作,可以提高讀操作的性能
3.適合場景:讀多寫少
//寫操作加鎖
public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } }
final void setArray(Object[] a) { array = a; }
//讀操作
@SuppressWarnings("unchecked") private E get(Object[] a, int index) { return (E) a[index]; }
缺陷:
1.2 Set接口
(1)存儲無序的不可重複的數據
以HashSet爲例說明:
(1)無序性:不等於隨機性,存儲的數據在底層數組中並非按照數組索引的順序添加, 而是根據數組的哈希值進行添加
(2)不可重複性:保證添加的元素按照equals()判斷時,不能返回true
即相同的元素只能添加一個
(2)向Set中添加的數據,其所在的類一定要重寫hashCode()和equals()
(3)重寫的hashCode()和equals()儘可能保持一致性,相等的對象必須具有相等的散列碼
1.HashSet
-
底層數據結構:HashMap(),數組+鏈表
-
線程不安全,可以存儲null
-
源碼分析
添加元素的過程:以HashSet爲例 (1)調用元素a所在類的hashCode()方法,計算元素a的哈希值 (2)此哈希值接着通過某種算法計算出HashSet底層數組的存放位置(即爲:索引位置) (3)判斷數組此位置是否已有元素: 如果沒有,則元素添加成功,---》情況1 如果有其他元素b(或以鏈表形式存在的多個元素),則比較元素a與元素b的hash值; (4)如果hash值不相同,則元素a添成功---》情況2 如果hash值相同,進而需要調用元素a所在equals()方法, (5) equals()方法返回true,元素a添加失敗 equals()返回false,則元素a添加成功---》情況3 說明: 對於添加成功的情況2和3而言,元素a與已經存在指定索引位置上數據以鏈表的方式存儲 jdk7:元素a放到數組中,指向原來的元素,鏈表中a在首位 jdk8:原來數組中的元素指向a,鏈表中a放在尾部 總結: 七上八下
2.LinkedHashSet
-
是HashSet的子類,因爲添加了Linked,所以遍歷內部數據時 可以按照添加的順序遍歷
-
對於頻繁的遍歷操作,效率高於HashSet
-
源碼分析:底層是LinkedHashMap
LinkedHashSet作爲HashSet的子類,在添加數據的同時, 每個數據還維護兩個引用,記錄此數據前一個數據和後一個數據 優點:對於頻繁的遍歷操作,LinkedHashSet效率高於HashSet
3.TreeSet
-
底層數據結構:紅黑樹,可以按照添加元素的指定屬性進行排序
-
源碼分析
1.向TreeSet中添加的數據,要求是相同的類對象,不能添加不同類的對象 2.兩種排序方式:自然排序和定製排序 3.自然排序中,比較兩個對象是否相同的標準爲compareTo()返回0,不再是equals() 4.定製排序中,比較兩個對象是否相同的標準爲compa()返回0,不再是equals() 5.構造器可以傳入一個比較器做參數 public TreeSet(Comparator<? super E> comparator) { this(new TreeMap<>(comparator)); } @Test public void test4(){ Comparator comparator=new Comparator() { //按照年齡從小到大排列 @Override public int compare(Object o1, Object o2) { if (o1 instanceof Person && o2 instanceof Person) { Person p1 = (Person) o1; Person p2 = (Person) o2; return Integer.compare(p1.age,p2.age); }else { throw new RuntimeException("輸入的數據類型不匹配"); } } }; TreeSet set1=new TreeSet(comparator);//將比較器傳進去 set1.add(new Person("ZhaoMin", 20)); set1.add(new Person("WangYiBo", 22)); set1.add(new Person("XiaoZhan", 28)); set1.add(new Person("XiaoZhan", 26)); Iterator iterator=set1.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } }
4.常用方法
使用的都是Collection中聲明過的方法
5.TreeSet\HashSet\LinkedHashSet的區別

二、Map接口
-
雙列集合,存儲key-value數值對的數據。entry{key,value}
- Map中的key:
無序的不可重複的,用Set存儲所有的key;
key所在類要重寫equals和hashcode
3.Map中的value:
無序的、可重複的,使用Collection存儲所有的value
value所在的類要重寫equals
4.Map中的entry:
無序的、不可重複的
使用Set存儲所有的entry
1.HashMap
-
Map的主要實現類,線程不安全,效率高。
- 可以存儲null的key和value,鍵值對

-
底層數據結構:
1.7:數組+鏈表
1.8:數組+鏈表+紅黑樹
- 源碼分析:
(1)jdk1.7
*初始化:
HashMap map=new HashMap();//在實例化以後,底層創建了長度爲16的一維數組Entry[] table
*底層結構:
數組+鏈表
*put(key,value):
(1)首先調用key1所在類的hashCode()計算key1的哈希值,此哈希值經過某種算法以後,得到在數組Entry中的存放位置;
(2)如果此位置的上的數據爲空,則key1-value1添加成功---情況1
(3)如果此位置上的數據不爲空,(意爲着在此位置已經存在一個或多個數據(以鏈表形式存在)),比較key1和已經存在的一個或多個數據的哈希值:
都不相同:key1-value1添加成功---情況2
和某一數據(key2-value2)相同,繼續比較:調用key1所在類的equals(key2):
如果equals()返回false:key1-value1添加成功---情況3
如果equals()返回true:使用value1替換value2
補充:關於情況2、3:此時key1-value1和原來的數據以鏈表的形式存儲
*擴容:在不斷添加的過程,會涉及到擴容問題,
默認的擴容方式:當超出臨界值12(且要存放放入位置非空)時, 擴容爲原來容量的2倍,並將原有的數據複製過來
(2)jdk8:
*初始化:
new HashMap();//底層沒有創建一個長度爲16的數組
*map.put(key,value):
-首次調用put()方法創建一個長度爲16的數組Node[]
-與1.7類似
-使用紅黑樹:
當數組中的某一個索引位置上的元素以鏈表形式存在的數據個數>8,且當前數組的長度>64時,此時此索引位置上的索引數據改爲使用紅黑樹存儲,提高效率,
*底層結構:
數組+鏈表+紅黑樹
*補充常量:
* EFAULT_INITIAL_CAPACITY:HashMap的默認容量:16
* DEFAULY_LOAD_FACTORY:HashMap的默認加載因子:0.75
* threshold:擴容的臨界值=容量*填充因子: 16*0.75》=12
* TREEIFY_THRESHOLD:Bucket中鏈表長度大於該默認值,轉化爲紅黑樹:8
當小於該值師,又轉爲鏈表。8--符合泊松分佈
紅黑樹使用的頻率不高,到8的時候按照泊松分佈,出現的概率非常小 0.000000006
* MIN_TREEIFY_CAPACITY:桶中的Node被樹化時最小的hash表容量:64
* 擴容是爲了儘量減少鏈表的使用
-
負載因子值得大小對HashMap有什麼影響
(1)負載因子的大小決定了HashMap的數據密度 (2)負載因子越大,密度越大,越容易碰撞,數組中鏈表越長,造成查詢、插入時比較的次數增多,性能下降 (3)負載因子越小,越容易觸發擴容,數據密度越小,發生碰撞機率變小,數組中鏈表越短,查詢和插入時比較次數越少,性能會更高。 但會浪累一定的內容空間,而且經常擴容影響性能。建議初始化時預設大一點的空間。 (4)負載因子設置爲0.7-0.75,此時平均檢索長度接近於常數
6.實現細節:
(1)確定桶的下標(key在數組中的索引)
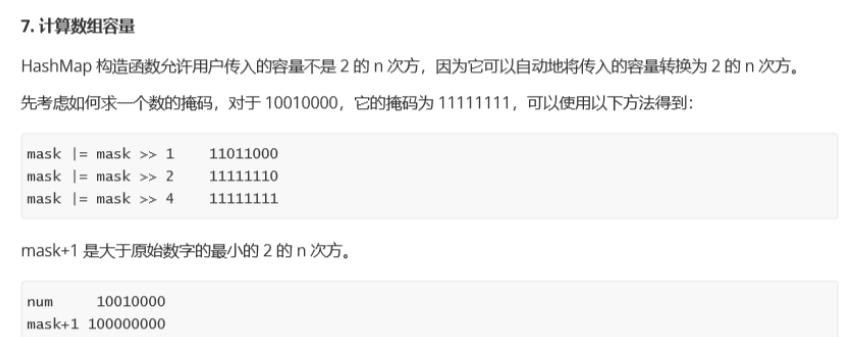
①取模:hash%capacity()---性能不高,如果hash爲負值,則索引也爲負,不可取
②位運算:hash&(length-1)--提高性能,解決負數問題,length=2^n
hash&(length-1),length-1=11111...,所以&之後得到的數組下標肯定在
0--length-1(2^n-1)的範圍內
爲什麼是2^n,就是爲了讓它-1之後得到的是一個二進制表示全爲1的結果
(2)擴容--動態擴容
擴容時:capacity爲原來的2倍,使用resize()擴容,需要將原數組中的鍵值對插入新的數組中。並重新計算桶下標
2.LinkedHashMap
- 繼承於HashMap,保證在遍歷map元素時,可以按照添加的順序實現遍歷
原因:在原有的HashMap底層結構基礎上,添加了一對指針head和tail,維護了一個雙向鏈表指向前一個和後一個
對於頻繁的遍歷操作,此類執行效率高於HashMap
-
LinkedHashMap 重要的是以下用於維護順序的函數,它們會在 put、get 等方法中調用。
void afterNodeAccess(Node<K,V> p) { //當一個節點被訪問時,如果 accessOrder 爲 true,則會將該節點移到鏈表尾部。也就是說指定爲 LRU 順序之後,在 每次訪問一個節點時,會將這個節點移到鏈表尾部,保證鏈表尾部是近訪問的節點,那麼鏈表首部就是近久未 使用的節點 } void afterNodeInsertion(boolean evict) { //在 put 等操作之後執行,當 removeEldestEntry() 方法返回 true 時會移除晚的節點,也就是鏈表首部節點 first //removeEldestEntry() 默認爲 false,如果需要讓它爲 true,需要繼承 LinkedHashMap 並且覆蓋這個方法的實現, 這在實現 LRU 的緩存中特別有用,通過移除近久未使用的節點,從而保證緩存空間足夠,並且緩存的數據都是 熱點數據。 }3.LRU緩存

3.Map中常用的方法:
添加:put(Object key,Object value)
刪除:remove(Object key)\clear()
修改:put(Object key,Objec value)
查詢:get(Object key)
長度:size()
遍歷:keySet()/values()/entrySet()
Set set=map.keySet();
Iterator iterator=set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
//2.Collection values();//遍歷所有的value
Collection collection=map.values();
for (Object obj : collection) {
System.out.println(obj);
}
//3.entrySet();//遍歷所有的鍵值對Entry
//--方式一:
Set set1=map.entrySet();
for (Object obj : set1) {
//entrySet集合中所有的元素都是entry
Map.Entry entry=(Map.Entry)obj;
System.out.println(entry.getKey()+"-->"+entry.getValue());
}
System.out.println("====方式二====");
//--方式二:
Set set2=map.keySet();
Iterator iterator1=set2.iterator();
while (iterator1.hasNext()) {
Object key=iterator1.next();
Object value=map.get(key);
System.out.println(key+"-->"+value);
}
4.TreeMap
保證按照添加的key-value對進行排序,實現排序遍歷,此時考慮key的自然排序、定製排序底層使用紅黑樹
向TreeMap中添加key-value,要求key必須是由同一個類創建的對象 因爲要按照key進行排序:自然排序(默認)、定製排序
//定製排序
@Test
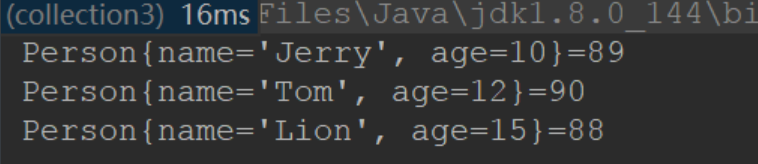
public void test1(){
Person p1 = new Person("Tom", 12);
Person p2 = new Person("Jerry", 10);
Person p3 = new Person("Lion", 15);
Person p4 = new Person("Jeff", 15);
Map map=new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof Person && o2 instanceof Person) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
return Integer.compare(p1.age,p2.age);
}
throw new RuntimeException("輸入的類型不匹配");
}
});
map.put(p1, 90);
map.put(p2, 89);
map.put(p3, 96);
map.put(p4, 88);
Set entry=map.entrySet();
Iterator iterator=entry.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
5.Hashtable
(1)古老的實現類,線程安全,效率低
(2)不能存儲null的key和value
6.Properties
常用來處理配置文件,key-value都是String類型
7.HashMap和Hashtable的區別:
(1)線程安全:
HashMap線程不安全效率高,Hashtable線程安全效率低
(2)存儲值:
HashMap:可以存儲null的key和value
Hashtable:不能存儲null的key和value
(3)元素次序:
HashMap 不能保證隨着時間的推移 Map 中的元素次序是不變的。
(4)HashMap 的迭代器是 fail-fast 迭代器。每次檢查一下結構有沒有變化,如果發生變化就拋出異常ConcurrentModificationException
結構發生變化是指添加或者刪除至少一個元素的所有操作,或 者是調整內部數組的大小,僅僅只是設置元素的值不算結構發生變化。
8.ConcurrentHashMap
-
ConcurrentHashMap 和 HashMap 實現上類似,主要的差別:ConcurrentHashMap 採用了分段鎖 (Segment),每個分段鎖維護着幾個桶(HashEntry),多個線程可以同時訪問不同分段鎖上的桶,從而使其併發 度更高(併發度就是 Segment 的個數)。
-
Segment 繼承自 ReentrantLock
static final class Segment<K,V> extends ReentrantLock implements Serializable { private static final long serialVersionUID = 2249069246763182397L; static final int MAX_SCAN_RETRIES = Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1; transient volatile HashEntry<K,V>[] table; transient int count; transient int modCount; transient int threshold; final float loadFactor; } final -
默認的併發級別爲 16,也就是說默認創建 16 個 Segment。
static final int DEFAULT_CONCURRENCY_LEVEL = 16;4.size操作
每個 Segment 維護了一個 count 變量來統計該 Segment 中的鍵值對個數。/** * The number of elements. Accessed only either within locks * or among other volatile reads that maintain visibility. */ transient int count;![java_15:Java容器]()
![java_15:Java容器]()


8.TreeMap/HashMap/LinkedHashMap/ConcurrentHashMap
